

Introduction
Chaos engineering is all about breaking your application! It sounds counterproductive; however, it is the exact opposite. It is a methodology to test how resilient your application is in the actual production world. In this article, we will try to address the following:
- What is Chaos Engineering?
- Why is it needed?
- What are the typical steps involved in Chaos engineering?
- Explore how Azure Chaos Studio can help improve application resiliency.
What is Chaos Engineering?
As I said earlier, it is all about breaking your application; however, not in the wrong way. The concept of Chaos engineering revolves around the idea of you engineering chaos (difficult situation) yourself for your application and then ensuring that it survives. According to Principles of Chaos Engineering, it is “the discipline of experimenting on a system in order to build confidence in the system’s capability to withstand turbulent conditions in production”. Chaos engineering compels you to think of scenarios in which your application can fail, test those scenarios and then improve based on the findings.
The idea is not new. Many organizations have been doing it in some shape or form; however, there was a lack of structure. For example, a controlled DR test where you conduct a series to ensure that your applications can survive a real disastrous event. Wait! Isn't this what you do in chaos engineering? Let us park this question for some time. Another example would be a load test where you would use software to simulate high traffic on your application and see how well it handles the load. Instead of doing things at random, Chaos engineering establishes a framework around such activities and sets you up for success.
What Chaos Engineering is not?
Rather than focusing on how the system works, Chaos engineering verifies that the system works! It is not about testing the application before it goes into production. It is about continuously finding causes for the failure of a production system or application and correcting them.
Why Chaos Engineering is needed?
If you are buying a house, you would want a home inspection to ensure that it is fit for its purpose. It typically includes steps to check if there are any water leaks or damages to the roof or your sprinkler system is working correctly, to name a few. Before moving into the house, you would ensure that the issues are fixed. You would apply a similar concept to your applications to ensure that it is fit for the consumers.
Typical steps involved in Chaos Engineering
You can follow the below steps for engineering your chaos:
- Establish a steady-state
- Develop a hypothesis
- Formulate the idea
- Define a blast radius and conduct your experiment
- Evaluate results
- Improve based on findings
- Repeat!
Let us look at each of these steps individually.
Establish a steady-state
The very first step is to identify a steady state. According to Wikipedia, "a system or a process is in a steady state if the variables (called state variables) which define the behavior of the system or the process are unchanging in time". Start by defining what the common conditions are for your application. For example,
- The user activity is highest between 8 AM and 10 AM.
- The CPU usage is peak when backups are running between 6 PM and 9 PM.
- There are thread leaks when a specific report runs.
Now you know what a typical day is like for the application, which users are happy or living with.
Develop a hypothesis
Try to find as many "ifs" as possible. For example,
- What if the CPU spikes at 9 AM when the user activity is at its peak?
- What if there is not enough space to hold the heap dumps for stuck threads?
- What if there are deadlocks at 9:30 AM?
- What if the backups failed and your transaction/ archive log has grown out of the allocated space?
- What if the primary application or database server suddenly crashes?
- What if this and what if that happens?
Formulate the idea
Once you have developed a hypothesis, you should design ways to simulate those scenarios.
Define a blast radius and conduct your experiment
Let us not forget that we are already in production. Irrespective of how desperate we are to ensure our application is perfect, the users should not get impacted. Define when you should conduct the experiment with zero or minimal user impact. For example,
- Simulate a deadlock when actual users are minimal.
- Simulate a crash after hours.
- Simulate high load when backups are running after hours etc.
Evaluate results
Document and research the results of tests.
Improve based on findings
Based on the flaws you identified during the tests, identify and implement corrective actions.
Repeat!
Chaos Engineering is not a one-time exercise. It is a continuous process that evolves every time you fix an issue. It goes back to defining a steady-state and then works its way towards improving.
Azure Chaos Studio
In November 2021, Azure Chaos Studio was announced at Microsoft ignite to test with the following benefits in mind:
- Test and improve reliability: Introduce your application to real-world chaotic scenarios in a controlled environment to test and improve the reliability of your application/s.
- Managed offering: You do not have to create scripts or manage tools. Just begin with defining resources, use experiment templates, and start Chaos engineering.
- Do it when the time is right: Experiment when it makes more sense to your organization instead of causing pain to consumers.
- Go over and above fault injection: It is not just faults in the underlying infrastructure that can cause issues in the real world. Test various scenarios which can impact the end-user.
How to use Chaos Studio?
If you are trying to test Chaos Studio, I would assume that you already have the application or resources created in Azure. Log in to the Azure portal and search for Chaos Studio.
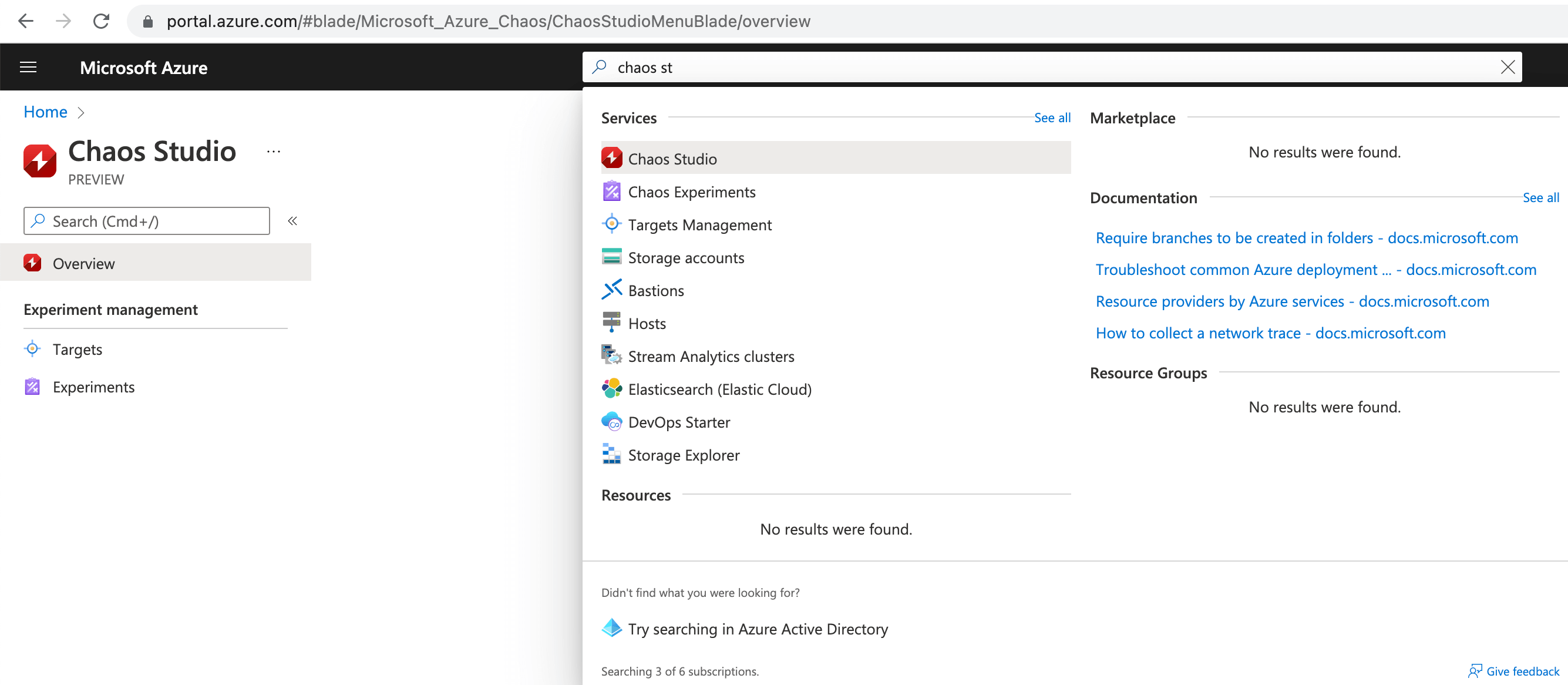
The next step is to onboard the Azure resources that you want to target to test chaos. Click on Targets and check the box against the target to be onboarded. Now, click on Enable targets and select "Enable service-direct targets (All resources).
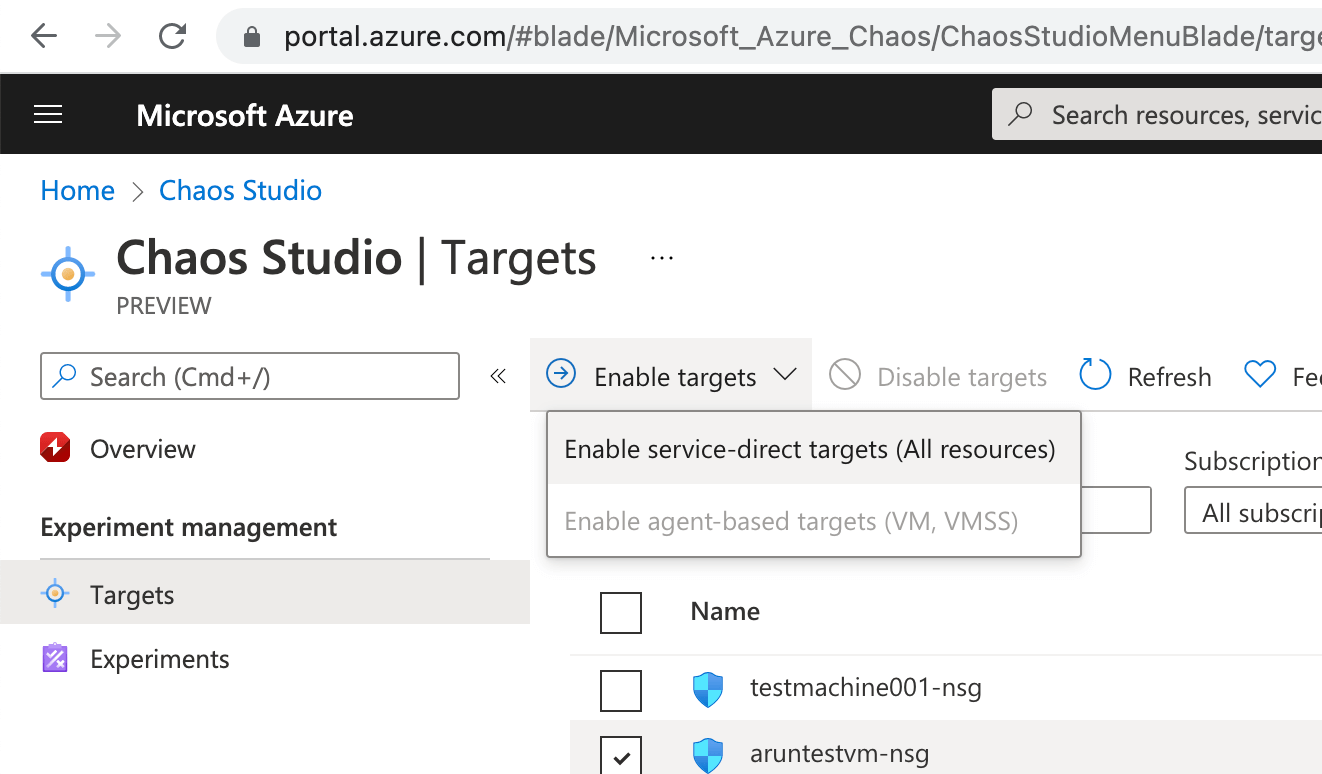
The next screen will show the progress of the deployment.
Go to Experiments in Chaos Studio and click on "+Create" to create your first experiment.

On the next screen, select the subscription, resource group, provide a meaningful name to the experiment, select the location and go to "Experiment Designer".
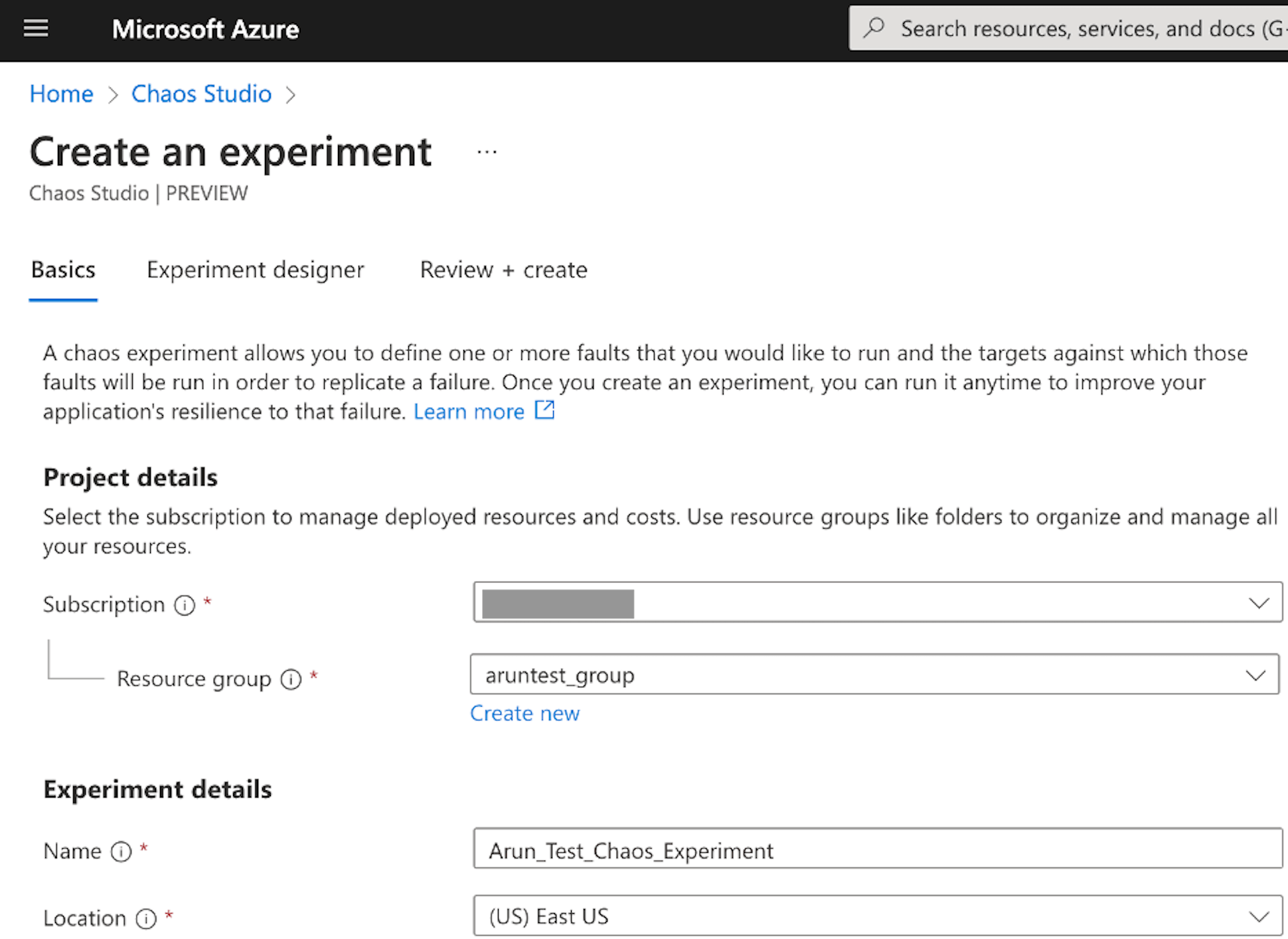
Under Experiment designer, provide a meaningful Step name and branch name. Then, click on "+Add action" and select a fault out of the 26 options available on January 30. Let us choose "VM Shutdown" for this exercise and click on "Target Resources".
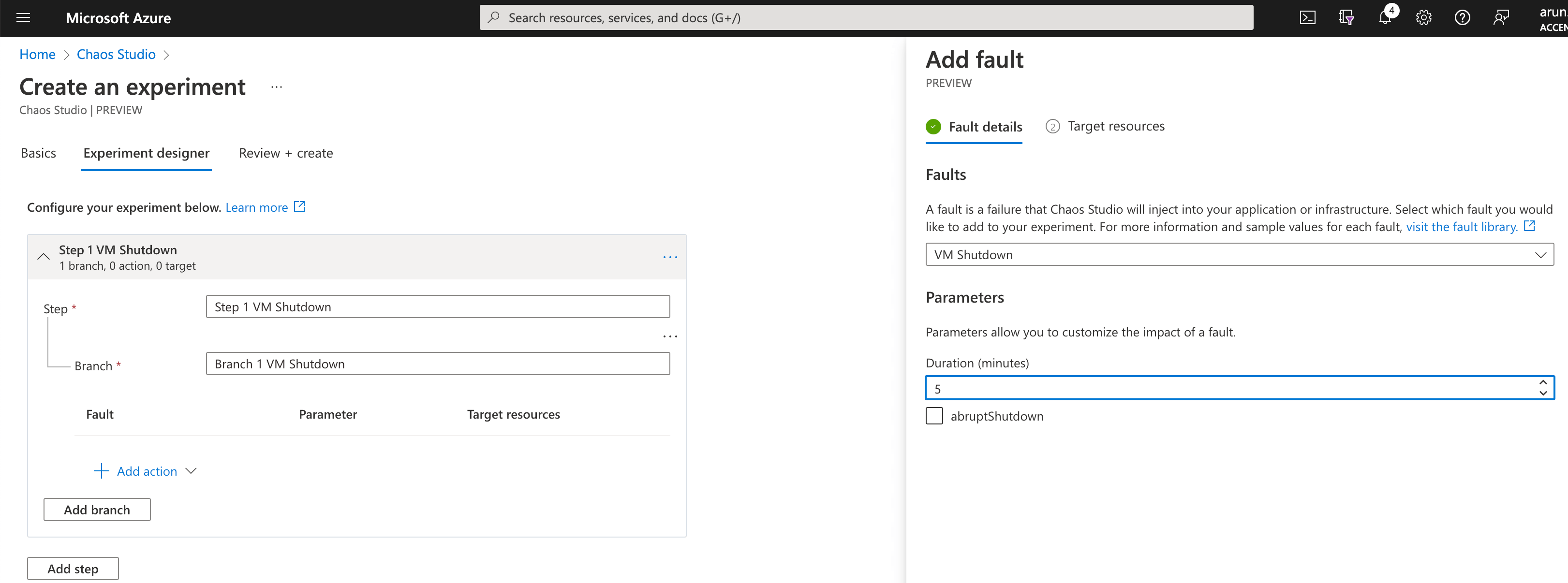
Now, select the target you enabled in the first step and click Add.
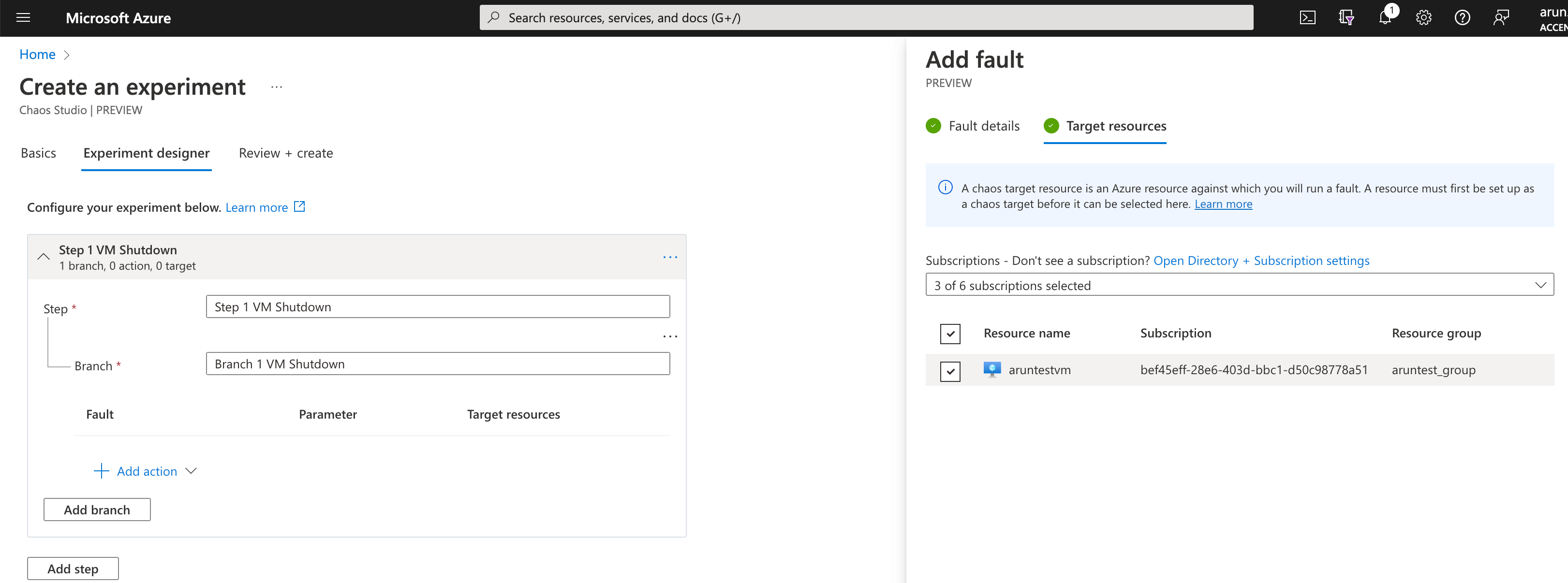
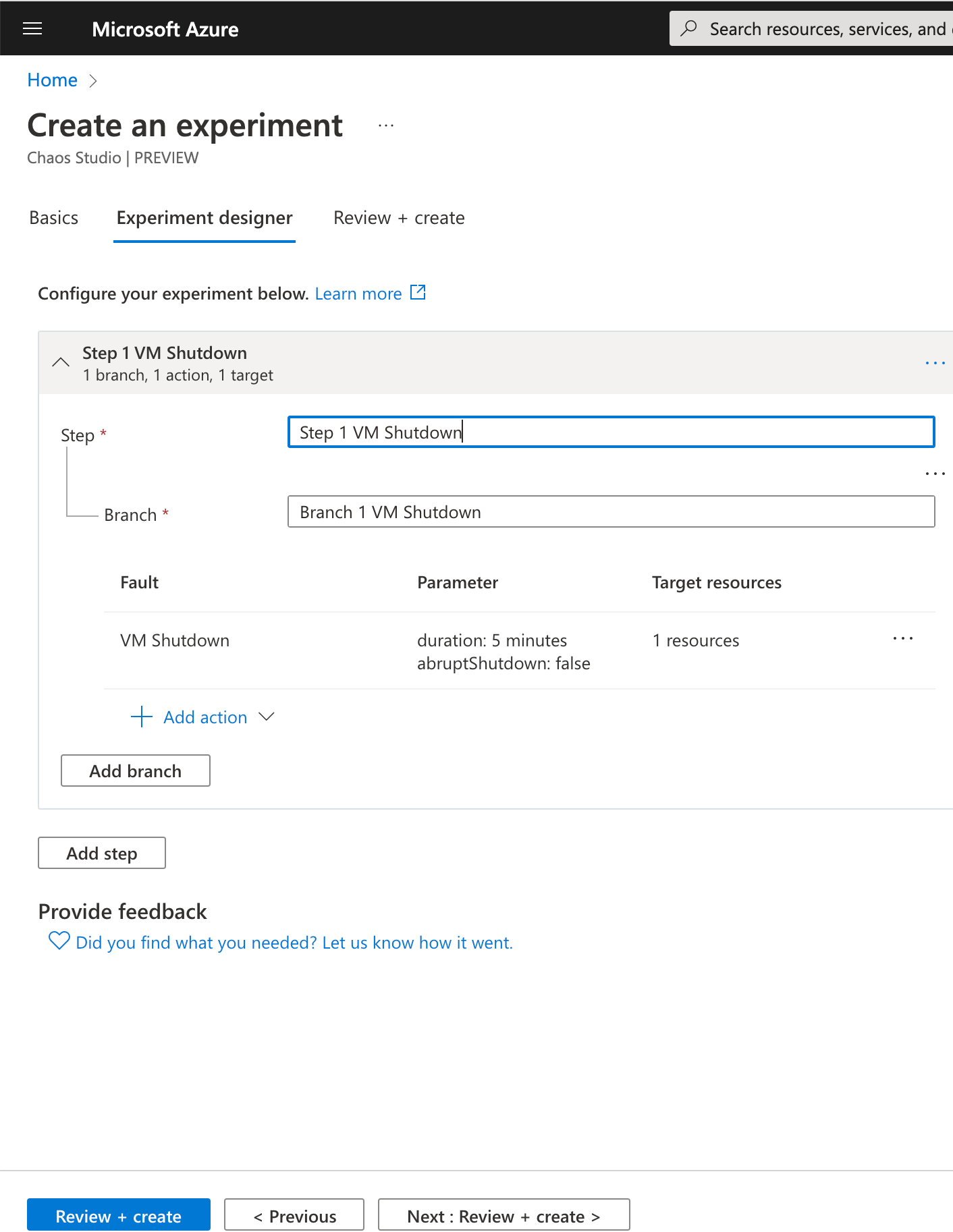
Now, click on "review + create" and "Create" your experiment. Note that you need to assign the experiment identity to each resource targeted before starting your experiment.
Navigate to the newly created assignment, click on "Access control (IAM) --> "+Add" --> "Add role assignment" and grant the appropriate role depending on your company's Azure IAM policies.
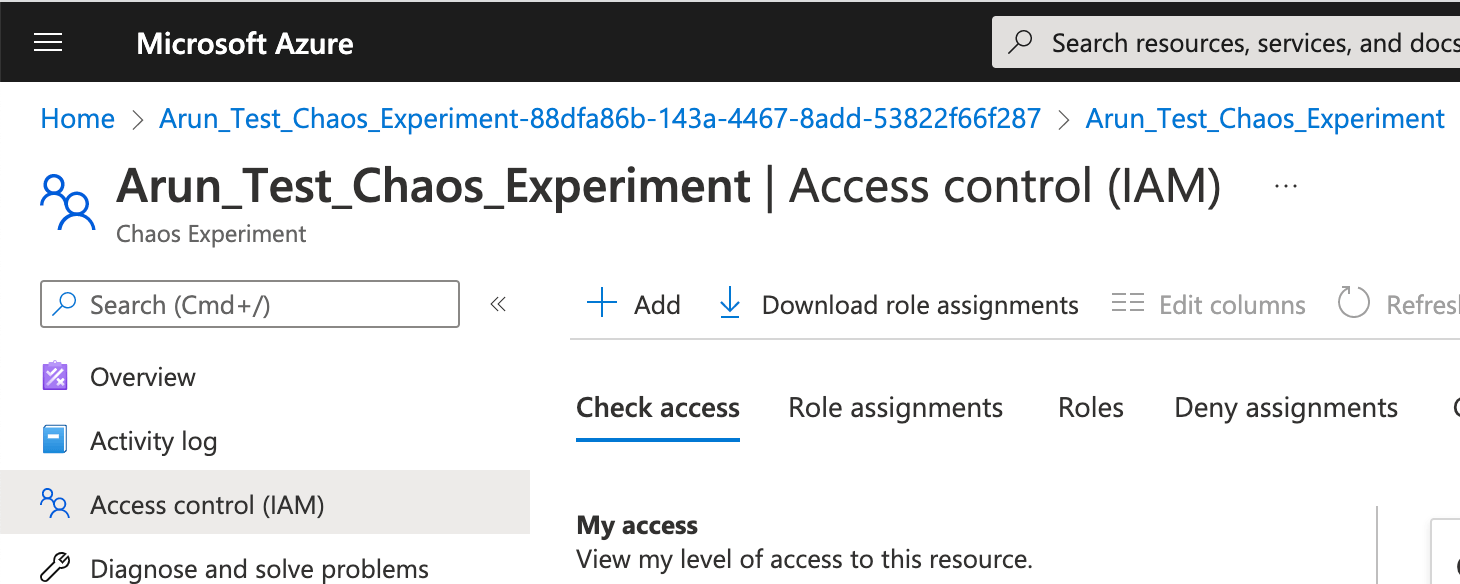
Once the role has been assigned, click on "Start" to run the experiment. Click "OK" on the warning. When the Status changes to "Running", click Details for the latest run under "History" to see details for your running experiment.
You can add and similarly test more faults. For additional details of available faults, please visit the following link:
Chaos Studio Pricing
Azure Chaos Studio is currently under public review and is free to use until April 4, 2022, post which pay-as-you-go charges will be applicable.
Conclusion
In this article, we discussed Chaos Engineering, its relevance, typical steps involved in the process, and how Azure Chaos Studio can help jump-start testing your application's resiliency. The primary benefit of using Chaos Studio is that it takes away the burden of scripting and managing software and, up to an extent, even creates a hypothesis with pre-defined fault definitions.
The distinction between DR testing and Chaos Engineering is that the former primarily concentrates on testing faults related to the underlying infrastructure. The latter goes a step further and helps address issues that can cause discomfort to end-users even if the underlying infrastructure or the application itself is up and running.

