

Over the last few years I have been involved in reviewing the architectures of various companies that are building or have built big data solutions. When I say “big data”, I’m referring to the incorporation of semi-structured data such as sensor data, device data, web logs, and social media. The architectures generally fall into four scenarios:
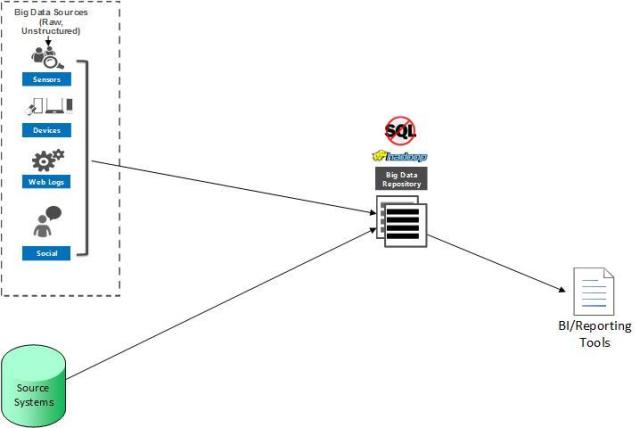
Enterprise data warehouse augmentation
This scenario uses an enterprise data warehouse (EDW) built on a RDBMS, but will extract data from the EDW and load it into a big data hub along with data from other sources that are deemed not cost-effective to move into the EDW (usually high-volume data or cold data). Some data enrichment is usually done in the data hub. This data hub can then be queried, but primary analytics remain with the EDW. The data hub is usually build on Hadoop or NoSQL. This can save costs since storage using Hadoop or NoSQL is much cheaper than an EDW. Plus, this can speed up the development of reports since the data in Hadoop or NoSQL can be used right away instead of waiting for an IT person to write the ETL and create the schema’s to ingest the data into the EDW. Another benefit is it can support data growth faster as it is easy to expand storage on a Hadoop/NoSQL solution instead of on a SAN with an EDW solution. Finally, it can help by reducing the number of queries on the EDW.
This scenario is most common when a EDW has been in existence for a while and users are requesting data that the EDW cannot handle because of space, performance, and data loading times.
The challenges to this approach is you might not be able to use your existing tools to query the data hub, as well as the data in the hub being difficult to understand and join and may not be completely clean.
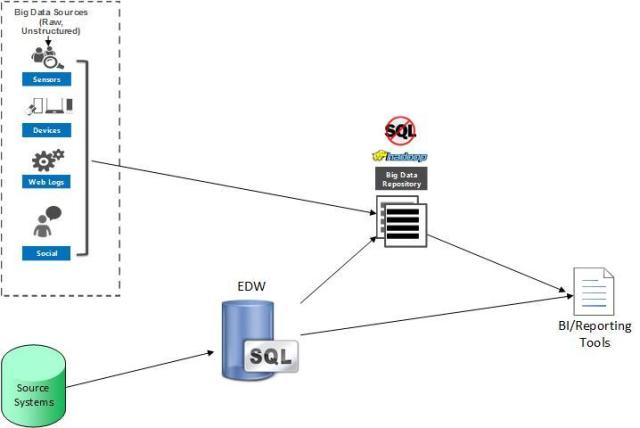
Data hub plus EDW
The data hub is used as a data staging and extreme-scale data transformation platform, but long-term persistence and analytics is performed in the EDW. Hadoop or NoSQL is used to refine the data in the data hub. Once refined, the data is copied to the EDW and then deleted from the data hub.
This will lower the cost of data capture, provide scalable data refinement, and provide fast queries via the EDW. It also offloads the data refinement from the EDW.
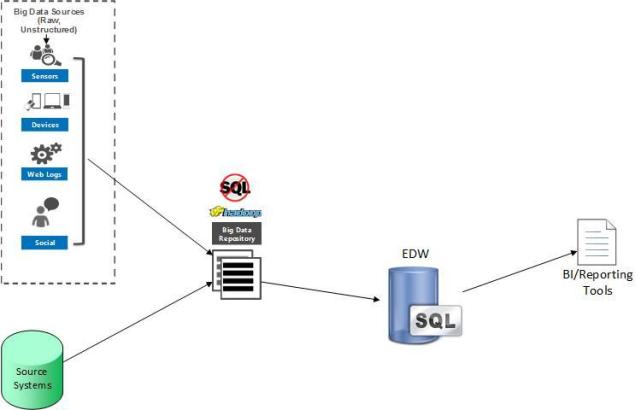
All-in-one
A distributed data system is implemented for long-term, high-detail big data persistence in the data hub and analytics without employing a EDW. Low level code is written or big data packages are added that integrate directly with the distributed data store for extreme-scale operations and analytics.
The distributed data hub is usually created with Hadoop, HBase, Cassandra, or MongoDB. BI tools specifically integrated with or designed for distributed data access and manipulation are needed. Data operations either use BI tools that provide NoSQL capability or low-level code is required (e.g., MapReduce or Pig script).
The disadvantages of this scenario are reports and queries can have longer latency, new reporting tools require training which could lead to lower adoption, and the difficulty of providing governance and structure on top of a non-RDBMS solution.
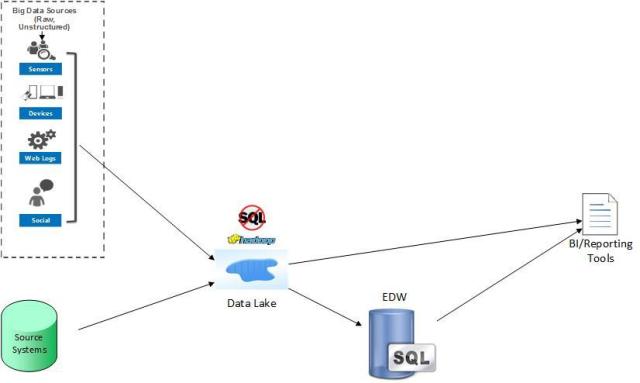
Modern Data Warehouse
An evolution of the three previous scenarios that provides multiple options for the various technologies. Data may be harmonized and analyzed in the data lake or moved out to a EDW when more quality and performance is needed, or when users simply want control. ELT is usually used instead of ETL (see Difference between ETL and ELT). The goal of this scenario is to support any future data needs no matter what the variety, volume, or velocity of the data.
Hub-and-spoke should be your ultimate goal. See Why use a data lake? for more details on the various tools and technologies that can be used for the modern data warehouse.
More info:
Forrester’s Patterns of Big Data
Most Excellent Big Data Questions: Top Down or Bottom Up Use Cases?

![]()
