Best table structure for a tall table that needs to be pivoted
-
Hi Everyone,
I have a table with about 2 million distinct IDs and another table with about 7000 distinct codes plus a varchar(02) flag. I did a simple cross join to create a table with just over 14 billion records. To be clearer each distinct ID will have the same codes. I will update the varchar field accordingly but after that I have to pivot each ID with the 7000 codes into columns creating a giant matrix. I can't create indexes as the tempdb runs out of space but my bigger concern is the architecture of the columns I need to pivot. What is the best way to build this? I am thinking of creating 8 tables to cover the 7300 columns and joining by the distinct ids due to sql server's 1024 column limit per table. I hope I have provided enough detail. I have been developing a long time and never encountered this situation. Thanks.
-
The maximum number of columns in a query is 4096 so you couldn't query 7000 columns.
Would be good if you could go into a bit more detail about what is trying to be achieved?
-
Sorry, I thought I was clear.
I have to take each ID that has 7000+ records, update them (which I have to figure out) per ID, then pivot the results.
Each ID and code is distinct.
So the base table is from my cross join.
Each ID has its own set of the same values of 7000 repeated.
Under different business rules I will update columns for each ID.
Then I need to pivot on the ID value the 7000+ codes so the codes become columns.
The code values I don't have an issue with at the moment. I have to populate them.
I'm asking what is the best way to build this?
Example:
IDNumber CodeValue1 CodeValue2 CodeValue3
A1 1 2 1
A1 1 1 1
B1 NA 2 2
B 1 2 0
etc.
Does this help?
-
I think we know what you're asking to do.
But why would you need this in a cross-tabbed/pivoted format, especially given that you already have it in a normalized table?
How would you effectively use such data?
- Dolfandave wrote:
Example:
IDNumber CodeValue1 CodeValue2 CodeValue3
A1 1 2 1
A1 1 1 1
B1 NA 2 2
B 1 2 0
etc.
Does this help?
No, it doesn't, actually.
Using ID "A1" in your example, there are 2 rows with 2 different code values.
I would have expected a structure such as this:
ID Code
A1 1
A1 2
B1 NA
B1 2
B1 0
B1 1
Michael L John
If you assassinate a DBA, would you pull a trigger?
To properly post on a forum:
http://www.sqlservercentral.com/articles/61537/ -
Sorry, you're right.
This is what the "base table" I have looks like.

There will be over 2 million IDs and each ID will have the same exact set of "codes".
The values are what I will populate with various updates but after that I need to pivot it out.
Therefore I will wind up with ID A1 and 7000 columns with each code having its respective value.
Same w/ ID A2 and so forth.
Currently I have the table w/ the actual IDs and their repetitive codes and the Value field, so 3 columns with about 14 billion records.
This is a requirement per the customer.
Thanks
- Dolfandave wrote:
The values are what I will populate with various updates but after that I need to pivot it out.
.
.
.
This is a requirement per the customer.
To be honest, I'd tell the customer to put the crack pipe down.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
I mean I can on my last day and my last minute of my contract..........lol
- Dolfandave wrote:
I mean I can on my last day and my last minute of my contract..........lol
😀 I'm just curious why the customer says they need this? This could be done pretty easily as a CSV but as a table? How would they ever us it?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
It's for a clinical situation. I guess later it can be delivered as a .csv. For now my manager wants to review data and he wants to see it in SQL Server 2019. So you think the answer is to put 8 tables together w/ the ID as the key in each with the tables dividing the 7000+ columns? I am thinking this is the only way. One other problem is that I don't know much about partitioning nor do I believe I have permission to. Thanks.
- Dolfandave wrote:
It's for a clinical situation. I guess later it can be delivered as a .csv. For now my manager wants to review data and he wants to see it in SQL Server 2019. So you think the answer is to put 8 tables together w/ the ID as the key in each with the tables dividing the 7000+ columns? I am thinking this is the only way. One other problem is that I don't know much about partitioning nor do I believe I have permission to. Thanks.
You will be partitioning the table horizontally not vertically. SQL Server "partitioning" is for vertical partitioning.
The ID should be a clustered primary key.
If there are some codes that are queried a lot more than other's you could put all these on the first table as it will save joining tables for most queries.
Also try to minimise the space used by the table by selecting the smallest possible data type for each column.
If a lot of the codes are null on each row you could define the columns as SPARCE.
-
Ok thank you for sharing information.
-
The maximum row size in SQL Server is 8,060 bytes. If you get near this then you might come across performance problems with page splits when updating rows. For this reason it might be better to make sure that there is a margin before you reach this value so it might perform better if you split it into more tables.
- Dolfandave wrote:
Sorry, you're right.
This is what the "base table" I have looks like.
There will be over 2 million IDs and each ID will have the same exact set of "codes".
The values are what I will populate with various updates but after that I need to pivot it out.
Therefore I will wind up with ID A1 and 7000 columns with each code having its respective value.
Same w/ ID A2 and so forth.
Currently I have the table w/ the actual IDs and their repetitive codes and the Value field, so 3 columns with about 14 billion records.
This is a requirement per the customer.
Thanks
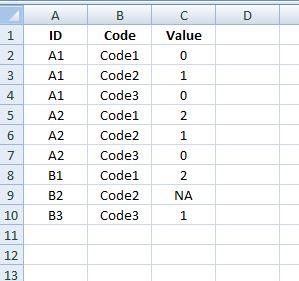
So, Column B would become the names of the 7000 columns... is that correct? And what datatype is column C right now?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Yes and the Value field is varchar(02), it needs to hold "1", "2", or "NA".
Viewing 15 posts - 1 through 15 (of 24 total)
You must be logged in to reply to this topic. Login to reply