High buffer size for a table could mean either it has incorrect indexes or ?
-
or simply that the table is USED A LOT, right?
-- Breaks down buffers used by current database by object (table, index) in the buffer cache (Query 51)
SELECT OBJECT_NAME(p.[object_id]) AS [ObjectName],
p.index_id, COUNT(*)/128 AS [Buffer size(MB)], COUNT(*) AS [BufferCount],
p.data_compression_desc AS [CompressionType]
FROM sys.allocation_units AS a WITH (NOLOCK)
INNER JOIN sys.dm_os_buffer_descriptors AS b WITH (NOLOCK)
ON a.allocation_unit_id = b.allocation_unit_id
INNER JOIN sys.partitions AS p WITH (NOLOCK)
ON a.container_id = p.hobt_id
WHERE b.database_id = CONVERT(int,DB_ID())
AND p.[object_id] > 100
GROUP BY p.[object_id], p.index_id, p.data_compression_desc
ORDER BY [BufferCount] DESC OPTION (RECOMPILE);
-- Tells you what tables and indexes are using the most memory in the buffer cache
-- ======buffer cache /memory by onjects in current db!
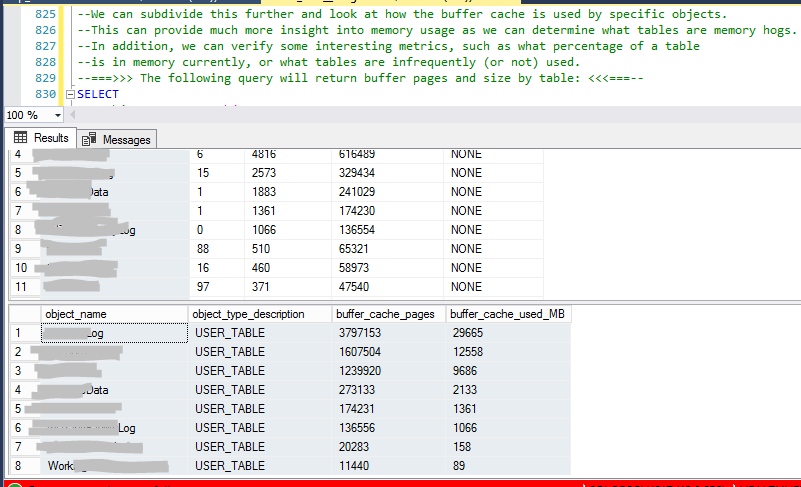
--We can subdivide this further and look at how the buffer cache is used by specific objects.
--This can provide much more insight into memory usage as we can determine what tables are memory hogs.
--In addition, we can verify some interesting metrics, such as what percentage of a table
--is in memory currently, or what tables are infrequently (or not) used.
--===>>> The following query will return buffer pages and size by table: <<<===--
SELECT
objects.name AS object_name,
objects.type_desc AS object_type_description,
COUNT(*) AS buffer_cache_pages,
COUNT(*) * 8 / 1024 AS buffer_cache_used_MB
FROM sys.dm_os_buffer_descriptors
INNER JOIN sys.allocation_units
ON allocation_units.allocation_unit_id = dm_os_buffer_descriptors.allocation_unit_id
INNER JOIN sys.partitions
ON ((allocation_units.container_id = partitions.hobt_id AND type IN (1,3))
OR (allocation_units.container_id = partitions.partition_id AND type IN (2)))
INNER JOIN sys.objects
ON partitions.object_id = objects.object_id
WHERE allocation_units.type IN (1,2,3)
AND objects.is_ms_shipped = 0
AND dm_os_buffer_descriptors.database_id = DB_ID()
GROUP BY objects.name,
objects.type_desc
ORDER BY COUNT(*) DESC;

Likes to play Chess
-
To complete the sentence you started in the title... "Crap Code" consisting of a lot or just a few common problems, insufficient indexes, improper joins, incorrect criteria, poor table/database design (including poor choices of especially clustered indexes), poor data design, a whole lot more that cause index scans or table scans (heaps), out of date statistics, index page density (physical fragmentation), deletes, too-low fill factors, and optimizer choice based on row counts and statistical wims, to name a few.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 2 posts - 1 through 2 (of 2 total)
You must be logged in to reply to this topic. Login to reply