Reducing Temp Table Scans when joining two temp tables using OR conditions
-
Hi all. I have also posted this on DBA Stack Exchange, but I'm posting here because this community is pretty amazing. If this is not allowed, I will remove.
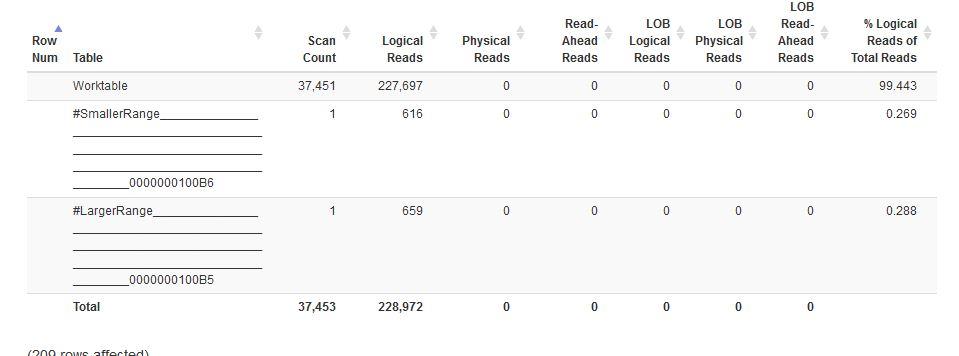
I'm working on a complicated query that I have up to this point been able to refactor to reduce execution time as well as number of scans and reads. At this point in the query, we have two temp tables which are structured exactly the same; the difference is that one table is a subset of the other (one was created using a larger date range). These tables are created by querying ~6 physical tables in a CTE, filtering down, etc. The part of the query I'm struggling with here is when we join the two tables on three fields, and then in the where clause, we further compare 5 columns in the tables using inequality operators and OR conditions. This query seems to be the costliest in the whole batch by ~200,000 logical reads and 30,000+ table scans. See the paste the plan link below for the execution plan for this exact part of the query as well as the DML statement.
https://www.brentozar.com/pastetheplan/?id=H16jNYvXK
As you can see, we're doing table scans on the temp tables and then doing a merge join. The plan looks OK enough except that the merge join's row estimate is WAY too high [est: 38335 vs actual: 209].

I have indeed attempted to create indexes for the temp tables, partly out of desperation. It didn't seem to help in this case. The indexes I have tested were nonclustered indexes using the three fields in the join condition. This just changed the execution plan to use RID lookups in the heaps and did nothing to change the estimate or reduce the number of scans/reads. I have also tried a nonclustered index on the fields used in the WHERE clause, but due to a couple of the fields being varchar(max) fields (poor schema design choice that is before my time and something I've been told to just deal with), I can't use these in an index. I have tried casting them down but some index inserts are failing because they're too many bytes. Not only that, but my understanding is that creating indexes on temp tables are in many cases not really super useful due to resource bottlenecks in other places, etc (https://www.brentozar.com/archive/2021/08/you-probably-shouldnt-index-your-temp-tables/).
I have also, again out of desperation, tried creating clustered indexes on the two tables with the join fields as the PK. This did indeed drastically increase the amount of execution time so much so that I didn't even wait for it to finish (>3 min vs ~5-10 sec). This was somewhat expected but I figured why not give it a try.
I have also tried breaking this out into 5 queries with union alls. Unfortunately this leaves me with duplicate rows, which we can't have, increases the work by a not insignificant amount, and unions just take too long.
What makes this worse is that this part of the query has a union behind it with another query that's extremely similar, so figuring this out is somewhat crucial here.
Why is it exactly that I'm getting so many reads and scans and how can I mitigate that in this scenario? I appreciate your time! If I have left out some crucial information, please let me know and I'll do my best to provide what I can. Thanks!
-
You need to cluster tables #SmallerRange and #LargerRange on the the JOIN columns: ( VID, IorO, OtherLocationID ). If those 3 column values are unique in one/both of the tables, specify that index(es) as UNIQUE. [A nonclustered index will be vastly less useful here, if not entirely useless.]
Add the clustering index before loading those temp tables. That is more efficient overall.
You will ultimately want to see a MERGE join, since, when appropriately used, it is the most efficient join type. But you want to get MERGE without having to do sorts every time the join is done.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
If you add the clustering before you add the data, make sure that you use WITH(TABLOCK) on the INSERT INTO statement to help take advantage of "Minimal Logging", which is about twice as fast as the normal stuff even in TempDB.
I will frequently add an ORDER BY the key columns which can help the optimizer figure out that Minimal Logging is possible and I'll also add an OPTION(RECOMPILE) to the INSERT as another bit of help, which is really important to do if the related SELECT has any variables in the FROM or WHERE clauses.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
If you add the clustering before you add the data, make sure that you use WITH(TABLOCK) on the INSERT INTO statement to help take advantage of "Minimal Logging", which is about twice as fast as the normal stuff even in TempDB.
I will frequently add an ORDER BY the key columns which can help the optimizer figure out that Minimal Logging is possible and I'll also add an OPTION(RECOMPILE) to the INSERT as another bit of help, which is really important to do if the related SELECT has any variables in the FROM or WHERE clauses.
In SQL 2016, you don't need the TABLOCK hint to get minimal logging. Ditto with ORDER BY; SQL "knows" it needs to sort the rows to INSERT them into the table in sequential order. And it will ignore the ORDER BY anyway if it "prefers"/needs to.
Recompile is OK: even if it's not technically needed, and it could be, it won't take long anyway on this type of INSERT query.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
As you said, the Order By will be ignored if it's not needed. It costs nothing to include it just to be sure.
As for TABLOCK not being required, the 2nd item in the following MS documentation say it IS required. Do you have code that proves otherwise when a Clustered Index is in place on an empty table?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Table IndexesRows in table Hints With or Without TF 610 Concurrent possible
Cluster Empty TABLOCK, ORDER (1) Minimal No
Cluster Empty None Minimal Yes (2)
Cluster Any None Minimal Yes (2)SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:
Table IndexesRows in table Hints With or Without TF 610 Concurrent possible
Cluster Empty TABLOCK, ORDER (1) Minimal No
Cluster Empty None Minimal Yes (2)
Cluster Any None Minimal Yes (2)Thanks, Scott. They said similar about using Trace Flag 610 prior to 2016 in the original document back in 2008. Perhaps I was doing something wrong but I could never get their stuff to work unless I included the TABLOCK even with TF 610 enabled globally.
Looks like I'm going to have to test it all over again.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:ScottPletcher wrote:
Table IndexesRows in table Hints With or Without TF 610 Concurrent possible
Cluster Empty TABLOCK, ORDER (1) Minimal No
Cluster Empty None Minimal Yes (2)
Cluster Any None Minimal Yes (2)Thanks, Scott. They said similar about using Trace Flag 610 prior to 2016 in the original document back in 2008. Perhaps I was doing something wrong but I could never get their stuff to work unless I included the TABLOCK even with TF 610 enabled globally.
Looks like I'm going to have to test it all over again.
Yep, and when I look over both documents, they seem in some ways contradictory. The problem is that TABLOCK can lock up other metadata things in the db, so I was trying to avoid it if possible. But I also need to make sure I get minimal logging for some very large loads. Luckily the db is in simple mode so I don't have to worry about that part of it.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:
Yep, and when I look over both documents, they seem in some ways contradictory. The problem is that TABLOCK can lock up other metadata things in the db, so I was trying to avoid it if possible. But I also need to make sure I get minimal logging for some very large loads. Luckily the db is in simple mode so I don't have to worry about that part of it.
I don't know about that. Again, I don't have the code right in front of me but I did prove to myself in the past that you still need the WITH(TABLOCK) to achieve minimal logging with a CI already in place in the past even on DBs in the SIMPLE Recovery Model.
Like I said, I've have some testing to do/redo.
And I totally agree about the contradictions between the two documents and other documents like the one I provided the link to.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 9 posts - 1 through 9 (of 9 total)
You must be logged in to reply to this topic. Login to reply