

Reusable code in Terraform is key when automating database deployments of complex environments. As you add more resources, you must rethink the way you organize your scripts so you can manage them efficiently.
In my first article on this subject, I presented the basics about Terraform. Now we go a step further, using reusable modules in the deployment.
Expanding The Environment
This time we are going to implement a more robust infrastructure, including a longer list of resources:
- Resource group
- CosmosDB account and a database (SQL API)
- Databricks workspace
- SQL Server and SQL database
- Storage Account and a container
- Synapse Workspace, SQL Pool, and Data Lake GEN2 filesystem (used in the workspace)
I don't intend to create here a real-world environment. Let's say that, for any practical matters, the goal is to create a list of functional resources that can be enhanced later.
Instead of using the basic approach of creating a few scripts, our code is going to use Terraform modules, Modules will handle the syntax to deploy each type of resource, while our code will basically pass values to those modules.
When you have to deal with deploying new environments, handling new versions of AzureRM provider, or deploying several similar resources, modules we will let manage your code faster and easier.
Terraform Modules
We create a root script ("<yourMainScript>.tf") that points to a library of modules. This root script selects which resources to deploy, while each module defines which parameters are required to deploy a given resource. We set the values for those parameters in the root scripts ("variables.tf" or "<myName>.auto.tfvars), so we can reuse the library as it is for any deployment we need.
Check image below to see the syntax of the root script.
 Code in root script.
Code in root script.We can create our own modules and point to local folders where they are stored. Or we can reuse modules available in Terraform registry. A quick look will show you the existing modules for provider AzureRM (link). In fact, there are literally hundreds of modules available.
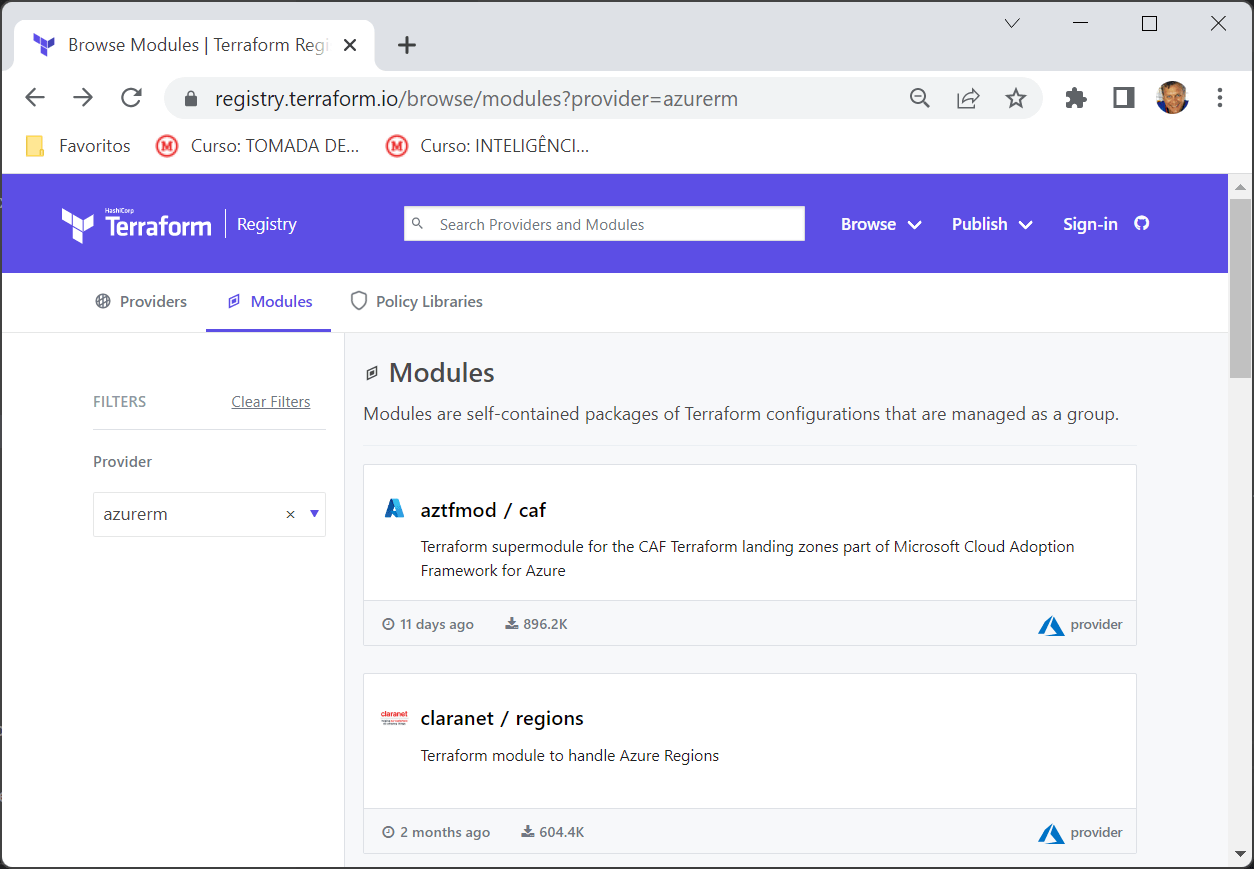 Modules available in Terraform registriy for AzureRM resources
Modules available in Terraform registriy for AzureRM resourcesAlthough it is very convenient to link your scripts to Terraform registry and use existing modules, I like the idea of creating my own library. This gives you control over modules versioning, besides allowing you to customize modules to reflect the policies and standards used within your organization.
Warming Up
Let's get started with a simple example: deploying a single resource group, but using a module to execute the task. I structured this code with 05 files, as you can see in the below:
Time to check to check those scripts a little closer.
Our First Module
As you can see, within module ResourceGroup, there are two files, which define the variables that will be received from root file and the way to apply those variables to deploy the resource. Check the following code:
# File 1 :
# ./modules/ResourceGroup/variables.tf
variable "rgname" {
type = string
description = "resource group name"
}
variable "location" {
type = string
description = "code related to Azure Region"
}
variable "tags" {
type = map(string)
description = "tags related to project"
}
# File 2
# ./modules/ResourceGroup/main.tf
resource "azurerm_resource_group" "ResourceGroup" {
name = var.rgname
location = var.location
tags = var.tags
}Invoking the Module
In the root folder, there three files. One set variables and corresponding values, the other do the necessary transformations and the last one finally invoke the module and pass values for deployment.
# File 1
# ./variables.tf ==> define all variables to be handled and their default values
variable "company" {
type = string
description = "company name"
default = "WideWorldImporters"
}
variable "project" {
type = string
description = "project name"
default = "terraforming"
}
variable "rgName" {
type = string
description = "preffix to resource group name"
default = "SSC"
}
...................
# File 2
# ./locals.tf ==> define transformations necessary to those values
#Random ID for unique naming
resource "random_integer" "rand" {
min = 000001
max = 999999
}
locals {
randomSuffix = "${format("%06s", random_integer.rand.result)}"
rgname = "${var.rgPreffix}${var.rgName}-${local.randomSuffix}"
tag = {
company = var.company
project = "${var.company}-${var.project}"
costcenter = var.costcenter
environment = var.environment
}
}
# File 3
# ./root.tf ==> pass the results to modules
terraform {
required_providers {
azurerm = {
source = "hashicorp/azurerm"
version = "~>3.0"
##any azurerm version, from 3.0.0 or above
}
}
}
provider "azurerm" {
features {}
}
module "ResourceGroup" {
source = "./modules/ResourceGroup"
rgname = local.rgname
location = var.location
tags = local.tag
}
Please check section RESOURCES to see this code (folder "version2.1").
Checking Results
Notice that all variables manipulated in the root folder must be declared in the file "variables.tf". This means you can use the names you like to pass values to parameters inside modules. Likewise, all variables used in the module must be declared in its corresponding "variables.tf" file.
In this example, I omitted the file "outputs.tf" in the module for simplicity. But, in real life, it is highly recommended to define outputs for every module. This is the only way to access information about deployed resources, like their IDs, for instance (I will show you this ahead).
After running these scripts, our new resource group is ready to go, following naming conventions, specific region and proper tags used in our organization.
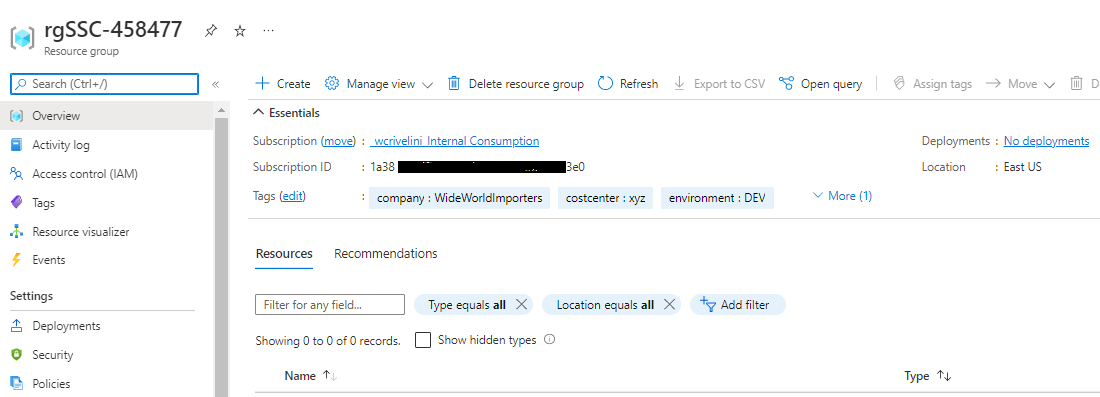
Putting It All Together
Now we can prepare the scripts for the remaining modules. Steps are the following:
- Create "main.tf" file in each module, write the resource definition for the resource according to AzureRM documentation. Make sure to add all required parameters and any optional one that you need. Parameters names must follow documentation. You can name variables as you want, as long as you keep the same names defined in the local "variables.tf".
- In the "variables.tf" file in each module, write the definitions and types of each variable. Never use default values.
- The "outputs.tf" file in each module specify the generated parameters that should be exported in the end of deployment. This will make those values available for future use within you code.
- In root folder, edit your main tf file and declare all resources you need using the corresponding module. Inform each parameter and the source of the values used in the deployment. Keep in mind that variable names will follow definition from variables file in the same folder ("./variables.tf"), but the parameter names will follow the definition the file stored in the module ("./modules/<myModule>/variables.tf").
- In the "variables.tf" file in root folder, declare all variables used in the "root.tf" and "locals.tf" files. Again, don't use default values.
- For convenience, create a "z_<resourcename>.auto.tfvars" file for each resource to be deployed and declare the desired values. The extension "auto.tfvars" tells Terraform to automatically load these files during deployment. I added a preffix "z_" to those file names to order them in the folder. Having separate tfvar files will make it easier for you to manage values passed to each module when you reuse the code in several deployments.
You may find useful to repeat the separate file approach presented in step 6 again for the "main.tf" and "variables.tf" in root folder. This might let your even more manageable.
Closer Look
This implementation make use of 12 modules and TFVAR files, plus an extra file with values related to tags (as this is a parameter shared with several modules). The entire is available in section RESOURCES (folder "version2.2").
Although the logic of using modules is straightforward, there are always a few catches. Let's discuss them.
Naming Conventions
Azure resources use different conventions and this is something that demands attention. Most of those resource support upper and lower case letters, numbers and dashes. But there are several exceptions. Storage accounts, for instance, don't accept upper cases and data lake stores accept only lower cases and numbers.
All in all, it is a good idea to check the naming rules before writing your code.
On the other hand, Terraform standards are also tricky. Databricks SKU default value is written with lower cases ("standard"), but Data Lake tier use start case ("Standard"). As Terraform is case sensitive, you must check the documentation of each resource.
Dependencies
By default, Terraform deploys objects in parallel (default is 10 resources at a time). This is great to reduce deployment overall time, but we must remember most resources require the existence of others.
We can easily handle this by adding the DEPENDS_ON clause to each resource definition. The syntax is:
module "<myModule>" {
......
depends_on = [module.<parentResource>]
......
}You may have noticed dependencies are listed within brackets. This means we can create a list of parent objects that have to be deployed before creating the new resource.
Reusing Outputs
Resources usually define a parent resource in their list of parameters. But sometimes the parameter that creates their bond receives value only after the parent resource is already deployed. This is the case of resource ID. Consider we want to create a Synapse SQL Pool. One of the parameters to inform here is Synapse Workspace ID, the parent resource of the SQL Pool.
Creating "outputs.tf" files for every module is important just because they let us handle this kind of situation. In the example mentioned above, the module that handles Synapse Workspace define an output ID. In its turn, when defining parameters to create the SQL Pool, we simply reference this output value, as shown below.
# IN ./modules/SynapseWorkspace/outputs.tf
output "id" {
description = "The id of the resource created."
value = azurerm_synapse_workspace.synapsewokspace.id
}
# IN ./root.tf
module "synapsesqlpool" {
source = "./modules/SynapseSQLPool"
synsqlpool_name = var.synsqlpool_name
synsqlpool_wrkspcid = module.synapseworkspace.id ### <===============
synsqlpool_sku = var.synsqlpool_sku
synsqlpool_mode = var.synsqlpool_mode
depends_on = [module.synapseworkspace]
}
Conclusion
Reusable code in Terraform is something you must add to your personal toolkit if you ever have to work with automated database deployment.
Terraform is simple to use and easily expandable, but code rapidly grows to thousands of lines. By then end of the day, modularization is a great approach to improve the manageability of your code.
In the next article, the subject will be the use o workspaces and pipelines.
