Snowflake capitalizes on two of the largest trends in technology: the Cloud and Big Data Processing. Snowflake is a cloud-based Online Analytical Processing (OLAP) data warehouse that runs as Software as a Service (SaaS). It can scale to an almost unlimited size and runs seamlessly on all of the major cloud vendors: Amazon Web Services (AWS), Microsoft Azure (Azure), and Google Cloud Platform (GCP).

That might sound very similar to Amazon Redshift, Azure Synapse Analytics, and Google BiqQuery, but Snowflake is available on all three of the cloud providers, which doesn’t lock a customer into a single cloud vendor, allowing flexibility in customer choices. It also has multiple features that are not supported under the other platforms. Examples of these are time travel, no copy cloning, and data sharing.
One of the goals the founders of Snowflake had for their cloud service was to make the platform easy to use and scale without the need for complex configuration and administration. They aimed to build a data platform to harness the power of the cloud and provide companies with ease of access to their data. I will discuss some examples that I have seen at customers and let you decide if these would fit your current scale requirements.
The best part about Snowflake is that it is based on the SQL language, so your SQL knowledge will ease the transition to learning a new cloud data warehouse.
This article will give a general introduction to Snowflake and highlight some of the unique features provided by the service. We will dive into more detail in upcoming articles
History
The three founders behind Snowflake are two data architects, Benoit Dageville and Thierry Cruanes from Oracle, and Marcin Zukowski, a co-founder of Vectorwise. All three have data warehousing expertise. When and where was Snowflake developed?
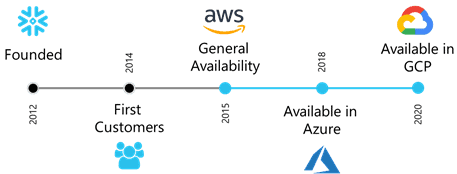
Snowflake was founded in 2012 but worked in stealth mode for the first years of operation. At the time, they had about 80 organizations that were working with them. Snowflake became generally available within AWS in June 2015. Snowflake was made available within Azure in June 2018 and then within Google Cloud Platform in January 2020.
Snowflake Architecture
Snowflake was not built from an existing platform. It was built from the ground up utilizing public cloud services to build a unique architecture in the cloud.
Snowflake provides a ready to use, out of the box analytic data warehouse service SaaS (Software as a Service). This is a software distribution model where a third-party vendor hosts an application and makes it available to customers. This cloud-based data warehouse is designed to be easier to use, faster, and more flexible than on-premise data warehouses. version because it only uses public cloud components, such as cloud storage and cloud compute.
This means there is no hardware, and no software to install, update, configure, manage, or support. This makes it an ideal solution for organizations who do not want to dedicate resources to managing infrastructure, servers, and hardware. Snowflake is not available in an on-premises version because it only uses public cloud components, such as cloud storage and cloud compute.
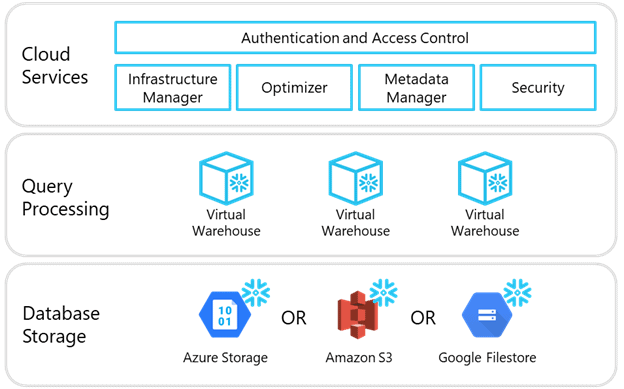
The Snowflake architecture is comprised of three layers in a multi-cluster, shared data service:
- Cloud Services
- Query Processing
- Database Storage
The diagram of services is shown below. These services run in the public cloud provider’s network. Each Snowflake account is provisioned within a region in a cloud provider. A best practice is to choose a cloud provider and region where your business already has services, or one near your data and end users.
Each of these layers is described below.
Cloud Services
The Cloud Services Layer coordinates all of the activities within the Snowflake architecture. It manages authentication and user sessions, configuration, resource management, data protection, optimization, metadata and availability. This layer uses stateless compute resources that run across multiple availability zones, comprising the brains around a Snowflake deployment.
These services seamlessly communicate with client applications, coordinating the processing of queries. Because the Cloud Services layer stores metadata about the data stored within Snowflake, new virtual warehouses in the Query Processing layer will have immediate access to this shared data.
Query Processing
The Query Processing layer is made up of virtual warehouses that perform the processing tasks required to execute queries. Virtual Warehouse is a Snowflake term that translates to cloud compute. Virtual Warehouses are the compute resources for data loading and query processing and can be sized dynamically.
Each warehouse can access all of the data within the underlying Database Storage layer and works independently. Because there is no competition between warehouses, the work of one warehouse does not affect processes or queries from another warehouse. Compute resources can thus scale up or out, and automatically or on demand, without having to rebalance data loads in the Database Storage layer.
Database Storage
The Database Storage layer resides in a cloud storage service, such as Amazon S3 and contains all of the data loaded into Snowflake tables, which can include structured and semi structured data. Virtual Warehouses from the Query Processing layer have access to any database within the Database Storage layer as long as permissions have been granted. Scaling and availability are provided without management by customers. The Snowflake storage is only accessible from a Snowflake Virtual Warehouse using SQL commands.
Snowflake optimizes any internally stored data in data tables into a compressed, columnar format structure called a micro-partition. Snowflake also manages the organization, file size, compression, metadata and statistics of these micro-partitions for you. These micro-partitions are similar to data pages in SQL Server.
Unique Features
There are some interesting features unique to Snowflake that are not available in other platforms. These unique features solve use cases that were always a problem in the past. We will highlight three of them in this article and will discuss the others in detail in later articles.
- Time Travel
- Zero Copy Cloning
- Data Sharing
These exciting features differentiate Snowflake from other cloud databases and can provide a huge benefit to clients. Each is described briefly below.
Time Travel
To understand Time Travel we will need to explain some additional details about Snowflake tables and micro-partitions.
A micro-partition’s underlying storage structure is immutable which means the data is not able to be changed. When data in an existing micro-partition is updated, a new micro-partition with the new data is created. The original micro-partition is left unchanged. The table metadata is updated to point to the new micro-partition and any of the original micro-partitions that were not changed.
An example might make this easier to understand.
Let’s start with a table that was created with “X” days of time travel and has two micro-partitions: #1 and #2.
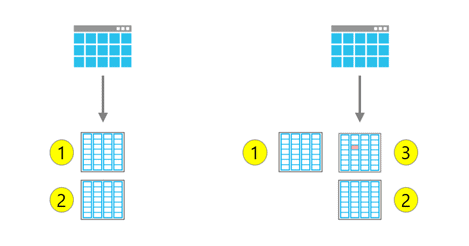
An update statement is executed on the table that would update micro-partition #1. Because all micro-partitions are immutable, a new third micro-partition is created. The table metadata now points to micro-partition #2 and #3 as the current state of the table.
Time Travel is the ability to go back to older micro-partitions like #1 in the above example and see the what the table looked like prior to the update.
In Snowflake, there are three different table types: temporary, transient, and permanent. The main difference is how long data for a table is stored. We will dive deeper into this topic in a following article, but the basics of table storage are as follows:
- temporary – maintained for the duration of the session with limited time travel of 1 day
- transient – permanent table with limited time travel of 1 day
- permanent – permanent table with time travel from 0 - 90 days
The table type defines the storage lifetime of micro-partitions that are not part of the current table. In the example above, micro-partition #1 is stored for “X” days after the update. This is because it is no longer considered part of the current table.
If a DROP TABLE statement is run on the scenario above, the table metadata that points to all three micro-partitions is removed. The partitions will still exist for “X” days after the DROP TABLE statement is executed. To restore the table, you can simply run an UNDROP TABLE statement before the end of the Time Travel retention period.
Zero Copy Cloning
Another feature that differentiates Snowflake from other cloud databases is the notion of a Zero Copy Clone. In other database systems, making a copy of a table, or cloning it, will create an additional physical copy of the table, doubling the storage space. When you copy a table in Snowflake, the system will just store a pointer to the original table.
In essence, it makes a copy of the table only at the metadata level. Since the copy is only at the metadata level, the data itself is not duplicated, but it still appears as two different tables to the user. You are then able to interact with each table independently. When you make a change to the cloned table, Snowflake will store the new micro-partitions with the updates and reference any micro-partitions that didn’t change.
In the example below the gray table is a clone of the original blue table. They share micro-partitions #1 and #2. If an update is run against the gray cloned table that changes micro-partition #1 an new micro-partition is created and the cloned table now points to micro-partition #2 and #3. The original blue table still points to micro-partition #1 and #2 and was not affected.
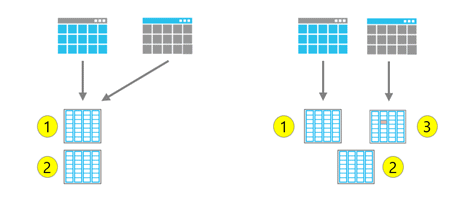
Cloned tables also provide a huge savings in storage costs by not storing duplicated data.
Data Sharing
What is the most common feature that is exists in almost all the reporting tools? Export to Excel.
Snowflake was built with Data Sharing in mind without the need to export to Excel. The architecture enables enterprise data sharing among any data consumer, regardless of whether that consumer is a Snowflake customer. Data providers (Snowflake customer that share data) can enable live, ready-to-use data from their account to any other data consumer. This gives instant access without moving or copying the data, and without having to share spreadsheets.
Snowflake’s data sharing enables companies to distribute data across the enterprise, across business units, with business partners, and with external enterprises without the cost/hassle of paying to store duplicated data. When a provider creates a share, a consumer can query the data with any tool that can connect to Snowflake.
Data Sharing is accomplished without additional costs of duplicating infrastructure to store additional copies of data
Summary
Snowflake was not built from an existing platform. It was built from the ground up utilizing public cloud services to build a unique architecture in the cloud. With a focus on data-centric, low storage cost, easy access, elasticity, high availability, and ease of maintenance in mind it is an easy database platform to get up and working.
Next Article
In the follow up article we will discuss setup and configuration.