


This is the fourth article in my series about learning how to use SQL Server 2016's new JSON functions. If you haven't already, you can read Part 1?—?Parsing JSON, Part 2?—?Creating JSON, and Part 3?—?Updating, Adding, and Deleting JSON.
- Part 1?—?Parsing JSON
- Part 2?—?Creating JSON
- Part 3?—?Updating, Adding, and Deleting JSON
- Part 4?—?JSON Performance Comparison
Additional performance comparisons available in an updated post.
We've finally come to my favorite part of analyzing any new software feature: performance testing. SQL Server 2016's new JSON functions are great for parsing JSON data, creating JSON data, and modifying JSON data, but are they efficient?
Today we'll examine three areas of SQL Server JSON performance:
- How to maximize performance for the new SQL Server JSON functions
- How the new SQL Server JSON functions compare against what was previously available in SQL Server
- How the new SQL JSON functions compare against Newtonsoft's Json.NET
Maximizing SQL Server JSON Function Performance
I wanted to use a sizable data set in order to test the performance of the new JSON functions in SQL Server 2016. I found arthurkao's car year/make/model data on GitHub and decided this ~20k element JSON array would be perfect for performance testing purposes. For my tests I'll be using both the original JSON string as well as a SQL table that I created from the original JSON array:
-- Car data source: https://github.com/arthurkao/vehicle-make-model-data
IF OBJECT_ID('dbo.Cars') IS NOT NULL
BEGIN
DROP TABLE dbo.Cars;
END
CREATE TABLE dbo.Cars
(
Id INT IDENTITY(1,1),
CarDetails NVARCHAR(MAX)
);
-- See https://gist.github.com/bertwagner/1df2531676112c24cd1ab298fc750eb2 for the full untruncated version of this code
DECLARE @cars nvarchar(max) = '[ {"year":2001,"make":"ACURA","model":"CL"}, {"year":2001,"make":"ACURA","model":"EL"},...]';
INSERT INTO dbo.Cars (CarDetails)
SELECT value FROM OPENJSON(@cars, '$');
SELECT * FROM dbo.Cars;
/*
Output:
Id CarDetails
----------- ----------------------------------------------
1 {"year":2001,"make":"ACURA","model":"CL"}
2 {"year":2001,"make":"ACURA","model":"EL"}
3 {"year":2001,"make":"ACURA","model":"INTEGRA"}
...
*/
Unlike XML in SQL Server (which is stored in it's own datatype), JSON in SQL Server 2016 is stored as an NVARCHAR. This means instead of needing to use special indexes, we can use indexes that we are already familiar with.
To maximize performance, we can use Microsoft's recommendation of adding a computed column for one of the JSON properties and then indexing that computed column:
-- Remember to turn on "Include Actual Execution Plan" for all of these examples
-- Before we add any computed columns/indexes, let's see our execution plan for our SQL statement with a JSON predicate
SELECT * FROM dbo.Cars WHERE JSON_VALUE(CarDetails, '$.model') = 'Golf'
/*
Output:
Id CarDetails
----------- --------------------------------------------------
1113 {"year":2001,"make":"VOLKSWAGEN","model":"GOLF"}
2410 {"year":2002,"make":"VOLKSWAGEN","model":"GOLF"}
3707 {"year":2003,"make":"VOLKSWAGEN","model":"GOLF"}
...
*/
-- The execution plan shows a Table Scan, not very efficient
-- We can now add a non-persisted computed column for our "model" JSON property.
ALTER TABLE dbo.Cars
ADD CarModel AS JSON_VALUE(CarDetails, '$.model');
-- We add the distinct to avoid parameter sniffing issues.
-- Our execution plan now shows the extra computation that is occuring for every row of the table scan.
SELECT DISTINCT * FROM dbo.Cars WHERE JSON_VALUE(CarDetails, '$.model') = 'Golf'
SELECT DISTINCT * FROM dbo.Cars WHERE CarModel = 'Golf'
Non-persisted computed columns (like in the example above) do not take up any additional space in the table. You can verify this for yourself by running sp_spaceused 'dbo.Cars' before and after adding the non-persisted column to the table.
Having a computed column doesn't add any performance to our query on its own but it does now allow us to add an index to our parsed/computed JSON property.

The clustered index that we add next stores pointers to each parsed/computed value causing the table not to take up any space and only causes the SQL engine to recompute the columns when the index needs to be rebuilt:
-- Add an index onto our computed column
CREATE CLUSTERED INDEX CL_CarModel ON dbo.Cars (CarModel)
-- Check the execution plans again
SELECT DISTINCT * FROM dbo.Cars WHERE JSON_VALUE(CarDetails, '$.model') = 'Golf'
SELECT DISTINCT * FROM dbo.Cars WHERE CarModel = 'Golf'
-- We now get index seeks!
And the resulting execution plan now shows both queries (the one using JSON_VALUE() in the WHERE clause directly as well the one calling our computed column) using index seeks to find the data we are looking for:

Overall, adding computed columns to our table adds no overhead in terms of storage space and allows us to then add indexes on JSON properties which improve performance significantly.
SQL Server 2016 JSON vs SQL Server pre-2016 JSON
As I've mentioned before, the best option for processing JSON data in SQL Server before 2016 was by using Phil Factor's amazing JSON parsing function. Although the function works well, it is limited by what SQL Server functionality was available at the time and therefore wasn't all that efficient.
-- Let's compare how quick Phil Factor's JSON parsing function does against the new SQL 2016 functions
-- Phil's parseJSON function can be downloaded from https://www.simple-talk.com/sql/t-sql-programming/consuming-json-strings-in-sql-server/
SELECT years.StringValue AS Year, makes.StringValue AS Make, models.StringValue AS Model FROM dbo.parseJSON(@cars) models
INNER JOIN dbo.parseJSON(@cars) years ON models.parent_ID = years.parent_ID
INNER JOIN dbo.parseJSON(@cars) makes ON models.parent_ID = makes.parent_ID
WHERE models.NAME = 'model' AND models.StringValue = 'Golf' AND years.NAME = 'year' AND makes.NAME = 'make'
The above query should work for getting the data we need. I'm abusing what the parseJSON function was probably built to do (I don't think it was intended to parse ~20k element JSON arrays), and I'll be honest I waited 10 minutes before killing the query. Basically, trying to parse this much data in SQL before 2016 just wasn't possible (unless you wrote CLR).
Compared to the following queries which is using our indexed computed column SQL Server 2016 is able to return all of the results to us in 1 ms:
-- Indexed computed column returns results in ~1ms
SELECT * FROM dbo.Cars WHERE CarModel = 'Golf'
SQL Server 2016 JSON vs Newtonsoft's Json.NET
In cases like the above where parsing JSON in SQL Server was never an option, my preferred method has always been to parse data in C#. In particular, Newtonsoft's Json.NET is the standard for high performance JSON parsing, so let's take a look at how SQL Server 2016 compares to that.
The following code shows 6 tests I ran in SQL Server 2016:
-- Turn on stats and see how long it takes to parse the ~20k JSON array elements
SET STATISTICS TIME ON
-- Test #1
-- Test how long it takes to parse each property from all ~20k elements from the JSON array
-- SQL returns this query in ~546ms
SELECT JSON_VALUE(value, '$.year') AS [Year], JSON_VALUE(value, '$.make') AS Make, JSON_VALUE(value, '$.model') AS Model FROM OPENJSON(@cars, '$')
-- Test #2
-- Time to deserialize and query just Golfs without computed column + index
-- This takes ~255ms in SQL Server
SELECT * FROM OPENJSON(@cars, '$') WHERE JSON_VALUE(value, '$.model') = 'Golf'
-- Test #3
-- Time it takes to compute the same query for Golf's with a computed column and clustered index
-- This takes ~1ms on SQL Server
SELECT * FROM dbo.Cars WHERE CarModel = 'Golf'
-- Test #4
-- Serializing data on SQL Server takes ~110ms
SELECT * FROM dbo.Cars FOR JSON AUTO
-- What about serializing/deserializing smaller JSON datasets?
-- Let's create our smaller set
DECLARE @carsSmall nvarchar(max) = '[ {"year":2001,"make":"ACURA","model":"CL"}, {"year":2001,"make":"ACURA","model":"EL"}, {"year":2001,"make":"ACURA","model":"INTEGRA"}, {"year":2001,"make":"ACURA","model":"MDX"}, {"year":2001,"make":"ACURA","model":"NSX"}, {"year":2001,"make":"ACURA","model":"RL"}, {"year":2001,"make":"ACURA","model":"TL"}]';
-- Test #5
-- Running our query results in the data becoming deserialized in ~0ms
SELECT JSON_VALUE(value, '$.year') AS [Year], JSON_VALUE(value, '$.make') AS Make, JSON_VALUE(value, '$.model') AS Model FROM OPENJSON(@carsSmall, '$')
--30ms in sql
-- Test #6
-- And serialized in ~0ms
SELECT TOP 7 * FROM dbo.Cars FOR JSON AUTO
And then the same tests in a C# console app using Json.Net:
static void Main(string[] args)
{
string cars = @"[ {""year"":2001,""make"":""ACURA"",""model"":""CL""}, ... ]";
Stopwatch stopwatch = new Stopwatch();
// Test #1
stopwatch.Start();
var deserializedCars = JsonConvert.DeserializeObject<IEnumerable<Car>>(cars);
stopwatch.Stop();
long elapsedMillisecondsDeserialize = stopwatch.ElapsedMilliseconds;
// Test #2 & #3
stopwatch.Restart();
var queriedCars = JsonConvert.DeserializeObject<IEnumerable<Car>>(cars).Where(x=>x.model == "Golf");
stopwatch.Stop();
long elapsedMillisecondsQuery = stopwatch.ElapsedMilliseconds;
// Test #4
stopwatch.Restart();
var serializedCars = JsonConvert.SerializeObject(deserializedCars);
stopwatch.Stop();
long elapsedMillisecondsSerialize = stopwatch.ElapsedMilliseconds;
// smaller data
string carsSmall = @"[ {""year"":2001,""make"":""ACURA"",""model"":""CL""}, {""year"":2001,""make"":""ACURA"",""model"":""EL""}, {""year"":2001,""make"":""ACURA"",""model"":""INTEGRA""}, {""year"":2001,""make"":""ACURA"",""model"":""MDX""}, {""year"":2001,""make"":""ACURA"",""model"":""NSX""}, {""year"":2001,""make"":""ACURA"",""model"":""RL""}, {""year"":2001,""make"":""ACURA"",""model"":""TL""}]";
// Test #5
stopwatch.Restart();
var deserializedCarsSmall = JsonConvert.DeserializeObject<IEnumerable<Car>>(carsSmall);
stopwatch.Stop();
long elapsedMillisecondsDeserializeSmall = stopwatch.ElapsedMilliseconds;
// Test #6
stopwatch.Restart();
var serializedCarsSmall = JsonConvert.SerializeObject(deserializedCarsSmall);
stopwatch.Stop();
long elapsedMillisecondsSerializeSmall = stopwatch.ElapsedMilliseconds;
}
And the results compared side by side:
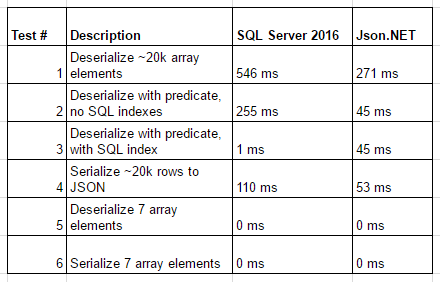
Essentially, it seems like Json.Net beats SQL Server 2016 on larger JSON manipulations, both are equal with small JSON objects, and SQL Server 2016 has the advantage at filtering JSON data when indexes are used.
Conclusion
SQL Server 2016 is excellent at working with JSON. Even though Json.NET beats SQL Server 2016 at working with large JSON objects (on the magnitude of milliseconds), SQL Server is equally fast on smaller objects and is advantageous when JSON data needs to be filtered or searched.
I look forward to using the SQL Server 2016 JSON functions more in the future, especially in instances where network I/O benefits me to process JSON on the SQL Server or when working with applications that cannot process JSON data, like SQL Server Reporting Services.