Analyzing Query Plans
-
Hi there
I've been asked to troubleshoot a badly performing proc (recently become an issue). First thing i've done is generate the execution plan - don't do this regularly so could use some assistance. The query plan is broken up into ten Queries, and queries 1 - 9 have Query cost (relative to the batch): 0%, with the final query, Query 10 having query cost relative to the batch as 100%. Does that mean this is the only section of the query plan that I need to focus on? I can ignore the rest? Also whilst Query 1 - 9 have actual graphical objects displayed (so sorts, filters, nested loops, index scans etc) Query 10 only shows the actual SELECT query text and no graphical objects, like so:

Finally - when clicking on the properties of Query 10, I can see that the estimated number of rows to return is 204462000... however when the actual query only returns 900 rows... is that a stats problem?
Any other tips for troubleshooting slow running procs would help! Also for context, it was performing fine a few weeks ago but has now become a problem.
Thanks
Doodles
-
OK my mistake, i wasn't scrolling along far enough for query 10, it was all on the right lower side of the screen. I can now see that the majority of query 10 (which is 100% relative to the batch), is spent on a Sort (85%), with estimated rows 204462000, despite the query only returning 900 rows! T SQL optimisation is definitely not my area so could use any guidance here...
-
I would check the source tables (scans and seeks) as the starting point for tuning. Check the estimates vs actuals at the table level as that is where statistics updates will help.
Next, I'd be looking at what is a scan and what is a seek. A SEEK means that SQL is using the index to find the subset of data that you are requesting. A scan means that SQL is going through ALL rows of the table (may still use an index if it determines that having the data sorted in the way the index is sorting it is important). After that, tuning gets interesting. Just because a query says it is 0% relative to the batch doesn't mean that it isn't the query that should be tuned either. If the preceding queries are getting data to be used by that last one, it MAY help to tune the first 9. And sometimes the Query Cost value isn't accurate.
What I would recommend is to turn on STATISTICS IO and STATISTICS TIME to see which query is running "slow" and how many reads the queries are doing. You also need to figure out what you are trying to improve. I EXPECT it is the query execution time, so STATISTICS TIME is going to be the best bang for your buck combined with the execution plan.
Depending on where this query is being used too can help in how you tune it. For example, if the data is being passed back to an application (such as Excel or pretty much any *.exe program), and you have an ORDER BY in the query, you may benefit from removing the ORDER BY. The application MAY not actually need the data sorted.
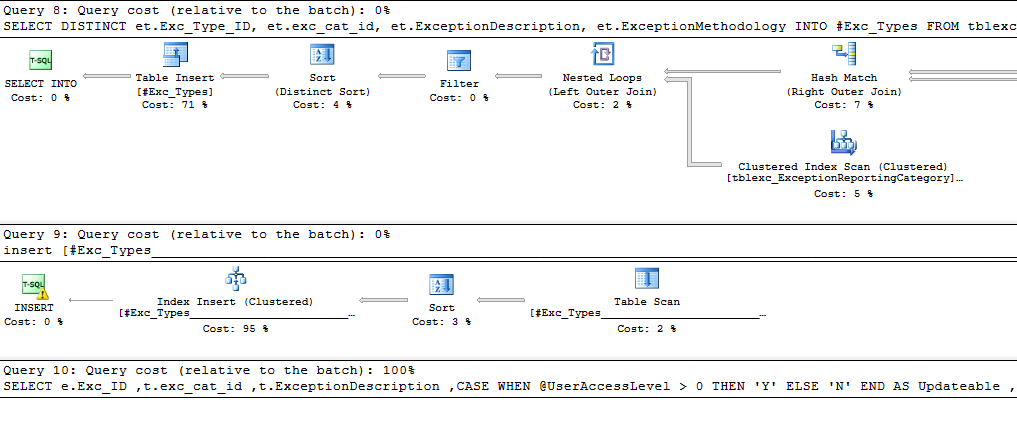
Also, depending on where you are getting your data from can affect performance. For example, if you are using a linked server to get the data, you may be having poor row count estimates of 1. If you are expecting to get roughly 10,000 rows, you will benefit from using OPENQUERY rather than the 4 part naming for example, or you may benefit from putting the data from the linked server into a temp table and tossing an index on it. Looking at the screenshot of the execution plan, you can probably toss an index onto your temporary table used in query 8 to get a performance boost in query 9.
With query 8, if the data set returned is going to be unique, you may be able to remove the DISTINCT (DISTINCT is a performance hurting keyword). BUT if you are getting duplicate rows and there is no better way to reduce (or eliminate) them, then DISTINCT may be required.
But without seeing the execution plan (the full XML of it, not just screenshots) and the query and DDL to recreate the tables with some sample data, it is difficult to help with tuning. If you can't post that (confidential info), then hopefully the above tips can help you with tuning it.
I strongly recommend you start with looking at STATISTICS TIME and STATISTICS IO as they will help determine where the problem lies. I would also do a check to see how much data is in those 900 rows. If it is 8 KB of data in 900 rows, that is 7 MB of data. That isn't a lot, but if you have a slow internet connection, it could be the performance bottleneck. I HIGHLY doubt that is the problem, but I've seen that be the issue before. Not with 900 rows of data mind you.
I would also recommend that you reach out to the end users to determine an acceptable execution time. What I mean is if it is currently running in 30 seconds (made that number up) and that is the first time end users complained, how fast did it run previously? Are you looking to shave off 5 seconds on execution or 29 seconds on execution? The reason I'd ask these questions is it may change your approach. If you need to shave off 29 seconds, you may end up needing to rewrite the entire process and possibly even stage some of the data from those first 9 queries into permanent tables rather than temp tables and refresh them on a cycle or update them with a trigger/stored procedure change. If you need to shave off 5 seconds, it may be as simple as reducing SOME of the data set. What I mean is if you have a table with 1 million rows that it is pulling data from in one of your JOINs, you may be able to add an index to help that join OR you may be able to pull out a subset of the data into a different table variable/temp table to reduce the data set on the JOIN.
And then the best part of all of this - is the slowness on the SQL side or the application side? THAT is a very good reason to ask end users what an acceptable execution time is. If your query is completing in 15 seconds and end users are saying that the 5 minute wait is unacceptable and it needs to be under a minute, getting the query to complete in 0.5 seconds is still meaning that the task is taking 4 minutes and 45.5 seconds to complete.
All of my above advice is based on guesses of your data and how I approach tuning. The above is NOT in any specific order. In general, I try to determine what an "acceptable" timeframe for it to run in is first so I know if I am looking to make it slightly faster or if I am going to need to reinvent the process.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
Thanks Brian for such an extensive reply! I looked through your suggestions and they all sound like good tips. I have spoken to the users and what used to take 30 seconds (ideal response time) is now taking around 3 minutes and sometimes simply times out. So we are aiming for 30 seconds which is a far cry from where we are now! I've refreshed the data on a non prod environment and am getting similar results, so its not environment specific. I've tried rebuilding indexes and updating stats on key databases but again, no significant improvement. FYI, I tried to attach the query plan but it complained it was too big 🙁 The query is really nasty having grown organically over time (it is the backend to a complex SSRS report) but i was hoping to at least try and improve it somewhat my end before handing back to the devs for a possible rewrite...
I have turned on set statistics io and time on the stored proc but i find the output confusing - because there are 10 query batches, i'm struggling to understand which stats apply to which batch. Here's the result:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
(1 row(s) affected)
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
(15 row(s) affected)
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 8563 ms, elapsed time = 12105 ms.
(91759 row(s) affected)
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 12859 ms, elapsed time = 2599 ms.
SQL Server Execution Times:
CPU time = 188 ms, elapsed time = 212 ms.
(0 row(s) affected)
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 2 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 2 ms.
(285 row(s) affected)
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 15 ms, elapsed time = 6 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 2 ms.
(985 row(s) affected)
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 368764 ms, elapsed time = 241100 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 390389 ms, elapsed time = 256037 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
-
My first step when doing the statistics time or IO related analysis is to turn off the execution plan. That is going to skew your information. I would also recommend using SET NOCOUNT ON so you don't get the row counts. Then the ONLY information that will be captured is the information you are trying to look at (statistics time or statistics IO).
That being said, looking at what you posted, there is one chunk in the middle that is taking 12 seconds and then you have your long ones at the end of 241 seconds and 256 seconds. Since those are at the end, those look like they are part of query 10, and the 241 is probably just part of the 256 (execution plan perhaps).
So you are right that tuning query 10 is going to be required to get the query down to 30 seconds again.
The next part that will be helpful is statistics IO. It'll tell you if you are getting a lot of reads from disk. If it is a lot of reads from disk, that could be your performance bottleneck. Alternately, if your query is doing a lot of calculations, that could be the performance bottleneck. But with only 900-ish rows being returned (985 it looks like), it is more likely that a JOIN or WHERE clause is causing the performance hit in which case an index or two may help or possibly reducing the data set prior to query 10. What I mean is in the other long query (12 seconds) you are pulling in 91,000 rows of data. I imagine that is being used in query 10. I expect that queries 1 through 9 are used to prepare data for query 10. If this is correct, reducing that data set MAY help, or building some indexes on the temporary tables may help too.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
It would help if you could show us the queries with information on the number of rows in each table.
Viewing 6 posts - 1 through 6 (of 6 total)
You must be logged in to reply to this topic. Login to reply