Advantage of having multiple files is a filegroup designated for LOBs ?
-
Having multiple files in a filegroup may help I/O performance with regular data, but ...
Is there an advantage of having multiple files is a filegroup designated for LOB data ?
Johan
Learn to play, play to learn !Dont drive faster than your guardian angel can fly ...
but keeping both feet on the ground wont get you anywhere :w00t:- How to post Performance Problems
- How to post data and code to get the best help- How to prevent a sore throat after hours of presenting ppt
press F1 for solution, press shift+F1 for urgent solution 😀
Who am I ? Sometimes this is me but most of the time this is me
-
Presumably yes, for the same reason. The total I/O will be spread across two files rather than one.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
That's indeed what I've been thinking, but I have not that much experience when it comes to storing LOBs ( up to 1GB ) in the database, so I've been wondering how the engine would balance such lob data between its filegroup files and it I/O gains are to be expected if you follow the same guidelines as for regular data filegroup files. ( max 1 / core starting with 4 or 8 files in a filegroup )
Johan
Learn to play, play to learn !Dont drive faster than your guardian angel can fly ...
but keeping both feet on the ground wont get you anywhere :w00t:- How to post Performance Problems
- How to post data and code to get the best help- How to prevent a sore throat after hours of presenting ppt
press F1 for solution, press shift+F1 for urgent solution 😀
Who am I ? Sometimes this is me but most of the time this is me
-
As a bit of a sidebar, if you're going to store LOBs in the database, do yourself a favor... force them to behave as they did with the old style LOBs. Force them to be out of row.
1. Set the table option to for large objects out of row.
2. Set a default for the LOB column to a single space.
This will seriously help prevent page splits due to "ExpAnsive" updates and will save your clustered index from "trapped short rows" and from unnecessary bloat.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
They are still image and text data types (legacy industrial tech "we will not change it for you" salesperson ). Out of row by default if I'm correct., but indeed, I'll check that option.
Thank you for the hint, Jeff.
Johan
Learn to play, play to learn !Dont drive faster than your guardian angel can fly ...
but keeping both feet on the ground wont get you anywhere :w00t:- How to post Performance Problems
- How to post data and code to get the best help- How to prevent a sore throat after hours of presenting ppt
press F1 for solution, press shift+F1 for urgent solution 😀
Who am I ? Sometimes this is me but most of the time this is me
- Johan Bijnens wrote:
They are still image and text data types (legacy industrial tech "we will not change it for you" salesperson ). Out of row by default if I'm correct., but indeed, I'll check that option.
Thank you for the hint, Jeff.
Yes. I can confirm. The old datatypes still default to "out of row". You still might need to add a single space as a default to keep the pointer column in the table from being "ExpAnsive" BUT, I don't know what the impact of that will be on your legacy code. For example, does it check for a null value anywhere in the code?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Getting back to the original question, we're just guessing based on related information supposed "Best Practice" information and, by now, I'm sure everyone knows how I feel about "Best Practice" that frequently turns out to be not such a good idea. To really know in this case, we should setup a substantial, repeatable test.
I guess I've lived a bit of a sheltered life... I've just realized that I've not personally had cause to use multiple files in a file group for any monolithic data structures (not partitioned). To wit, I haven't even proven to myself that having multiple files on a single "logical" drive on any SAN has any advantage except on TempDB.
Guess I'll give it a try soon... right after I take a look see, hoping to find a "Holy Grail" article on the subject.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Heh... an early look scared-up the ol' "not unless they're on different physical spindles" adage. While I logically agree with that, I've never actually tried it and so I don't actually know. In theory, different drive letters on a SAN are going to use different physical drives. I have a nice quiet "DBA ONLY" machine at work that I can try a comparison on. Fortunately for my normal work, they're all on Nimble NVME SSDs. That unfortunate for this test, though.
Some say that it'll do the same thing with SGAM and the like that happens on TempDB but I don't have the ability to whack on drives the way a busy production system hits on TempDB.
Off to the races!
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
First round of testing to 1, 2, 4, and 8 files on a single SSD drive of a minimally logged, single connection insert of 10,000,000 rows @89GB of a table with a BIGINT and an out-of-row VARCHAR(MAX) of almost 16KB is almost a complete waste of time. I'll run another set of the same tests in later today and provide "the numbers" and "the code".
I have no idea if it'll help multiple connection inserts or not.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Ok. I wasn't believing my eyes and ran some code a couple of times. Basically, the code build a decent size table with a Bigint column and a LOG column of almost 16B per row and that's been forced out of row even though it would have gone automatically anyway.
From there, I change to 4 different databases of that are on a different drive than the source above. The databases have 1 file, 2 files, 4 files, and 8 files and do a Minimally Logged insert. Here are durations for all of that...
(10000000 rows affected)
Duration Src: 00:05:45:753
(10000000 rows affected)
Duration Tgt1: 00:05:32:770
(10000000 rows affected)
Duration Tgt2: 00:05:45:677
(10000000 rows affected)
Duration Tgt4: 00:05:58:717
(10000000 rows affected)
Duration Tgt8: 00:06:34:583
***** Run Complete *****That looks to me like the more MDF/NDF files there are, the longer it takes for the single connection transfer of data. I haven't tested for multiple connection inserts and probably won't. Paul Randal has some posts over on SQL Skills that say that it does help multiple connections doing RBAR inserts. Here's one such article. but keep in mind that he didn't use LOBs in his testing so I'm afraid that the original question has not yet been answered, although we do know that it's bad for large, single connection, batch loads.
https://www.sqlskills.com/blogs/paul/benchmarking-do-multiple-data-files-make-a-difference/
Here's the code I used. I kept it simple.
--=====================================================================================================================
-- Create the Src ("source") database on one drive and the 4 Tgt ("target") databases on another.
-- Check the drive letters before you use this code because they'll probably be different than yours.
-- All of the databases have an MDF/NDF total size of 100,000MB (100GB) and LDFs or 10,000MB (10GB) each.
-- All of the databases are set to the SIMPLE Recovery Model so we can take advantage of Mimimal Logging in tests.
-- All of the databases are set to being owned by "SA".
--=====================================================================================================================
CREATE DATABASE [Src] ON PRIMARY
( NAME = N'Src', FILENAME = N'V:\SQLData\Src.mdf' , SIZE = 100000MB , FILEGROWTH = 1000MB )
LOG ON
( NAME = N'Src', FILENAME = N'W:\SQLLog\Src.ldf' , SIZE = 10000MB , FILEGROWTH = 1000MB )
GO
ALTER DATABASE [Tgt1] SET RECOVERY SIMPLE ;
ALTER AUTHORIZATION ON DATABASE::[Tgt1] TO [sa]
GO
--=====================================================================================================================
CREATE DATABASE [Tgt1] ON PRIMARY
( NAME = N'Tgt1_1', FILENAME = N'N:\SQLData\Tgt1_1.mdf' , SIZE = 100000MB , FILEGROWTH = 1000MB )
LOG ON
( NAME = N'Tgt1_log', FILENAME = N'W:\SQLLog\Tgt1_log.ldf' , SIZE = 10000MB , FILEGROWTH = 1000MB )
GO
ALTER DATABASE [Tgt1] SET RECOVERY SIMPLE ;
ALTER AUTHORIZATION ON DATABASE::[Tgt1] TO [sa]
GO
--=====================================================================================================================
CREATE DATABASE [Tgt2] ON PRIMARY
( NAME = N'Tgt2_1', FILENAME = N'N:\SQLData\Tgt2_1.mdf' , SIZE = 50000MB , FILEGROWTH = 1000MB ),
( NAME = N'Tgt2_2', FILENAME = N'N:\SQLData\Tgt2_2.ndf' , SIZE = 50000MB , FILEGROWTH = 1000MB )
LOG ON
( NAME = N'Tgt2_log', FILENAME = N'W:\SQLLog\Tgt2_log.ldf' , SIZE = 10000MB , FILEGROWTH = 1000MB )
GO
ALTER DATABASE [Tgt2] SET RECOVERY SIMPLE ;
ALTER AUTHORIZATION ON DATABASE::[Tgt2] TO [sa]
GO
--=====================================================================================================================
CREATE DATABASE [Tgt4]
ON PRIMARY
( NAME = N'Tgt4_1', FILENAME = N'N:\SQLData\Tgt4_1.mdf' , SIZE = 25000MB , FILEGROWTH = 1000MB ),
( NAME = N'Tgt4_2', FILENAME = N'N:\SQLData\Tgt4_2.ndf' , SIZE = 25000MB , FILEGROWTH = 1000MB ),
( NAME = N'Tgt4_3', FILENAME = N'N:\SQLData\Tgt4_3.ndf' , SIZE = 25000MB , FILEGROWTH = 1000MB ),
( NAME = N'Tgt4_4', FILENAME = N'N:\SQLData\Tgt4_4.ndf' , SIZE = 25000MB , FILEGROWTH = 1000MB )
LOG ON
( NAME = N'Tgt4_log', FILENAME = N'W:\SQLLog\Tgt4_log.ldf' , SIZE = 10000MB , FILEGROWTH = 1000MB )
GO
ALTER DATABASE [Tgt4] SET RECOVERY SIMPLE ;
ALTER AUTHORIZATION ON DATABASE::[Tgt4] TO [sa]
GO
--=====================================================================================================================
CREATE DATABASE [Tgt8]
ON PRIMARY
( NAME = N'Tgt8_1', FILENAME = N'N:\SQLData\Tgt8_1.mdf' , SIZE = 12500MB , FILEGROWTH = 1000MB ),
( NAME = N'Tgt8_2', FILENAME = N'N:\SQLData\Tgt8_2.ndf' , SIZE = 12500MB , FILEGROWTH = 1000MB ),
( NAME = N'Tgt8_3', FILENAME = N'N:\SQLData\Tgt8_3.ndf' , SIZE = 12500MB , FILEGROWTH = 1000MB ),
( NAME = N'Tgt8_4', FILENAME = N'N:\SQLData\Tgt8_4.ndf' , SIZE = 12500MB , FILEGROWTH = 1000MB ),
( NAME = N'Tgt8_5', FILENAME = N'N:\SQLData\Tgt8_5.ndf' , SIZE = 12500MB , FILEGROWTH = 1000MB ),
( NAME = N'Tgt8_6', FILENAME = N'N:\SQLData\Tgt8_6.ndf' , SIZE = 12500MB , FILEGROWTH = 1000MB ),
( NAME = N'Tgt8_7', FILENAME = N'N:\SQLData\Tgt8_7.ndf' , SIZE = 12500MB , FILEGROWTH = 1000MB ),
( NAME = N'Tgt8_8', FILENAME = N'N:\SQLData\Tgt8_8.ndf' , SIZE = 12500MB , FILEGROWTH = 1000MB )
LOG ON
( NAME = N'Tgt8_log', FILENAME = N'W:\SQLLog\Tgt8_log.ldf' , SIZE = 10000MB , FILEGROWTH = 1000MB )
GO
ALTER DATABASE [Tgt8] SET RECOVERY SIMPLE ;
ALTER AUTHORIZATION ON DATABASE::[Tgt8] TO [sa]
GO
--=====================================================================================================================
-- The Tests - Populate the source database and then pull the data into each target database.
--=====================================================================================================================
--===== Start a timer
DECLARE @StartDT DATETIME = GETDATE()
,@Duration CHAR(12)
;
--===== Populate the source database, which is on a different drive than all the other databases.
USE Src;
DROP TABLE IF EXISTS dbo.Src
CREATE TABLE dbo.Src
(
RowNum BIGINT NOT NULL PRIMARY KEY CLUSTERED
,ALOB VARCHAR(MAX) NOT NULL DEFAULT ' '
)
;
EXEC sp_tableoption 'dbo.Src', 'large value types out of row', 1;
CHECKPOINT;
TRUNCATE TABLE dbo.Src;
INSERT INTO dbo.Src WITH (TABLOCK)
SELECT TOP 10000000
RowNum = ROW_NUMBER() OVER (ORDER BY @@SPID)
,ALob = REPLICATE(NEWID(),444)
FROM sys.all_columns ac1 CROSS JOIN sys.all_columns ac2
ORDER BY RowNum
OPTION (RECOMPILE)
;
--===== Display the run duration
SELECT @Duration = CONVERT(CHAR(12),GETDATE()-@StartDT,114)
RAISERROR('Duration Src: %s',0,0,@Duration) WITH NOWAIT
;
GO
--=====================================================================================================================
--===== Start a timer
DECLARE @StartDT DATETIME = GETDATE()
,@Duration CHAR(12)
;
USE Tgt1;
DROP TABLE IF EXISTS dbo.Tgt1;
CREATE TABLE dbo.Tgt1
(
RowNum BIGINT NOT NULL PRIMARY KEY CLUSTERED
,ALOB VARCHAR(MAX) NOT NULL DEFAULT ' '
)
;
EXEC sp_tableoption 'dbo.Tgt1', 'large value types out of row', 1;
CHECKPOINT
;
TRUNCATE TABLE dbo.Tgt1;
INSERT INTO dbo.Tgt1 WITH (TABLOCK)
(RowNum,ALob)
SELECT RowNum = ROW_NUMBER() OVER (ORDER BY @@SPID)
,ALob = REPLICATE(NEWID(),444)
FROM Src.dbo.Src
ORDER BY RowNum
OPTION (RECOMPILE)
;
--===== Display the run duration
SELECT @Duration = CONVERT(CHAR(12),GETDATE()-@StartDT,114)
RAISERROR('Duration Tgt1: %s',0,0,@Duration) WITH NOWAIT
;
GO
--=====================================================================================================================
--===== Start a timer
DECLARE @StartDT DATETIME = GETDATE()
,@Duration CHAR(12)
;
USE Tgt2;
DROP TABLE IF EXISTS dbo.Tgt2;
CREATE TABLE dbo.Tgt2
(
RowNum BIGINT NOT NULL PRIMARY KEY CLUSTERED
,ALOB VARCHAR(MAX) NOT NULL DEFAULT ' '
)
;
EXEC sp_tableoption 'dbo.Tgt2', 'large value types out of row', 1;
CHECKPOINT
;
TRUNCATE TABLE dbo.Tgt2;
INSERT INTO dbo.Tgt2 WITH (TABLOCK)
(RowNum,ALob)
SELECT RowNum = ROW_NUMBER() OVER (ORDER BY @@SPID)
,ALob = REPLICATE(NEWID(),444)
FROM Src.dbo.Src
ORDER BY RowNum
OPTION (RECOMPILE)
;
--===== Display the run duration
SELECT @Duration = CONVERT(CHAR(12),GETDATE()-@StartDT,114)
RAISERROR('Duration Tgt2: %s',0,0,@Duration) WITH NOWAIT
;
GO
--=====================================================================================================================
--===== Start a timer
DECLARE @StartDT DATETIME = GETDATE()
,@Duration CHAR(12)
;
USE Tgt4 --4:10
DROP TABLE IF EXISTS dbo.Tgt4;
CREATE TABLE dbo.Tgt4
(
RowNum BIGINT NOT NULL PRIMARY KEY CLUSTERED
,ALOB VARCHAR(MAX) NOT NULL DEFAULT ' '
)
;
EXEC sp_tableoption 'dbo.Tgt4', 'large value types out of row', 1;
CHECKPOINT
;
TRUNCATE TABLE dbo.Tgt4;
INSERT INTO dbo.Tgt4 WITH (TABLOCK)
(RowNum,ALob)
SELECT RowNum = ROW_NUMBER() OVER (ORDER BY @@SPID)
,ALob = REPLICATE(NEWID(),444)
FROM Src.dbo.Src
ORDER BY RowNum
OPTION (RECOMPILE)
;
--===== Display the run duration
SELECT @Duration = CONVERT(CHAR(12),GETDATE()-@StartDT,114)
RAISERROR('Duration Tgt4: %s',0,0,@Duration) WITH NOWAIT
;
GO
--=====================================================================================================================
--===== Start a timer
DECLARE @StartDT DATETIME = GETDATE()
,@Duration CHAR(12)
;
USE Tgt8;
DROP TABLE IF EXISTS dbo.Tgt8;
CREATE TABLE dbo.Tgt8
(
RowNum BIGINT NOT NULL PRIMARY KEY CLUSTERED
,ALOB VARCHAR(MAX) NOT NULL DEFAULT ' '
)
;
EXEC sp_tableoption 'dbo.Tgt8', 'large value types out of row', 1;
CHECKPOINT
;
TRUNCATE TABLE dbo.Tgt8;
INSERT INTO dbo.Tgt8 WITH (TABLOCK)
(RowNum,ALob)
SELECT RowNum = ROW_NUMBER() OVER (ORDER BY @@SPID)
,ALob = REPLICATE(NEWID(),444)
FROM Src.dbo.Src
ORDER BY RowNum
OPTION (RECOMPILE)
;
--===== Display the run duration
SELECT @Duration = CONVERT(CHAR(12),GETDATE()-@StartDT,114)
RAISERROR('Duration Tgt8: %s',0,0,@Duration) WITH NOWAIT
;
--=====================================================================================================================
--***** End of Run *****
RAISERROR('***** Run Complete *****',0,0,@Duration) WITH NOWAIT
;--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
placement of files on physical drives (same or separate) as well as being local or SAN (and type of SAN) as well as being SSD or SATA (and RAID setup) is going to affect this greatly.
Insert vs read activity is also going to impact - if mostly insert its one thing - if mostly read is another.
there is no single straight answer of which is better so as usual the answer is TEST TEST TEST.
-
Agreed... That's why I have stated multiple times that this was for a single batch INSERT and that folks need to look at Paul Randal's article that I cited for multiple connection inserts, etc. You do have to TEST, TEST, TEST.
I'll also state that I'm not really surprised that more files on a single physical drive caused worse performance. I've seen that happen for multi-file backups, as well, and it doesn't matter if it's on SSD or Spinning rust. Stuff still has to make it through the controller.
And, just because you "know from experience", it's worth testing again there are just too many different products and configurations to say you actually know what's going to happen. For example, even though my experience has been that multi-file backups to a common drive don't do much if anything for performance and I've actually seen it slow things down, doesn't mean that I wouldn't try it on a different system. Only a good test will settle it.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
wow, Thank you Jeff, for your tests and posting the results.
As always, YMMV, so only own situation tests will provide a good insight.
Hoping such tests confirm the handed numbers and guidelines and you know which direction to go.
As we can add LUNs to the production instance, enhancing I/O channels should be easy.
( My test instance only has spindles.)
I think I'll just keep it simple and move each blob holding table to its own filegroup ( as the numbers are low ) and rebuild-move all other tables out of [primay] too and then shrink primary.
After my tests, still have to convince the software vendor to accept these modifications for future sake
Johan
Learn to play, play to learn !Dont drive faster than your guardian angel can fly ...
but keeping both feet on the ground wont get you anywhere :w00t:- How to post Performance Problems
- How to post data and code to get the best help- How to prevent a sore throat after hours of presenting ppt
press F1 for solution, press shift+F1 for urgent solution 😀
Who am I ? Sometimes this is me but most of the time this is me
-
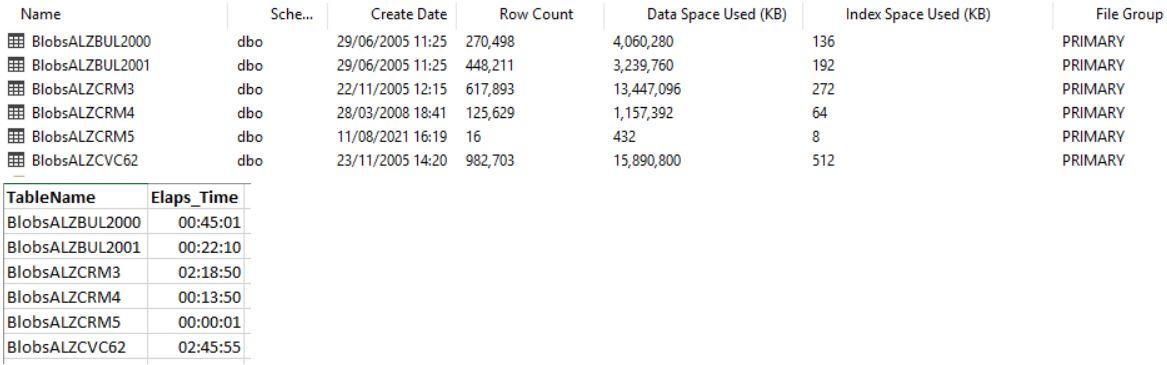
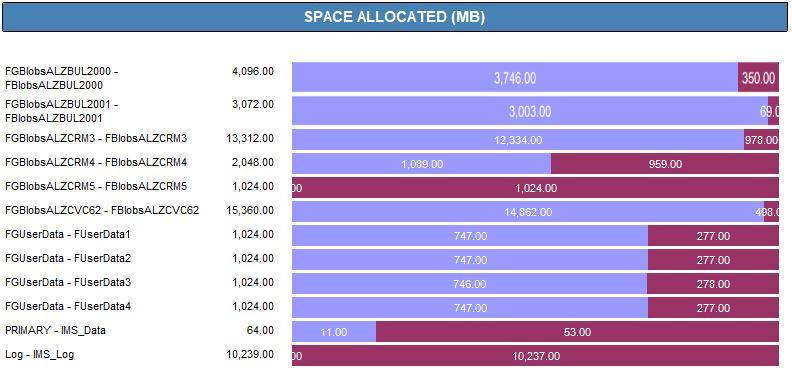
I prepared all filegroups and files and preallocated the needed space.
These are the results of my test on my test server ( old + slow spindles )

New space distribution:
Johan
Learn to play, play to learn !Dont drive faster than your guardian angel can fly ...
but keeping both feet on the ground wont get you anywhere :w00t:- How to post Performance Problems
- How to post data and code to get the best help- How to prevent a sore throat after hours of presenting ppt
press F1 for solution, press shift+F1 for urgent solution 😀
Who am I ? Sometimes this is me but most of the time this is me
-
I've probably just not had enough coffee yet, Johan, but the data you posted doesn't look like a performance comparison to me. It looks like measurements from a single run.
I want to also remind you that my results are on a single drive target regardless of the number of files in a filegroup. That doesn't seem to match your scenario not to mention that you have spindles rather than SSDs. I don't have the test results anymore but there are a lot of people out on the internet that have posted the results of similar tests (but not including LOBs but I don't know how much that may or may not affect things). If there are different physical spindles for each drive, there can be a decent performance improvement whether there's just one connection or more.
If you end up doing something big, it could make a good difference for you on the spindle drives.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)


Viewing 15 posts - 1 through 15 (of 16 total)
You must be logged in to reply to this topic. Login to reply