High Log Reads on Readable Secondary Databases
-
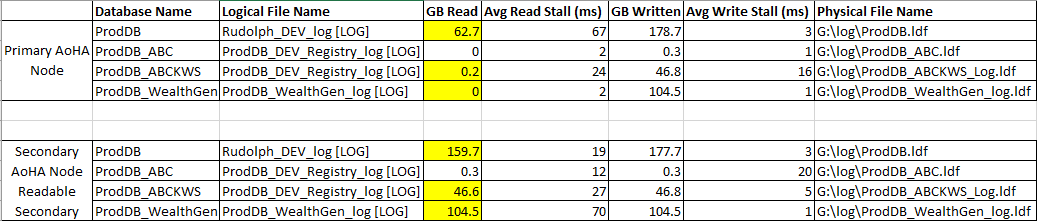
I've an AoHA environment where some of the Readable Secondary databases are being quite heavily read for reporting purposes. We are seeing that on these database there are high reads against the transaction logs. This image shows the levels of IO on the 3 main databases (highlighted), and one can see the Readable Secondary node shows Log Reads very nearly the same as log Writes, where the Primary node shows more normal Log Reads.

Any idea why the Readable Secondary would show such high log reads? I'm thinking this is either a characteristic of the way Readable Secondaries ensure data consistency, or possibly the log backups are being run against the secondary and causing this. The only problem about the 2nd option is I'm not seeing the same pattern on all database, only on those where there is active use of the secondary node for data access.
I'm aware the read stalls are very high on some DBs, this is what triggered the investigation.
- This topic was modified 4 years, 3 months ago by .
- This topic was modified 4 years, 3 months ago by .
Leo
Nothing in life is ever so complicated that with a little work it can't be made more complicated. -
Maybe I'm a bit out to lunch here, but those read stalls look pretty small. 1000 ms is 1 second, so your read stalls on the primary and secondary average a max of 70 ms, or 0.07 seconds. And the writes are even smaller.
Offhand, I am not certain why the reads from the log would be so much higher, but I could easily see this as being due to HA which would ensure that the secondary is up to date with the primary. The reads are mostly the same as the writes, with the exception of ProdDB. This would make me think that it is likely writing to the log then reading the log to ensure the data is accurate.
I am also wondering where you are getting those numbers from. If that is from outside SQL Server, are you able to identify the process that is reading the logs? It could be something like a misconfigured antivirus reading the files and that would make sense as to why it is reading the entire file as well, but I would expect high read stalls if it was the antivirus.
If it is from inside SQL server, are you able to identify any queries that may be reading those files? I would expect a Log backup would only need to read the data inside the file and that space may be mostly empty. I have some databases with large log files for some large processing that occurs, but that processing occurs rarely. Due to this, the log file is often sitting at 99% free, but there are cases where it gets to 10% free so we don't bother shrinking it. This is why I am thinking it is likely due to some external process like an AV and not related to SQL server. I would hope that your log file isn't ever nearly 100% used.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
I get the stats from the DMV
-- Lots of select logic
FROM sys.dm_io_virtual_file_stats(NULL, NULL) AS a
INNER JOIN sys.master_files AS b
ON a.file_id = b.file_id
AND a.database_id = b.database_idFrom a disk latency point of view I consider anything over 8ms slow.
If the reads were equal to the writes on all the databases I would consider the AV or simply AoHA as the cause, but this is only happening on the heavily read secondary databases, and I've not noticed this behaviour on any of my other environments where there is no read activity on the secondary.
Since these are all log reads, I'm not really aware of any way to specifically see when SQL is reading data from the Log. If there is such a utility it would be good to know.
Leo
Nothing in life is ever so complicated that with a little work it can't be made more complicated. -
I wish my disk latency was down as low as 8ms... my lowest read stall is 11ms and the highest is 265869 ms; mind you that DMV is showing you cumulative time, not average, so I'd need to capture more metrics to determine the average time.
Now, as a thought, are the databases with high GB Read also databases with a lot of transactions happening on them? The reason I ask is if the data is changing a lot, I would expect your secondary system to have a lot of reads and writes on the log as SQL tries to keep the 2 files in sync.
My opinion - if this isn't causing problems, it may make sense to not worry about it and focus on an actionable problem. Chances are this is the expected behavior of an AOAG (which is my guess as to what you meant by AoHA) and that cases where the reads and writes are high is when a lot of data is changing on the source and where it is low, it has less data changing on the source. OR, since you are pulling from that DMV, it could be that you are looking across months or years of data depending on when the last instance restart was. It MAY make sense to restart the instance to reset those counters and see how the numbers grow over time. Or, alternately (and safer), capture the numbers as they are NOW and review them again in a week and see how much they grew?
You may be chasing a red herring and might spend hours trying to fix a problem that isn't really there.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system.
Viewing 4 posts - 1 through 4 (of 4 total)
You must be logged in to reply to this topic. Login to reply