Creating index for a very huge table
-
Hello, I would want to get some opinion on creating indexes on a very large table.
My developer recently execute an index creation job and the job run for more than 30hrs until it ran out of transaction log space thus got terminated.
I check the size of the intended table and it's super huge! About 13bil of rows approx 400GB.
Is there any better way to improve it? I inform the developer to perhaps housekeep the table since it contains data more than 10 years old then only create the indexes.
-
- pre-extend the transaction log file to be able to cope with the extra create-index load.
- multiple files in the filegroup where the index is being created.
- multiple disks / luns / ssd ?
Johan
Learn to play, play to learn !Dont drive faster than your guardian angel can fly ...
but keeping both feet on the ground wont get you anywhere :w00t:- How to post Performance Problems
- How to post data and code to get the best help- How to prevent a sore throat after hours of presenting ppt
press F1 for solution, press shift+F1 for urgent solution 😀
Who am I ? Sometimes this is me but most of the time this is me
- JasonO wrote:
My developer recently execute an index creation job...
Just exactly what does that "job" consist of?
And, yes... there's a way to do this (I do it all the time) but you've not provided nearly enough information. We need the CREATE TABLE statement, at least the CREATE statement for the Clustered Index, and we need to know what the current Recovery Model is and whether or not it can be at least temporarily changed.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
and information about how you are running the index creation - within a transaction, multiple index being created or just one, online or off line, sort in temp db or not - better yet the full create index statement would be ideal.
and... server spec (cores/ram)
-
With a table of that size it might be better to look at partitioning the table.
- Jonathan AC Roberts wrote:
With a table of that size it might be better to look at partitioning the table.
Heh... yeah... but you'd first have to rebuild the index to partition it. 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Here's the create index statement which the developers run.
Create NONCLUSTERED INDEX [IX_TileID_Include] ON [DB01].[dbo].[table1] ([Tile_ID]) INCLUDE ([Die_ID],[GGI_ID],[GGI_X],[GGI_Y],[DS1_ID],[DS1_X],[DS1_Y]) with (DATA_COMPRESSION = PAGE, ONLINE=ON)
As for the server spec, it's a VM server running on Windows server 2016 with 18 core proc & 64GB of RAM.
Initially the table was partitioned by date column, but no new partition was created after 2011 while the oldest partition is from 2009. So the current partition is running from 2011 till current.
For the create clustered index statement do refer below.
CREATE UNIQUE CLUSTERED INDEX [IX_Die_ID] ON [dbo].[table1]
(
[Die_ID] ASC,
[GGI_Date] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
-
If you ran out of log file space on that NCI build, you're simply going to need more disk space for the log file. I also suspect you may have dipped into the swapfile because of the amount of time it took. You should consider having at least 1/4TB on that box. If you're running only on the Standard Edition, you really need to get it out to 128GB to support this type of thing.
My other recommendation was going to be to NOT use ONLINE = ON because that's fully logged and horribly slow and I was also going to suggest doing a log file backup before you started then slipping into the Bulk Logged Recovery Model so the system can take advantage of minimal logging (which is about twice as fast), and then when done, shift back to full and do a DIF backup. Of this this will save some serious room on the log file.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
that ONLINE=ON is whats causing all that growth and elapsed time.
you should also add sort_in_tempdb = on.
and... the DDL you supplied does not include the filegroup it is being created on - so if the above is an exact copy of your create statements then the indexes are not partitioned - not a good thing if the underlying table is still partitioned.
your clustered index is also missing compression clause - might it be that your settings to generate scripts is missing the options required.
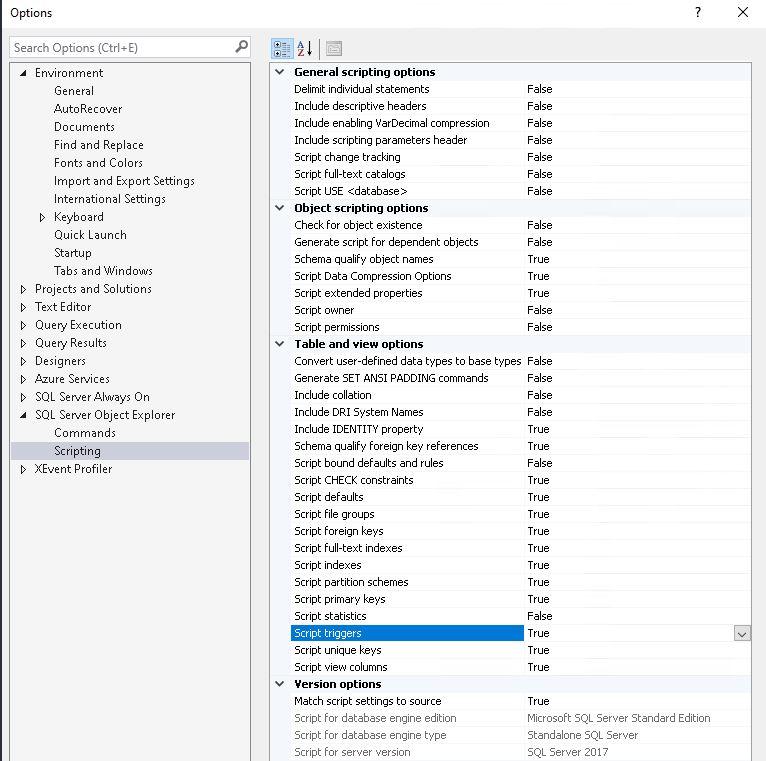
Script settings should normally be as follows.

assuming you do need/want the table to stay partitioned it would be advisable to create the missing partitions and ensure all indexes on the table are partitioned (or the benefit of using partition switch to clear down older partitions is removed... and this is one of the main reasons to use partitioning)
Viewing 9 posts - 1 through 9 (of 9 total)
You must be logged in to reply to this topic. Login to reply