How to change STRING_AGG to stuff xml to split feature value by pip?
-
I work on sql server 2019 . i can't write query below with stuff for xml .
so how to change STRING_AGG to stuff xml ?
query below take too much time so i need to try
with stuff for xml to reduce time cost .
query i try it
select
a.RecomendationId,
cast(STRING_AGG(cast(f1.FeatureValue as varchar(300)) ,'|') WITHIN GROUP (ORDER BY f1.FeatureId ASC) as varchar(300)) AS DiffFeatures
into ExtractReports.dbo.TechnologyOriginalFeaturesEqual
from extractreports.dbo.partsrecomendationActive a
inner join ExtractReports.dbo.TechnologyPlPartsFeaturValuesOrg f1 on f1.partid = a.OrignalPartId
inner join [Technology].Receipe Ft on ft.featureid = f1.featureid and ft.operatorid = 1
group by a.RecomendationIdddl tables structures
create table ExtractReports.dbo.TechnologyPlPartsFeaturValuesOrg
(
ID int identity(1,1),
PartId int,
FeatureID int,
FeatureName varchar(200),
FeatureValue varchar(200)
)
create table extractreports.dbo.partsrecomendationActive
(
RecomendationId int identity(1,1),
OrignalPartId int
)
CREATE TABLE [Technology].[Receipe](
[ReceipeID] [int] IDENTITY(1,1) NOT NULL,
[FeatureID] [int] NULL,
[OperatorID] [int] NULL,
PRIMARY KEY CLUSTERED
(
[ReceipeID] ASC
))expected result

-
How about providing an actual execution plan and asking for optimisation help?
I can't see how a FOR XML PATH solution (I assume that's what "stuff for xml" means) would be any faster ... it feels more like a backward step.
-
This appears to be a near duplicate post from the following...
Good luck in getting this OP to answer questions. I still have a few outstanding questions there but, to be honest, I'm a bit tired of trying to do the required dental work on an OP that won't open his mouth.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
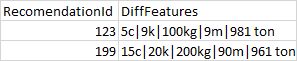
thanks much for support
i need only to use stuff instead of string aggreagte and heck time and performance
-
You don't understand... it's not the STRING_AGG that's the issue (it's a symptom of the real problem) and using XML to do the same thing isn't going to solve a thing for you.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
p.s. Ask the fellow that made the XML suggestion for the code. 😉
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Phil is 100% correct. Changing this to use FOR XML PATH syntax won't improve anything. If anything it will slow it down even more. I suspect that the bulk of the cost is coming from the sort operation in the STRING_AGG() function. And assuming that sort is necessary to meet requirements, that same sort will need to be present in the XML PATH version as well.
Without having any actual test data, I couldn't actually test this but it should be the correct syntax... (or at least very close)
SELECT
a.RecomendationId,
DiffFeatures = CONVERT(varchar(300), STUFF(d.DiffFeatures_list, 1, 1, ''))
INTO ExtractReports.dbo.TechnologyOriginalFeaturesEqual
FROM
extractreports.dbo.partsrecomendationActive a
CROSS APPLY ( SELECT (
SELECT
CONCAT(N'|', f1.FeatureValue)
FROM
extractreports.dbo.partsrecomendationActive pra
JOIN ExtractReports.dbo.TechnologyPlPartsFeaturValuesOrg f1
WHERE
a.RecomendationId = pra.RecomendationId
GROUP BY
pra.RecomendationId
ORDER BY
f1.FeatureId
FOR XML PATH(''), TYPE).value('./text()[1]', 'nvarchar(max)')
) d (DiffFeatures_list); - Jason A. Long wrote:
I suspect that the bulk of the cost is coming from the sort operation in the STRING_AGG() function. And assuming that sort is necessary to meet requirements, that same sort will need to be present in the XML PATH version as well.
That was one of the first things pointed out in the original thread. Some of us were aiming at doing a pre-aggregation of just 120K rows instead of more than 3 million.
The FOR XML PATH thing also has the issue of "entitization" and the simple fix for that (TYPE) makes it nearly twice as slow.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:Jason A. Long wrote:
I suspect that the bulk of the cost is coming from the sort operation in the STRING_AGG() function. And assuming that sort is necessary to meet requirements, that same sort will need to be present in the XML PATH version as well.
That was one of the first things pointed out in the original thread. Some of us were aiming at doing a pre-aggregation of just 120K rows instead of more than 3 million.
The FOR XML PATH thing also has the issue of "entitization" and the simple fix for that (TYPE) makes it nearly twice as slow.
Yea, having to use the "typed XML" is awful... but usually necessary unless you have absolute confidence that none of your text strings contain "illegal characters".
The better option, in my opinion, would be to keep the original STRING_AGG() function and simply omit the "WITHIN GROUP(ORDER BY f1.FeatureId ASC)" . A column named "FeatureId" sounds a little to arbitrary to be meaningful.
- Jason A. Long wrote:Jeff Moden wrote:Jason A. Long wrote:
I suspect that the bulk of the cost is coming from the sort operation in the STRING_AGG() function. And assuming that sort is necessary to meet requirements, that same sort will need to be present in the XML PATH version as well.
That was one of the first things pointed out in the original thread. Some of us were aiming at doing a pre-aggregation of just 120K rows instead of more than 3 million.
The FOR XML PATH thing also has the issue of "entitization" and the simple fix for that (TYPE) makes it nearly twice as slow.
Yea, having to use the "typed XML" is awful... but usually necessary unless you have absolute confidence that none of your text strings contain "illegal characters".
The better option, in my opinion, would be to keep the original STRING_AGG() function and simply omit the "WITHIN GROUP(ORDER BY f1.FeatureId ASC)" . A column named "FeatureId" sounds a little to arbitrary to be meaningful.
The "better" option is to check the previous post I pointed out and look at the counts I asked the Op to provide (which he finally did) and realize that "pre-aggregation" of 120 K rows into a temp table and then going to that to produce the desired output instead of trying to re-aggregate across millions of rows is actually the "better" option PROVIDED that is an option. I asked some additional question of the OP and they've gone ignored (again).
And then the OP splits the question onto another thread based on a knee-jerk reaction from an off the wall suggestion.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Here's another good one... the Op recently marked an answer as accepted on the other thread and said nothing on this one. Fun, eh?
It would likely be faster still if the pre-aggregation of the String_Agg were realized but whatever.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:Jason A. Long wrote:Jeff Moden wrote:Jason A. Long wrote:
I suspect that the bulk of the cost is coming from the sort operation in the STRING_AGG() function. And assuming that sort is necessary to meet requirements, that same sort will need to be present in the XML PATH version as well.
That was one of the first things pointed out in the original thread. Some of us were aiming at doing a pre-aggregation of just 120K rows instead of more than 3 million.
The FOR XML PATH thing also has the issue of "entitization" and the simple fix for that (TYPE) makes it nearly twice as slow.
Yea, having to use the "typed XML" is awful... but usually necessary unless you have absolute confidence that none of your text strings contain "illegal characters".
The better option, in my opinion, would be to keep the original STRING_AGG() function and simply omit the "WITHIN GROUP(ORDER BY f1.FeatureId ASC)" . A column named "FeatureId" sounds a little to arbitrary to be meaningful.
The "better" option is to check the previous post I pointed out and look at the counts I asked the Op to provide (which he finally did) and realize that "pre-aggregation" of 120 rows into a temp table and then going to that to produce the desired output instead of trying to re-aggregate across millions of rows is actually the "better" option PROVIDED that is an option. I asked some additional question of the OP and they've gone ignored (again).
And then the OP splits the question onto another thread based on a knee-jerk reaction from an off the wall suggestion.
After taking the time to read through the previous thread, 100% agree.
-
And, my apologies... I left left the "K' off the 120 above (just fixed in my original post above) but that's still a long way away from the millions of rows currently being aggregated.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
thanks for support
Viewing 14 posts - 1 through 14 (of 14 total)
You must be logged in to reply to this topic. Login to reply