Fixing time-outs when reorganizing indexes on large tables
-
The systems team has notified me that the reindex job on one of our servers has been failing. It seems to be failing while trying to reorganize an index on large tables. By large tables, I mean 2 billion rows (2x10^9) and 200 million rows (or 22 million pages and 2.5 million pages).
The error logged says
Time-out occurred while waiting for buffer latch type 4 for page (1:51228107), database ID 11.
Where the type can be 2 or 4 and the page usually changes.
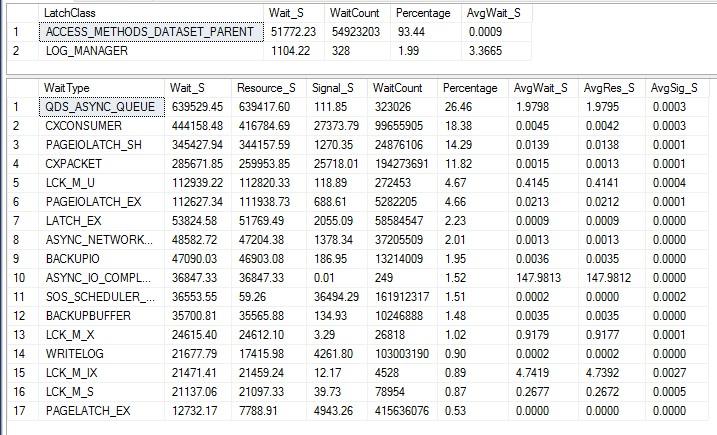
The main latches and waits in the server are the following:

There are 12 CPUs on the server and the MAXDOP is configured to 6, while the cost threshold for parallelism is set to 50.
I'm not sure if we should stop reorganizing and just rebuild once the fragmentation gets to a higher level (which I'm afraid is just postponing the problem), if there's some configuration that can be corrected or if we just should ask for more resources.
-
Except for columnstore indexes, every test I've ever seen says reorganize is a waste of time. You may still hit timeouts doing a rebuild, but yeah, I'd stop doing the reorganize on those indexes. Reorganize does help columnstore, a ton, so it's still worth doing.
As to avoiding the timeout, I'd lookup hints & stuff over at sqlskills. This is the kind of thing that Paul covers all the time.
If you were on 2017 or higher, I'd suggest looking into resumable rebuilds. Doing this in chunks makes it smoother.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning
Viewing 2 posts - 1 through 2 (of 2 total)
You must be logged in to reply to this topic. Login to reply