Visual studio 2019- Better performance to load 6.5 million record from flat file
-
Visual studio 2019- Better performance to load 6.5 million record from flat file to ole db destination (i.e. database table in ssms 2019)
What is the scenario:
I am using Visual studio 2019 to load data from flat files (txt files) to database tables in SSMS 2019. These tables are Staging tables.
I have 10 text files and need to make one package per file to load data in 10 different tables (staging) dedicated to each file.
This is a requirement of my task.
I am able to do it successfully. All packages have a fairly fast execution time except one in which the text file has around 6.5 million records and the package execution time to load the data into db table is 2 minutes 30 seconds.
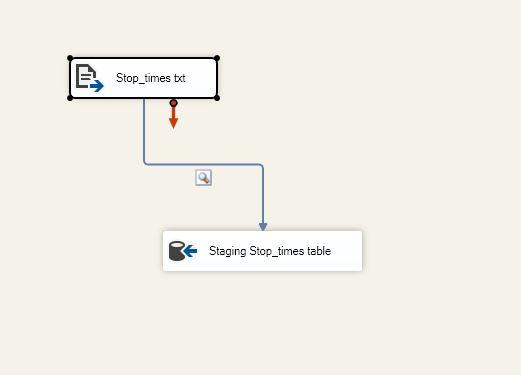
For this task, I have used a Data Flow Task which contains :
1. Flat file Source - This contains the file from which data has to be loaded.
2. OLE DB Destination- For the database table to which data has to be loaded.
(attached screenshot for reference)

3. OLE DB Destination Editor-
Data access mode- Table or view -fast load,
Custom properties- Access Mode: OpenRowset Using FastLoad
What do I wish to achieve ? :
I want to improve the performance of this package to reduce the execution time as much as possible.
I can provide more details if required.
Please advise.
Thank you.
-
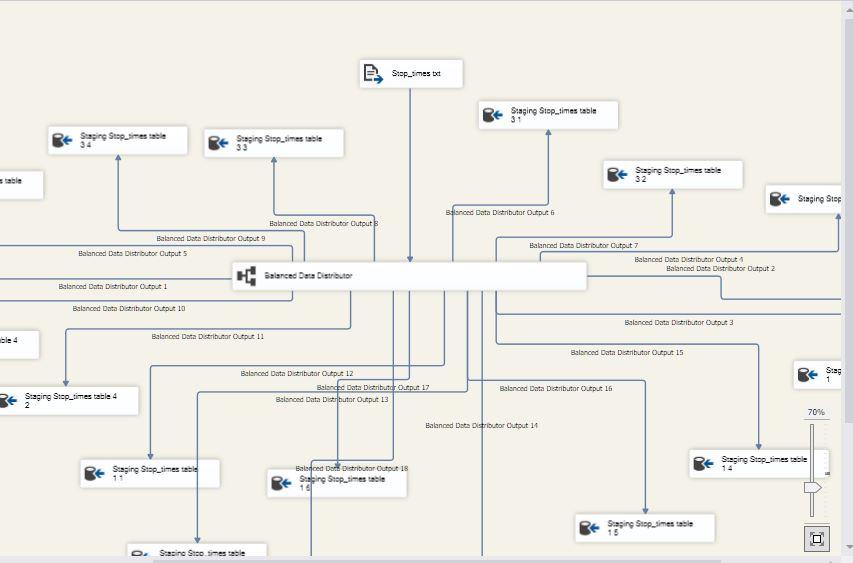
I tried with Balanced Data Distributor and now the elapsed time is 50 seconds. Screenshots attached
But I had to create 30-32 branches as shown in the screenshot which is inconvenient. There must be a better way to do this.
Please advise.
-
What are the batch/commit settings on the destination? If those are default - set them to a reasonable amount and see if that improves the performance any. In some cases...the load takes much longer with those default settings because all 6.5 million rows are committed in a single batch.
Other things you can look at are buffer settings and other performance specific improvements.
Changing to the SQL Server destination instead of using OLEDB might also improve performance.
With that said - why is 2.5 minutes too long? How often will you be loading this data - and what other processing of the data is required that requires the load to take less than a minute? I understand wanting to get it running as fast and efficiently as possible - but at some point you need to look at how much development time is being used - and whether that time and effort is spent on the right performance improvements.
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
those 2.5 mins are on your pc - how long does it take to run on the server?
and on top of what Jeffrey said - set the packet size to its max - this will be on the connection string or properties window.
see https://merlecarr.wordpress.com/2013/09/09/ssis-tuningpacket-size/
-
Hello @Jeffrey Williams,
Thanks a lot for your advice and suggestions. It helped me immensely. I did iterations for different combinations of DefaultBufferSize, DefaultBufferMaxRows and the number of output paths from the 'Balanced Data Distributor' (screenshot attached). Now the package executes in 15 seconds.
-
I think you missed the new AutoAdjustBufferSize setting - this setting should auto adjust the buffer size as needed instead of you having to figure it all out.
Looking at what you have done...I still have to ask, why do you need this done in 15 seconds? It is great that you got it to run that fast - but is it really necessary? You now have a very complex solution that is going to be much harder to manage and maintain and have spent quite a bit of time engineering the solution...was that time well spent and worth it?
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
@Jeffrey Williams
Actually this is an SSIS solution consisting of 10 packages run by a master package. The functionality currently in place is Truncate and ReLoad of staging tables from the source data (text files) to sql server database tables. Further, transformations (SCD type1,2,3) would be applied to the output of these packages and data would be refined and loaded to 'dbo' schema database tables. Since, adding more transformations would add on to the execution time of the packages, I wanted the initial stage of execution to be as quick as possible. Hence the time spent. Please add on further to my knowledge if I understood it right/ took the right approach ?
-
To respond to your previous statement, initially after you suggested, I used the AutoAdjustBufferSize setting (set it to True) which by default gave me DefaultBufferMaxRows= 10000 and DefaultBufferSize= 10MB. which helped to reduce the execution time to 25 seconds.
(P.S. Performing the same on macbook resulted in execution of the package within 5-10 seconds. Performance/limitations depends overall on the PC specifications ? )
- Jimmy@buster wrote:
@Jeffrey Williams
Actually this is an SSIS solution consisting of 10 packages run by a master package. The functionality currently in place is Truncate and ReLoad of staging tables from the source data (text files) to sql server database tables. Further, transformations (SCD type1,2,3) would be applied to the output of these packages and data would be refined and loaded to 'dbo' schema database tables. Since, adding more transformations would add on to the execution time of the packages, I wanted the initial stage of execution to be as quick as possible. Hence the time spent. Please add on further to my knowledge if I understood it right/ took the right approach ?
Have a look on this thread:
Does the original problem sound familiar?
See what I suggested and how did it work out for the OP.
In most cases the right approach to "Truncate and ReLoad" problem is not to do Truncate and ReLoad.
Especially when you're reloading millions or rows.
_____________
Code for TallyGenerator -
It is good that you are able to get the processing down to 15 seconds...but I am concerned at the cost that will have on maintenance of this solution. The complexity involved in just loading the data - with the adjustments made to default buffer sizes and max rows could easily become an issue if (when) something changes - either more data in the file, hardware changes, etc...
Further to that - how often does this run? Is this something that runs once a day - once a week or longer? If this is part of a larger package, how long does the total package take? A good example is a package that takes 20 minutes to execute in total...where this package is added and runs concurrently - saving 2 minutes isn't going to change the overall time of the package.
And finally - who is going to maintain this solution? The more complex you make it - the harder it is for anyone else to figure out what it is doing and maintain it.
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
This runs every Monday via sql agent job scheduler.
If this is part of a larger package, how long does the total package take?
It is actually one of the 10 child packages which are run by a master package. The master package takes around 10-15 minutes (time varies at different times). I implemented the master package in 2 ways of which I too have a question while implementing in one of the ways for which I'll post a question as well.
Viewing 11 posts - 1 through 11 (of 11 total)
You must be logged in to reply to this topic. Login to reply