

Introduction
This article presents a script that finds a perfect match in any bipartite graph or shows why one cannot exist.
Overview
Recall that a bipartite graph is any undirected graph [1] where its nodes (or vertices) can be partitioned into two sets, and where edges only exist between those two sets. For this article, those sets are equal in size.
For example, consider the following bipartite graph:
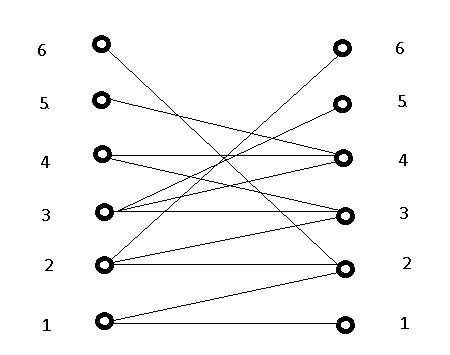
The goal is to find a perfect match, which is a collection of edges sharing no nodes and for which every node is part of some edge in that collection.
This script interprets a popular algorithm for finding perfect matchings [2] by first randomly selecting as many disjoint edges as possible until no more can be found:
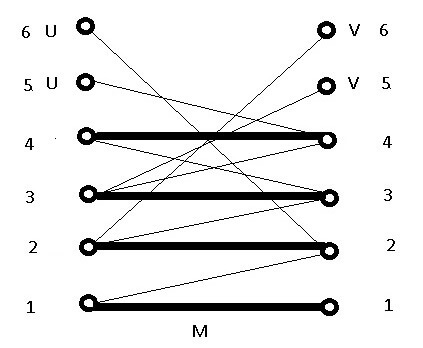
Here, four disjoint edges (in boldface) have been selected: (1,1), (2,2), (3,3), (4,4). Denoting this collection by M, the script will modify M repeatedly until it covers all nodes or show why it can’t be done. Note that if this algorithm fails to match at least half of all nodes, then no perfect matching exists. This follows from a simple counting argument on how many nodes would be available for building a perfect match.
Denote by U and V the collection of left and right nodes that are not in M. These are the nodes that are missing from the current match. Clearly |U| = |V| since the graph contains an equal number of left and right nodes.
More importantly, no edge connects nodes in U and V, otherwise the so-called greedy algorithm would have selected it.
So, any edge from U must terminate in M. For example, in the above graph, the edges (5,4) and (6,2) from U terminate in M. Similarly, the edges (2,6) and (3,5) from V terminate in M. Note that, by definition, the first coordinate of any edge is always the left node.
Where do we go from here?
Consider the following two bipartite graphs Graph1 and Graph2, each with a partial match:
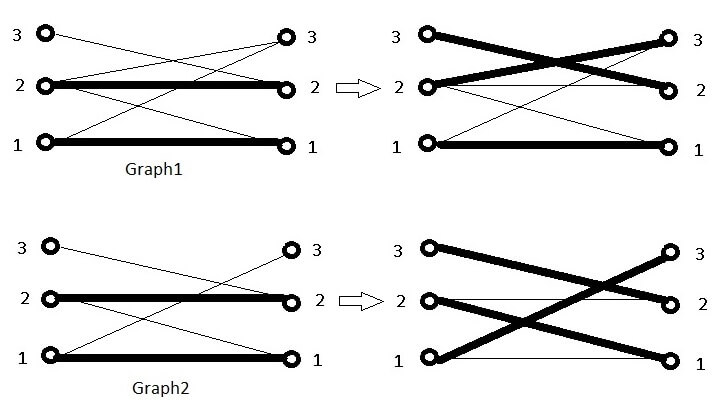
In the first graph there is a path of length 2 from U to M to M, namely [3,2,2], whose terminal node is connected by an edge to a node in V. Adding that edge to the path enables a bigger matching by alternately adding/deleting its edges to/from M. In the second graph no such path exists, but if we expand the original path [3,2,2] to [3,2,2,1,1] then a bigger matching may be obtained in the same way. This celebrated technique will be used by the script to find a bigger matching.
So, by this bit of inspiration, the next step is to document all paths of length 2 from U to M to M by first building the sets S and T containing their nodes in M. Each node involved in these paths saves its own path from U as an attribute:
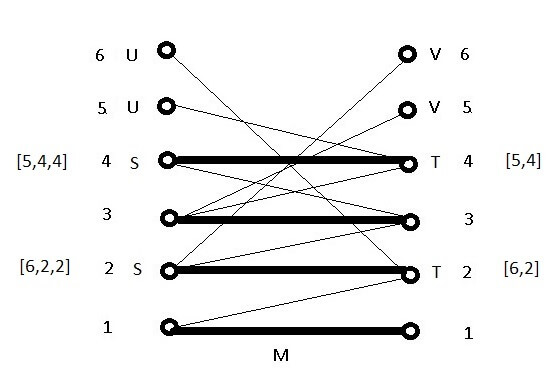
Clearly S and T have the same number of nodes. This construction, based on the current partial match, will be called the initialization of S.
After initialization of S, the script looks for an edge from S to V.
If a bigger matching cannot be found using the technique mentioned above, because no edge exists between S and V, then S and T will be expanded to admit longer paths. Hopefully, some new node in S will have an edge to V.
But if it finds an edge, say (2,6), then it has a path (in this case [6,2,2,6]) from U to V where its edges are alternately outside and inside M (starting at U and ending at V). The above technique will transform M into another matching with one more edge. This construction will be called the augmentation of M. Such paths are called “augmenting” because they can be used to augment M by alternately adding and deleting its edges to/from M to yield a different M with an extra edge:
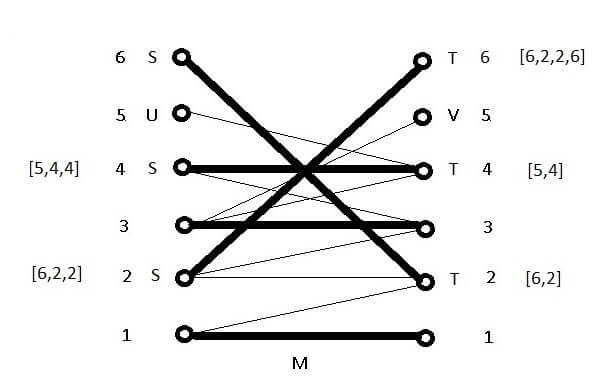
Now both U and V have one less node, and the new M has one more edge. But some paths stored by S and T will now be out of date since U has just lost a member. In particular, the path [6,2,2] for the left node 2 no longer starts from a member of U so augmentation won’t work using it. For that reason, S is always re-initialized by the script after a successful augmentation:
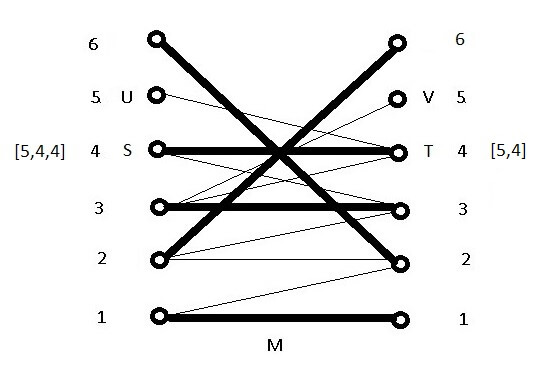
But now augmentation is not possible because no edge exists between S and V. At this point the script will attempt to expand S by finding all paths of length 2 from S to M to M outside of T in the hope that the terminal node of one of them will have an edge to V:
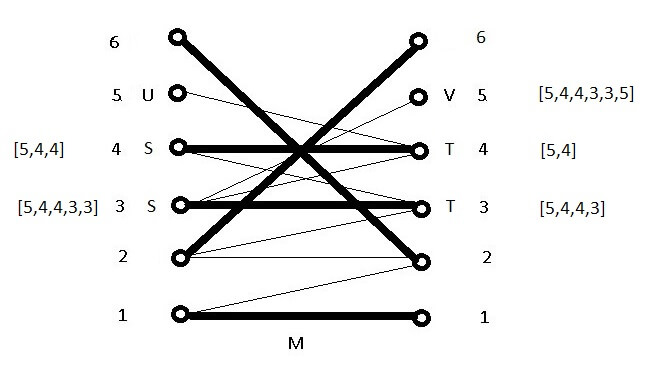
This technique will be called the expansion of S. Fortunately, after expansion, augmentation works here with the new path [5,4,4,3,3,5] from U to V to produce a new M, which is a perfect match:
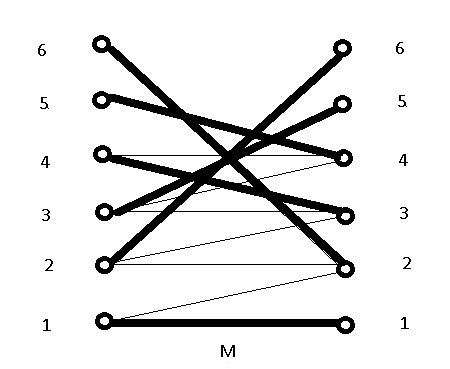
But suppose expanding S was not possible because the edge (4,3) didn’t exist. Then the neighbors of S would be exactly T (instead of a proper superset of T) because no edge exists between S and V since augmentation just failed! But then U and S will collectively contain more nodes than its neighbors since all edges from U must terminate in T, by construction. This would explain why no matching is possible.
Since the process of augmentation of M + initialization of S + expansion of S always expands M or S, it must eventually halt with either a perfect matching, or U and S will contain more nodes than its neighbors (preventing a perfect match).
Putting it all together, the script’s approach to find a perfect match is the following:
Apply greedy algorithm to get partial matching
If partial match fails to match at least half of all nodes, return with error set
If match is perfect, return with result set
Call initialization of S
WHILE 1 = 1
BEGIN
Call augmentation of M repeatedly until augmentation fails
For each loop:
IF augmentation succeeds,
BEGIN
IF match is now perfect, return with result set
Call initialization of S
END
Call expansion of S since augmentation of M just failed
IF unable to expand S, no perfect match is possible so return with error set
ENDScript
This script calls four stored procedures (spGreedy, spInitializeS, spExpandM, spExpandS) in the following way:
-- Declarations
DECLARE @Result int
DECLARE @Result1 int
DECLARE @Result2 int
DECLARE @Result3 int
-- No counting
SET NOCOUNT ON
--Apply greedy algorithm to get partial matching
EXEC @Result = spGreedy
IF @Result <> 1 RETURN
-- Initialize U, V, S, T, Path
EXEC @Result = spInitializeS
-- Attempt to find perfect matching
-- For each loop, at least one of M or S will expand or no perfect match exists
WHILE 1 = 1
BEGIN
-- Repeatedly expand M with a new edge until it fails
-- Whenever successful: U, V, S, T, Path must be re-initialized
SET @Result1 = 1
SET @Result2 = 1
WHILE @Result1 = 1
BEGIN
EXEC @Result1 = spExpandM
IF @Result1 = 1
BEGIN
EXEC @Result2 = spInitializeS
IF @Result2 = 0 RETURN -- spExpandM may have just built a perfect match
END
END
-- Expand S
-- Expanding M has just failed so if expanding S fails, no perfect matching exists
-- If expanding S succeeds, try expanding M again
EXEC @Result3 = spExpandS
IF @Result3 <> 1 RETURN
END
Example
Suppose six pilots at a regional airline have each expressed their preferences for a co-pilot:
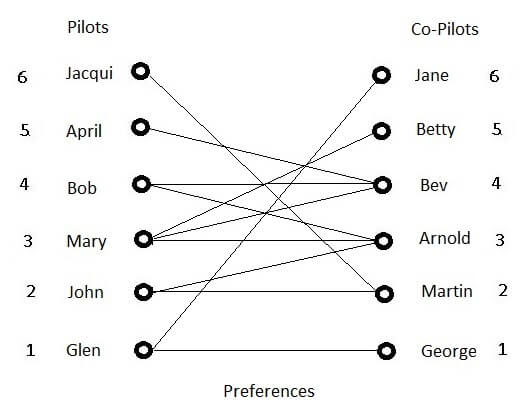
Can a perfect match be found, so that each pilot flies with a preferred co-pilot? The script shows why that’s not possible:
| NumDistinctLeftNodes | NumDistinctRightNodes | PerfectMatchNotPossible |
| 4 | 3 | Not enough right nodes to match left nodes, so perfect match impossible |
| LeftNode | RightNode |
| 2 | 2 |
| 2 | 3 |
| 4 | 3 |
| 4 | 4 |
| 5 | 4 |
| 6 | 2 |
The four left nodes 2,4,5,6 collectively have three neighbors, so no match is possible. But if Jacqui relaxes her preferences and adds Jane to her preference list, then a perfect match exists:

How The Script Works
Three tables are used to define a bipartite graph, where columns exist for LeftNode, RightNode, U, S, V, T, Path, M:
LeftNodes:
| LeftNode | U | S | Path |
| 1 | 0 | 0 | |
| 2 | 0 | 0 | |
| 3 | 0 | 0 | |
| 4 | 0 | 0 | |
| 5 | 0 | 0 | |
| 6 | 0 | 0 |
RightNodes:
| RightNode | V | T | Path |
| 1 | 0 | 0 | |
| 2 | 0 | 0 | |
| 3 | 0 | 0 | |
| 4 | 0 | 0 | |
| 5 | 0 | 0 | |
| 6 | 0 | 0 |
Graph:
| LeftNode | RightNode | M |
| 1 | 1 | 0 |
| 1 | 6 | 0 |
| 2 | 2 | 0 |
| 2 | 3 | 0 |
| 3 | 3 | 0 |
| 3 | 4 | 0 |
| 3 | 5 | 0 |
| 4 | 3 | 0 |
| 4 | 4 | 0 |
| 5 | 4 | 0 |
| 6 | 2 | 0 |
| 6 | 6 | 0 |
The script attempts to set M to 1 for selected rows in Graph so that each left and right node appears exactly once in that selection (perfect match). For the above example, the table’s perfect match looks like this:
| LeftNode | RightNode | M |
| 1 | 1 | 1 |
| 1 | 6 | 0 |
| 2 | 2 | 1 |
| 2 | 3 | 0 |
| 3 | 3 | 0 |
| 3 | 4 | 0 |
| 3 | 5 | 1 |
| 4 | 3 | 1 |
| 4 | 4 | 0 |
| 5 | 4 | 1 |
| 6 | 2 | 0 |
| 6 | 6 | 1 |
The stored procedures are simple. For example, spExpandM shows how the tables are modified when seeking to expand M:
ALTER PROCEDURE [dbo].[spExpandM]
AS
BEGIN
/*
Script: Try to find an edge from S to V
If found, add an extra edge to M
Returns: -1 M was not expanded
0 M was already perfect
1 M was expanded
*/
-- No counting
SET NOCOUNT ON
-- Declarations
DECLARE @LeftNode int
DECLARE @RightNode int
DECLARE @Path varchar(max)
DECLARE @Count int
DECLARE @S int
DECLARE @I int
DECLARE @SQL nvarchar(max)
DECLARE @TABLE TABLE(I int IDENTITY, Node varchar(128))
/*
Execution
*/
-- If partial matching is already perfect, display matching and return
IF (SELECT count(*) FROM dbo.Graph WHERE M = 1) = (SELECT count(*) FROM dbo.LeftNodes)
BEGIN
SELECT * FROM dbo.Graph WHERE M = 1 ORDER BY LeftNode, RightNode
RETURN 0
END
-- Try to find an edge from S to V
SELECT TOP 1 @LeftNode = LeftNode, @RightNode = RightNode FROM dbo.Graph
WHERE
LeftNode IN (SELECT LeftNode FROM dbo.LeftNodes WHERE S = 1)
AND
RightNode IN (
SELECT RightNode FROM dbo.RightNodes
WHERE
RightNode IN (SELECT RightNode FROM dbo.RightNodes WHERE V = 1)
)
-- Return if not possible
IF @LeftNode IS NULL RETURN -1 -- No edge found from S to V
-- Set Path in right node by appending it to Path in left node
-- This Path will show how to get to the right node in V from U
-- It will be used to alternately add/delete edges to/from M
UPDATE dbo.RightNodes
SET Path = (SELECT TOP 1 Path FROM dbo.LeftNodes WHERE LeftNode = @LeftNode) +
',' +
CAST(@RightNode AS VARCHAR(16))
WHERE RightNode = @RightNode
-- Now select this Path to alternately add/delete edges to/from M
-- so a new edge will be added to M.
SET @Path = (SELECT TOP 1 Path FROM dbo.RightNodes WHERE RightNode = @RightNode)
-- Use the function split_string to return a table containing the nodes in the path,
-- along with an IDENTITY column I to provide their order in the path.
INSERT INTO @TABLE SELECT Node from split_string(@Path,',')
-- First count the number of nodes for the subsequent loop
SET @Count = (SELECT count(*) FROM @TABLE)
-- Loop through table of nodes, alternately adding/deleting them in M
SET @I = 1 -- position of row in table
SET @S = 1 -- S = 1 means add, S = 0 means delete
WHILE @I < @Count
BEGIN
SELECT @LeftNode = Node FROM @TABLE WHERE I = @I
SELECT @RightNode = Node FROM @TABLE WHERE I = @I + 1
-- Note that left and right nodes appear alternately in @TABLE
IF @S = 1
SET @SQL = 'UPDATE dbo.Graph SET M = ' + CAST(@S AS varchar(2)) +
' WHERE LeftNode = ' + CAST(@LeftNode AS varchar(16)) +
' AND RightNode = ' + CAST(@RightNode AS varchar(16))
ELSE
SET @SQL = 'UPDATE dbo.Graph SET M = ' + CAST(@S AS varchar(2)) +
' WHERE RightNode = ' + CAST(@LeftNode AS varchar(16)) +
' AND LeftNode = ' + CAST(@RightNode AS varchar(16))
EXEC sp_executesql @SQL
-- Update U, V, S, T for first and last nodes
-- Strictly speaking, it's not required because spInitializeS will be called next
IF @I = 1 UPDATE dbo.LeftNodes SET U = 0, S = 1 WHERE LeftNode = @LeftNode
IF @I = @Count - 1 UPDATE dbo.RightNodes SET V = 0, T = 1 WHERE RightNode = @RightNode
SET @I = @I + 1 -- Go to next node
SET @S = 1 - @S -- Change add to delete or vice versa
END
/*
Normal return
*/
RETURN 1
END
Installation
The resource section contains a script to install the stored procs, along with the following test script to randomly generate bipartite graphs before seeking a perfect match:
-- Declarations
DECLARE @Result int
DECLARE @Result1 int
DECLARE @Result2 int
DECLARE @Result3 int
-- No counting
SET NOCOUNT ON
-- Build random bipartite graph with selected number of left nodes
-- and probability for edge creation.
-- Disable this section if you've built your own bipartite graph
EXEC @Result = spBuildBipartite 10, 0.25
IF @Result <> 1 RETURN
-- Check that graph is bipartite
-- This is only required if a manually created graph is used
-- Enable this section if you've built your own bipartite graph
-- EXEC @Result = spCheckBipartite
-- IF @Result <> 1 RETURN
--Apply greedy algorithm to get partial matching
EXEC @Result = spGreedy
IF @Result <> 1 RETURN
-- Initialize U, V, S, T, Path
EXEC @Result = spInitializeS
-- Attempt to find perfect matching
-- For each loop, at least one of M or S will expand or no perfect match exists
WHILE 1 = 1
BEGIN
-- Repeatedly expand M with a new edge until it fails
-- Whenever successful: U, V, S, T, Path must be re-initialized
SET @Result1 = 1
SET @Result2 = 1
WHILE @Result1 = 1
BEGIN
EXEC @Result1 = spExpandM
IF @Result1 = 1
BEGIN
EXEC @Result2 = spInitializeS
IF @Result2 = 0 RETURN -- spExpandM may have just built a perfect match
END
END
-- Expand S
-- Expanding M has just failed so if expanding S fails, no perfect matching exists
-- If expanding S succeeds, try expanding M again
EXEC @Result3 = spExpandS
IF @Result3 <> 1 RETURN
END
The stored proc spBuildBipartite accepts two parameters (number of left nodes, probability of edge creation):
EXEC @Result = spBuildBipartite 10, 0.25
For larger values of the first parameter, you’ll want smaller values of the second if you wish to find graphs with no perfect match. Note that processing a large graph with, say, 1000 left nodes may run for 15-30 minutes on a fast machine if the probability of edge creation is at least 25%. For small probabilities, expect a long run. Use the query SELECT count(*) FROM dbo.Graph WHERE M = 1 to monitor the script’s progress. Note that the expansion of M slows down as the script proceeds.
If you disable this command the script will use the current graph tables, so you can run it on your own data. For that reason, the proc spCheckBipartite is available to check that your data represents a bipartite graph with an equal number of left and right nodes.
Remarks
This script provides a reason whenever a bipartite graph fails to have a perfect match: it finds a collection of left nodes with fewer neighbors than the collection itself (so no matching could exist for that collection). This confirms Hall’s theorem [3]: A bipartite graph has a perfect match if and only if every collection of left nodes has at least as many neighbors as the collection itself.
Can a machine be trained to spot the reason for any graph with no perfect match? With infinitely-many randomly generated examples, there’s no shortage of training data.
References
[1] Graph Theory https://en.wikipedia.org/wiki/Graph_theory [2] Discrete Mathematics Lovasz, Laszlo https://www.springer.com/gp/book/9780387955841 [3] Hall's marriage theorem https://en.wikipedia.org/wiki/Hall%27s_marriage_theorem