Handle TSQL Session exections terminated by users
-
Ahoi,
how does one deal with the following situation.
Theres a long running delete which is split into smaller batches.
DECLARE @COUNTER INT = 5
WHILE @COUNTER >= 0
BEGIN
BEGIN TRY
BEGIN TRANSACTION
select 'Dummy, in reality here an incremental batch delete is running'
SET @COUNTER = @COUNTER - 1
COMMIT TRANSACTION
END TRY
BEGIN CATCH
--Run a ROLLBACK/COMMIT/... whenever cancalled manually
--How do i get to execute another codeblock even if cancalled
select 'COMMIT/ROLLBACK Transaction'
END CATCH
ENDEach execution is seperated by BEGIN TRAN ..... COMMIT TRAN, so in case of a rollback it doesnt rollback the entire delete
What i trying to figure out now though is, how do you run the COMMIT TRANSACTION when the execution is terminated by the user or me for example by stopping the execution in SSMS half way through one of the deletes.
If the execution is stopped during the execution and therefore after the BEGIN TRANSACTION, the @@TRANCOUNT is != 0.
WHILE @@TRANCOUNT != 0
BEGIN
ROLLBACK TRANSACTION
ENDThe code above theoritcally works when reexecuting the same thing again and picks up where it left off, but what if that does not happen and therefore the above code is not run. The transaction remains open because there was no commit/rollback.
Is it possible to execute a CATCH when the query is cancelled manually, which is not caught since it doesnt seem to be an error.
I want to be the very best
https://www.sqlservercentral.com/articles/forum-etiquette-how-to-post-datacode-on-a-forum-to-get-the-best-help
Like no one ever was -
I don't think you don't need an explicit COMMIT and ROLLBACK. In SQL Server, by default each SQL statement that modifies data will be in its own transaction.
Specify "SET XACT_ABORT ON" at the start of the script to help ensure that SQL will automatically rollback the current DELETE if some type of failure occurs.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Unless you are performing multiple operations inside the loop - then there is no reason to begin/commit a transaction and really no reason to implement a try/catch. Now - if you are worried that a delete will fail, but then the 'next' iteration of that delete could be successful then a try/catch could be used. In that scenario you would then inspect the state of the transaction and the error - and then either throw the error or ignore it.
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs - ktflash wrote:
Ahoi,
Theres a long running delete which is split into smaller batches.
how does one deal with the following situation.
The answer is likely going to be found in the code that does the actual delete. With that, the way one deals with such an issue is to start with rule number 1 for troubleshooting... "Must look eye". 😀 Since you're a regular on this forum, you know what else is coming... 😉
Please post the entire code for the delete loop , the CREATE TABLE statement for the table you're deleting from, and all indexes, FKs, and triggers associated with the table as well as any indexed views that may be present.
If you can, please post the ACTUAL execution plan for at least 3 iterations of the loop. Not a graphic of the plan... the actual plan so we can check properties of the nodes, etc. If you don't know how to do that type of thing, see the article at the second link in my signature line below.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
[/quote]
Please post the entire code for the delete loop , the CREATE TABLE statement for the table you're deleting from, and all indexes, FKs, and triggers associated with the table as well as any indexed views that may be present.
[/quote]
--Table + Index
/****** Object: Table [prodmd01].[EVENT] Script Date: 22.04.2022 07:52:31 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [prodmd01].[EVENT](
[UUID_E] [nchar](36) NOT NULL,
[EVENT_NAME_E] [nvarchar](256) NOT NULL,
[EVENT_LISTENER_NAME_E] [nvarchar](256) NOT NULL,
[EVENT_STATUS_E] [nvarchar](256) NOT NULL,
[CREATION_DATE_E] [bigint] NOT NULL,
[MODIFICATION_DATE_E] [bigint] NOT NULL,
[OBJECT_ID_E] [nchar](36) NULL,
[OBJECT_VERSION_E] [nvarchar](15) NULL,
[OBJECT_MOD_DATE_E] [bigint] NULL,
[CONTENT_REPOSITORY_ID_E] [nchar](36) NULL,
[OBJECT_INSTANCE_DATE_E] [bigint] NULL,
[RETRY_COUNTER] [int] NULL,
[EVENT_MESSAGE_E] [nvarchar](256) NULL,
[OBJECT_MODIFICATOR_E] [nchar](36) NULL,
[EVENT_ADD_INFO_E] [nvarchar](512) NULL,
PRIMARY KEY CLUSTERED
(
[UUID_E] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [prodmd01].[EVENT] WITH CHECK ADD FOREIGN KEY([EVENT_NAME_E], [EVENT_LISTENER_NAME_E])
REFERENCES [prodmd01].[EVENT_LISTENER] ([EVENT_NAME_L], [LISTENER_NAME_L])
ON DELETE CASCADE
GO
USE [prodmd01]
GO
SET ANSI_PADDING ON
GO
/****** Object: Index [PK__EVENT__556FC09B9CFE71DE] Script Date: 22.04.2022 07:53:22 ******/
ALTER TABLE [prodmd01].[EVENT] ADD PRIMARY KEY CLUSTERED
(
[UUID_E] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
GO
/****** Object: Index [EVENT_CD_IDX] Script Date: 22.04.2022 07:53:23 ******/
CREATE NONCLUSTERED INDEX [EVENT_CD_IDX] ON [prodmd01].[EVENT]
(
[CREATION_DATE_E] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
GO
SET ANSI_PADDING ON
GO
/****** Object: Index [EVENT_INDEX] Script Date: 22.04.2022 07:53:23 ******/
CREATE NONCLUSTERED INDEX [EVENT_INDEX] ON [prodmd01].[EVENT]
(
[EVENT_NAME_E] ASC,
[EVENT_LISTENER_NAME_E] ASC,
[EVENT_STATUS_E] ASC,
[CREATION_DATE_E] ASC,
[CONTENT_REPOSITORY_ID_E] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
GO
SET ANSI_PADDING ON
GO
/****** Object: Index [EVENT_INDEX test2] Script Date: 22.04.2022 07:53:24 ******/
CREATE NONCLUSTERED INDEX [EVENT_INDEX test2] ON [prodmd01].[EVENT]
(
[EVENT_NAME_E] ASC,
[EVENT_LISTENER_NAME_E] ASC,
[EVENT_STATUS_E] ASC,
[CREATION_DATE_E] ASC,
[CONTENT_REPOSITORY_ID_E] ASC
)
INCLUDE([MODIFICATION_DATE_E],[OBJECT_ID_E],[OBJECT_VERSION_E],[OBJECT_INSTANCE_DATE_E],[OBJECT_MOD_DATE_E],[RETRY_COUNTER],[EVENT_MESSAGE_E],[OBJECT_MODIFICATOR_E],[EVENT_ADD_INFO_E]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
GO
SET ANSI_PADDING ON
GO
/****** Object: Index [EVENT_SM_IDX] Script Date: 22.04.2022 07:53:25 ******/
CREATE NONCLUSTERED INDEX [EVENT_SM_IDX] ON [prodmd01].[EVENT]
(
[EVENT_STATUS_E] ASC,
[MODIFICATION_DATE_E] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
GO--Delete im planning to run to delete all rows (18 of 25 million) that match the where condition
--Im planning to delete this in subsets of top X datasets each with a commit until theres no more data
--Number of data to delete for loop
DECLARE @COUNTER INT = (
select count(*)
from [prodmd01].[EVENT]
WHERE CONTENT_REPOSITORY_ID_E = 'acf5915e-0f08-4ab8-845f-6a37b44a59df'
AND EVENT_LISTENER_NAME_E = 'FULLTEXT_SERVICE'
)
DECLARE @DELETE_SIZE int = 10000
--Run Loop until all data is deleted
WHILE @COUNTER >= 0
BEGIN
BEGIN TRY
--Run everything within BEGIN ... COMMIT Transaction, in case a cancellation it doesnt ROLLBACK the WHOLE DELETE
BEGIN TRANSACTION
--Delete top @DELETE_SIZE
delete top (@DELETE_SIZE)
from [prodmd01].[EVENT] --EVENTX --> X entfernen, nicht daus ausversehen ausgeführt wird
WHERE CONTENT_REPOSITORY_ID_E = 'acf5915e-0f08-4ab8-845f-6a37b44a59df'
AND EVENT_LISTENER_NAME_E = 'FULLTEXT_SERVICE'
--For each increment reduce COUNTER
SET @COUNTER = @COUNTER - @DELETE_SIZE
--Print current counter: ERGEBNISSE IN TEXT ANZEIGEN BUTTON IN SSMS anklicken um anzuzeigen
RAISERROR('%s:%d', 0, 1, @STRING_TEXT, @COUNTER) WITH NOWAIT;
COMMIT TRANSACTION
END TRY
BEGIN CATCH
COMMIT TRANSACTION
PRINT 'Transaction has been commited after Termination?'
END CATCH
ENDAlso i read about backup relevant data, truncate original table and resinert the data instead of deleting the irrelevant data
--Drop temp storing table if already exists
--Not using an actual temp table in case something goes wrong and the temp table + data is gone
IF OBJECT_ID('prodmd01.EVENT_Temp', 'U') IS NOT NULL
DROP TABLE prodmd01.[EVENT_Temp];
--Backup the relevant Data
SELECT [UUID_E]
,[EVENT_NAME_E]
,[EVENT_LISTENER_NAME_E]
,[EVENT_STATUS_E]
,[CREATION_DATE_E]
,[MODIFICATION_DATE_E]
,[OBJECT_ID_E]
,[OBJECT_VERSION_E]
,[OBJECT_MOD_DATE_E]
,[CONTENT_REPOSITORY_ID_E]
,[OBJECT_INSTANCE_DATE_E]
,[RETRY_COUNTER]
,[EVENT_MESSAGE_E]
,[OBJECT_MODIFICATOR_E]
,[EVENT_ADD_INFO_E]
into [prodmd01].[EVENT_Temp]
FROM [prodmd01].[EVENT]
WHERE NOT (CONTENT_REPOSITORY_ID_E = 'acf5915e-0f08-4ab8-845f-6a37b44a59df'
AND EVENT_LISTENER_NAME_E = 'FULLTEXT_SERVICE')
--Sollte 0 sein
select count(*)
from [prodmd01].[EVENT_Temp]
WHERE CONTENT_REPOSITORY_ID_E = 'acf5915e-0f08-4ab8-845f-6a37b44a59df'
AND EVENT_LISTENER_NAME_E = 'FULLTEXT_SERVICE'
--Truncate Original Table and reinsert relevant Data which was backed up
truncate table [prodmd01].[EVENT]
insert into [prodmd01].[EVENT]
SELECT [UUID_E]
,[EVENT_NAME_E]
,[EVENT_LISTENER_NAME_E]
,[EVENT_STATUS_E]
,[CREATION_DATE_E]
,[MODIFICATION_DATE_E]
,[OBJECT_ID_E]
,[OBJECT_VERSION_E]
,[OBJECT_MOD_DATE_E]
,[CONTENT_REPOSITORY_ID_E]
,[OBJECT_INSTANCE_DATE_E]
,[RETRY_COUNTER]
,[EVENT_MESSAGE_E]
,[OBJECT_MODIFICATOR_E]
,[EVENT_ADD_INFO_E]
from [prodmd01].[EVENT_Temp]
--Drop table after execution
IF OBJECT_ID('prodmd01.EVENT_Temp', 'U') IS NOT NULL
DROP TABLE prodmd01.[EVENT_Temp];I want to be the very best
https://www.sqlservercentral.com/articles/forum-etiquette-how-to-post-datacode-on-a-forum-to-get-the-best-help
Like no one ever was -
Thanks. That was awesome. Told me a lot.
Random GUIDs are GOOD... But not like THAT!
First and as a bit of a sidebar, you good folks have done yourselves a pretty nasty disservice by converting perfectly good GUIDs of only 16 bytes to NVARCHAR(36), which takes up 36*2+2 or a monstrous 74 bytes for the PK and that 74 bytes will be reflected in every Non-Clustered Index behind the scenes making all of them rather insanely huge.
I find that most people change GUIDs to character based datatypes because the want them to be sorted for "readability" and they suffer greatly for that minor convenience.
1 Million GUIDs = (16 * 1,000,000) or 16 Million bytes of storage.
1 Million NVARCHAR(36) = ((36*2+2) * 1,000,000) or 74 Million bytes of storage!!!And remember that if that column is the key for the (row-store) Clustered Index, ALL of your (row-store) non-clustered Indexes will also suffer the 74 byte wide column instead of just 16 bytes.
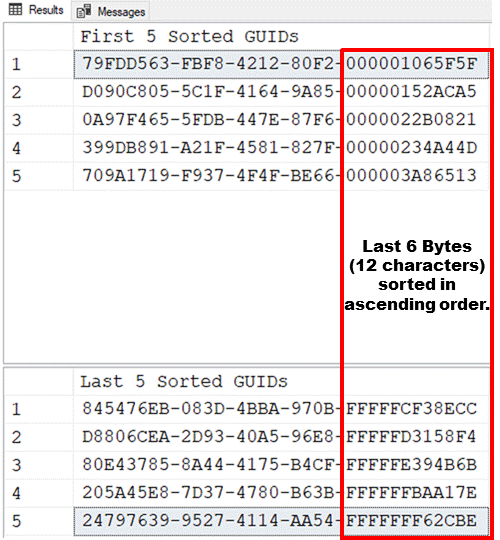
What a lot of people don't know is that GUIDs ARE sorted quite nicely... you just have to learn how to read them in sorted order.
Here are the first 5 and the last 5 rows of a regular NEWID()-based random GUID. Note the sort order... it's just not that difficult to read if you know what to look for.

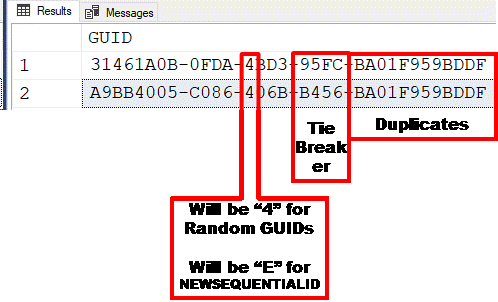
Despite the fact that 6 bytes can hold 256^6 = 281,474,976,710,656 or more than 281 TRILLION different values, you'll get the occasion duplicate (usually no more than 1 pair of dupes in 28 Million rows and "only" about 1,732 pairs of dupes in a Billion rows). Heh... if you're manually scanning that many rows, you have a different kind of a problem but, what does it look like if you DO have dupes in those 6 bytes? The answer is to look at that next 2 bytes (4 characters) to the left for the sorted tie-breaker.
Here are two rows from my 1 Billion row test that have duplicate right six bytes...
If you end up with dupes in the right 6 bytes, use the next two bytes to the left as the tie breaker... and, they will also be sorted (Sidebar... the left-most character will ALWAYS be 8, 9, A, or B, the reasons for which are too long to go into here).
As another sidebar, you can always tell what kind of a GUID you have (if they follow the standards) by looking at the character position I have identified above. Random GUIDs (based on the NEWID() function) are "Type 4" and GUIDs based on the NEWSEQUENTIALID() function are "Type E". "Type E" GUIDs will also contain one of the MAC Addresses in the right-6 bytes and are sorted left to right overall.
So, the bottom line is, Random GUIDs ARE, in fact, sortable and readable for sort order. You just have to look at at the right most 6 bytes (12 characters) to see the sorted order and you don't need the huge amount of waste caused by converting them to VARCHAR(36) or {gasp!} NVARCHAR(36).
Converting GUIDs makes them more prone to logical fragmentation
No... you're not reading that wrong. If you use NEWSEQUENTIALID() or you've converted Random GUIDs to VARCHAR() or NVARCHAR() to make them sortable, you are destroying the natural ability of Random GUIDs to PREVENT fragmentation, especially once you get millions of rows, like you have even after retaining "only" 7 Million rows.
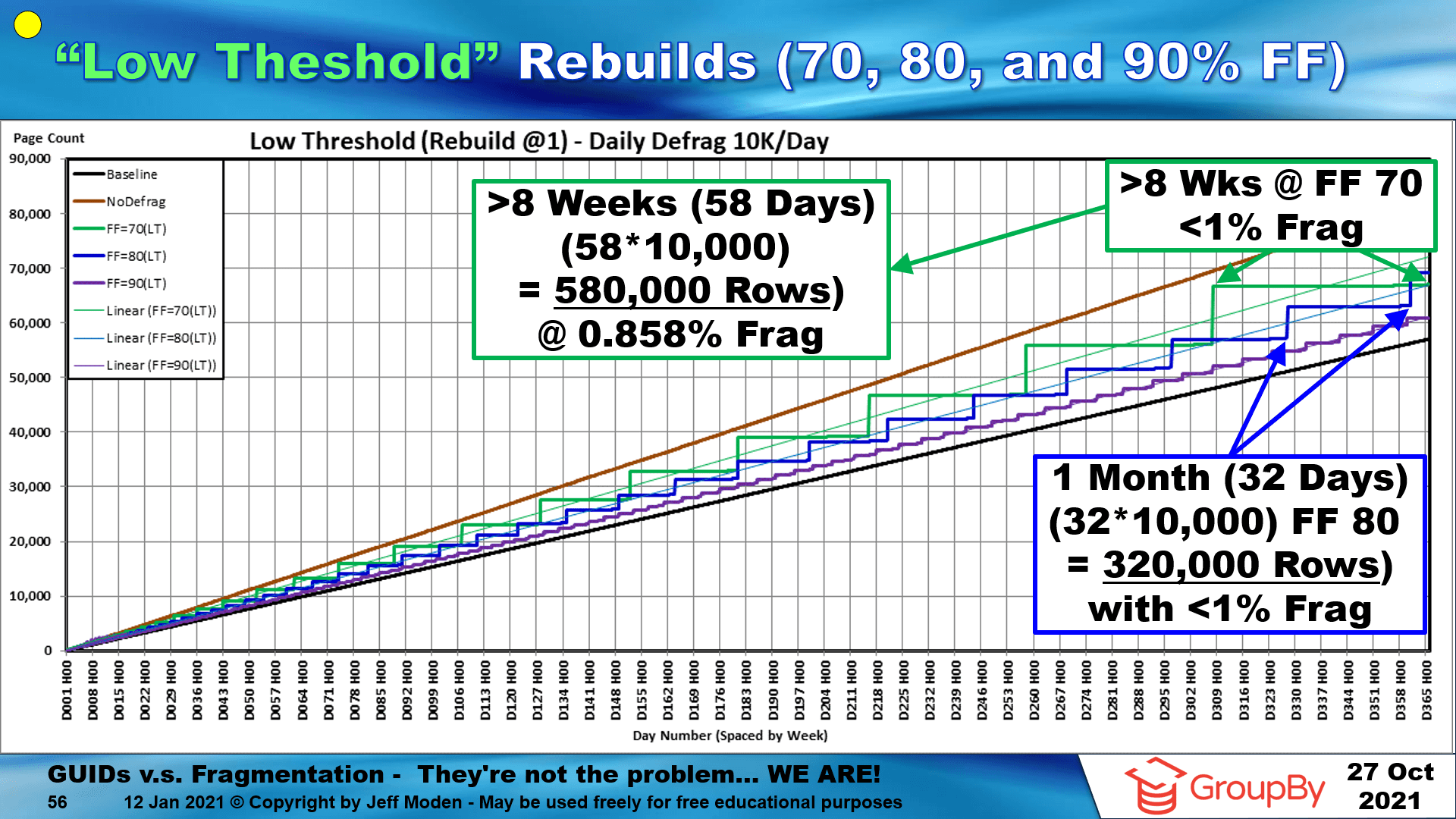
Here's the fragmentation chart for inserting 10,000 Random GUIDs per day over the first year of life... the "flats" are where virtually no page splits occurred and never got over 1% logical fragmentation. Once they barely did, they were immediately REBUILT (that's where the vertical lines occur to allocate more space above the Fill Factor). The key is to NEVER EVER use REORGANIZE on Random GUIDs, even if you have the standard edition! Just don't do it! It's better to NOT do any index maintenance than it is to do it wrong and REORGANIZE is the wrong way... it actually sets the index up for massive page splits all day every day. For more detail on all of that, see the 'tube" at the following link...
https://www.youtube.com/watch?v=rvZwMNJxqVo
To be sure, the words "Daily Defrag" in the chart title do NOT mean that the indexes were rebuilt every day. It just means that they were CHECKED for fragmentation every day. The indexes were only rebuilt when they went OVER 1% logical fragmentation and those events are (again) marked by the vertical lines in the "steps" formed in each line when additional page space was allocated to allow for free space above the Fill Factor.
The really cool parts about the "Low Threshold" method for maintaining Random GUID indexes are...
- A similar pattern with similar amounts of time between REBUILDs will exist no matter how many average rows per day you insert.
- The larger the table gets in relation to the average insert rate, the longer the time it will be between rebuilds.
- Because the "Low Threshold" method actually DOES clear the space above the Fill Factor (REORGANIZE does NOT), it also makes Random GUIDs the very epitome of what most people think an index should behave as... if you lower the Fill Factor, it prevents more page splits AND that includes page splits caused by "ExpAnsive" updates, which "ever-increasing" indexes cannot do in the "hot spot" (resulting in permanently and almost instantly fragmented indexes).
Back to the subject of Deletions
In your latest post above, you recognized the "Copy, Truncate, Copy Back" method and that's much better than the Delete method. Even if you're in the SIMPLE recovery model, Delete cannot be made to be minimally logged. It will always beat the crap out of your log file especially since you didn't disable the Non-Clustered Indexes first.
But... there's an even better method that's twice as fast as the "Copy, Truncate, Copy Back" method because it only has to copy the data you want to keep... once".
AND, if you can temporarily slip into the BULK LOGGED Recovery Model, it'll be twice as fast as that, thanks to "Minimal Logging".
The 3rd Super Fast Method
This method also has the advantage of, except for the name of the table, leaving the original table unscathed so you can verify that everything you wanted to happen actually did happen and happened CORRECTLY.
Here are the steps that I use for any table of any decent size even if I want to delete as little as 10 to 20% of the table. My recommendation is to write the script to do it all and test it in a non-prod environment to make sure it works without unforeseen "gotchas".
- Do a little planning. Although you're going to leave indexes and FKs alone on the original table, you should have a script to create them on at the ready. The cool part about this is that you don't need to change the name of the table or anything else. The only exception to that is if you have named constraints (including the PK). Constraints are objects that must be uniquely named within the database. Those will need to be changed if named. If not named and the system named them (like what happens when many people create a PK in the table definition), just allow the same thing to happen on the new table.
- Create the new table WITH the Clustered Index or Clustered PK in place. Like the code generated by the GUI in SSMS for such things, make the table name exactly the same as the original but include "tmp" as a prefix on the name. Note the ONLY the Clustered Index should be added and it really should be added. DO NOT add FK's, Non-Clustered Indexes, etc, to the table at this time. It'll just slow things down and can prevent "Minimal Logging" even though the MS documentation says otherwise (personal experience there).SPECIAL NOTE: IF you ever intend to add a FILL FACTOR (and you should for a GUID based Clustered Index, NOW is the time to do that because the INSERT we're getting ready to do actually WILL follow the Fill Factor. For the final size of your table table (7 million rows), I recommend an 81% Fill Factor. Along with the "Low Threshold" rebuilds you should do for index maintenance, that will make it so you can go literally for months with <1% fragmentation with your Random GUID based CI.See the following link for more information on how "Some T-SQL INSERTs DO Follow the Fill Factor! "
https://www.sqlservercentral.com/articles/some-t-sql-inserts-do-follow-the-fill-factor-sql-oolie
- If your database is in the FULL Recovery Model and you don't have anything setup where changing the Recovery Model from FULL would cause you pain, change the Recovery Model so we can use "Minimal Logging". Do this by first taking at least a transaction log file backup of the original table and then set the Recovery Model to BULK LOGGED.If you're already in either the BULK LOGGED or SIMPLE Recovery Models, you can skip this step except for taking a transaction log file backup. If any log file backup has even 1 minimally logged byte save in it, you either have to use the entire file for a restore or stop before it. You can't restore to a point-in-time to the middle of such a log file.If you're in the FULL Recovery Model and you have something active (log shipping, AG, whatever), then skip this step, as well. It will mean you can't take advantage of "Minimal Logging" but it will still be MUCH quicker and easier on the transaction log file than doing DELETEs of any type.
- Your table does NOT contain an IDENTITY column. That's a real "Martha Stewart Moment" that will save us a fair bit of anguish that I don't need to include in this 4th or any of the following steps.
- Use code similar to the following to do the copy of the data you want to KEEP. You could add a little speed and simplicity to this by using an INSERT without a column list and by using SELECT * as a source because were not using an IDENTITY column but I recommend you use a full column list both for the INSERT and the SELECT until you've had lots of practice at this type of thing and you've "super-studied" everything about the original table.
INSERT INTO dbo.tmpEvent WITH(TABLOCK) --WITH(TABLOCK) is critical for Minimal Logging and other things.
(UUID_E, EVENT_NAME_E, EVENT_LISTENER_NAME_E, EVENT_STATUS_E, CREATION_DATE_E, MODIFICATION_DATE_E, OBJECT_ID_E, OBJECT_VERSION_E, OBJECT_MOD_DATE_E, CONTENT_REPOSITORY_ID_E, OBJECT_INSTANCE_DATE_E, RETRY_COUNTER, EVENT_MESSAGE_E, OBJECT_MODIFICATOR_E, EVENT_ADD_INFO_E)
SELECT UUID_E, EVENT_NAME_E, EVENT_LISTENER_NAME_E, EVENT_STATUS_E, CREATION_DATE_E, MODIFICATION_DATE_E, OBJECT_ID_E, OBJECT_VERSION_E, OBJECT_MOD_DATE_E, CONTENT_REPOSITORY_ID_E, OBJECT_INSTANCE_DATE_E, RETRY_COUNTER, EVENT_MESSAGE_E, OBJECT_MODIFICATOR_E, EVENT_ADD_INFO_E
FROM dbo.Event WITH(TABLOCK)
WHERE NOT (
CONTENT_REPOSITORY_ID_E = 'acf5915e-0f08-4ab8-845f-6a37b44a59df'
AND EVENT_LISTENER_NAME_E = 'FULLTEXT_SERVICE'
)
ORDER BY UUID_E --Just a "guarantee" for performance. The optimizer will ignore this if not required.
OPTION (RECOMPILE) --Again, just a "guarantee" for performance.
; - Once that has completed, you can compare what's in the new table v.s. what you intended to keep from the old table.
- Once that has completed, apply the Non-Clustered indexes and the FK's (using the WITH CHECK option, which could take some time)
- If everything is good so far, rename the original table to something like EVENT_OLD and rename the new table from tmpEVENT to just EVENT.
- If you were in the FULL Recovery Model and changed to BULK LOGGED, change it back to FULL and immediately do another transaction log file backup.
- Do any smoke testing you need to but keep the original table for X number of days just to be sure. Once you're absolutely sure everything has been running correctly and there's no missing data in the new table for (IMHO) at least a week, you can then drop the renamed EVENT_OLD table.
- Once that's done, add this feat to your resume. 😀 You should also bring a document as to everything you did to any future interviews because it WILL impress the interviewers! :p
Heh... after all of that, if you have any questions on this subject, please send substantial quantities of $USD to my retirement fund. 😀 😀 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 6 posts - 1 through 6 (of 6 total)
You must be logged in to reply to this topic. Login to reply