Clustered Indexes on GUIDS, Complex chains of triggers and Heaps
-
I've not posted DDL here because it's a fairly general question.
We have a bit of a bogey database with what I think are some some questionable choices. It's behind a third party CMDB product, so options are limited for change. I've not really paid it too much attention because it's not "user" facing, just the small IT team and it works "ok".
They have recommended that we use their "Built in" archiving (the application creates a new archive DB every time it's run) to help improve performance. I am trying to resist this. The most used part of the CMDB is "incidents" - I don't think a database which contains only ~170,000 rows in the "incidents" table should really have any performance problems. It will also make the custom reports I run from it a bloody nightmare.
While doing a simple update of ~200 rows in the "persons" table (~4000) rows the other day, there was a massive delay - I canceled the query at 2 Mins. That is when I found the massively long and complex INSTEAD OF trigger, complete with IFs for every column and separate inserts into the "history" audit table, which in turn has its own (slightly less complex) triggers.
My main question is: the history table is a heap. Is this such a bad thing in this case? Do I understand correctly that I will not encounter the dreaded forwarded records because rows are never updated, only inserted. It still does not feel right to me, but this alone shouldn't be the cause of slow updates to the tables it is "auditing" should it? Far more likely to be the massive triggers.
The other thing is, all the other tables have clustered indexes on the GUID PKs, so I am reading and re-reading Jeff's comments here: https://www.sqlservercentral.com/forums/topic/index-fragmentation-42#post-3791454 until I am sure I have a real understanding of the rights and wrongs of Fill Factor and when to use it.
"Knowledge is of two kinds. We know a subject ourselves, or we know where we can find information upon it. When we enquire into any subject, the first thing we have to do is to know what books have treated of it. This leads us to look at catalogues, and at the backs of books in libraries."
— Samuel Johnson
I wonder, would the great Samuel Johnson have replaced that with "GIYF" now? -
First things, first. Tables that use Random GUIDs are a whole different animal that what I was talking about in the post you cited. They are one of the very few scenarios where having a lower Fill Factor actually can prevent page splits and the resulting fragmentation. That is, if they are maintained correctly and what has become the world-wide supposed "Best Practice" for index maintenance )(REORGANIZE between 5 and 30% logical fragmentation and REBUILD above 30%) is actually a "Very Worst Practice" for maintaining Random GUIDs (and other very evenly distributed index keys).
For Random GUIDs, you need to use a Fill Factor of 71, 81, or 91 (depending on your daily insert rates) and REBUILD (NOT Reorganize) when you get to 1% logical fragmentation (the marker for when ALL pages in the Random GUID index are on the verge of all fragmenting). That's the reason for the "1" in the Fill Factor... it's to remind you that you must REBUILD the indexes when they go over just 1% logical fragmentation. Of course, it will also help with "ExpAnsive" updates but "ExpAnsive" updates will cause the 1% fragmentation sooner.
Of course, the exception to the above is if the table is a totally static or very nearly static table, in which case the indexes should be 100% regardless of the datatype.
As far as having the INSTEAD OF trigger, it sounds like the audit table for the trigger is column-based auditing instead of row-based. That, in itself, isn't a problem and the audit trigger WILL necessarily have one IF for every bloody column. The key here is... are all of this IFs hardcoded or have they used some form of dynamic SQL to look at the inserted or deleted logical tables created by the trigger? I'll also state that any form of CLR work in the trigger will have a similar problem.
This is fixable (I've fixed many a trigger in this condition). I need to see the code for the trigger, though, and even if it IS 3rd party code. Because it's an INSTEAD OF trigger, I can almost guarantee they've done a whole lot that totally wrong.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Thanks Jeff. Thorough as always! I cited that thread because it's one of the most comprehensive things I've come across on rebuilding/reorganising in various scenarios, so I stuck it in my favourites when I first read it.
In item3 you mentioned GUIDs, which made my ears prick up when I first read it, precisely because of this database. 🙂
I will get the DDL for an example trigger when I am logged back in.
Do you have any comment on the history heap?
"Knowledge is of two kinds. We know a subject ourselves, or we know where we can find information upon it. When we enquire into any subject, the first thing we have to do is to know what books have treated of it. This leads us to look at catalogues, and at the backs of books in libraries."
— Samuel Johnson
I wonder, would the great Samuel Johnson have replaced that with "GIYF" now? - david.edwards 76768 wrote:
... The other thing is, all the other tables have clustered indexes on the GUID PKs ...
That alone might have made me skip buying the product!
Fillfactor also depends on the row size. For example, if the (avg) row size is 3,500 bytes, only 1 or 2 rows will ever fit on a page, so the fillfactor matters only in that it distinguishes between 1 and 2 rows.
Have you checked whether data compression significantly reduces the size of the table? That option could also get you (much) better performance because of reduced I/O.
Of course if there any poorly-written triggers they will need corrected no matter what else you do.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- david.edwards 76768 wrote:
Do you have any comment on the history heap?
For a history table and with all else, "It Depends".
For example, a heap won't fragment or forward rows waste space (depending on row size, like Scott said) but neither would a CI based on either an IDENTITY column or (better yet), a combination of the pertinent and ever increasing date/time column along with the IDENTITY column to be used as a "uniquifier" (SQL Server REALLY likes unique CIs). They key is, what are the lookups done against the table? Also, since the rows in history/audit tables aren't supposed to ever suffer row updates or deletes, do you see any reason to constantly backup that which will never change or would you rather build some temporally based file groups/files that you can set to READ_ONLY, backup one final time, and never have to back them up again? Keep in mind that these types of tables usually turn out to be the largest tables in any given database.
I just don't know enough about your specific table to say "Ah! Here's what you specifically need to do". 😀 If you could provide the trigger DML and the table DDL, that would be a big help in making more specific recommendations. Of course, you said you'd be able to provide that when next you log in.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
GUIDs are horrendous for clustered indexes. They fragment like crazy. And a guid is always a single key lookup, not a range (at least in my experience), thus a non-clus index is almost as good.
As Jeff said, a datetime plus identity to insure the index is unique (note: NOT identity only!) would almost certainly be a better clustered index for this table. You can keep the guid as a PK, just make it non-clustered.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:
GUIDs are horrendous for clustered indexes. They fragment like crazy.
No sir... that's absolutely NOT correct. In fact, they can go for months without any page splits (not even supposed good ones) but ONLY if they are correctly maintained. The cool part is, that's actually a whole lot easier than you could possible imagine.
Oddly enough, they're what everyone imagines every index operates as but actually doesn't.
ScottPletcher wrote:And a guid is always a single key lookup, not a range (at least in my experience), thus a non-clus index is almost as good.
Heh... to almost every rule there is almost always an exception but I absolutely with agree with the basic premise of that statement which is, they generally suck in a major way when it comes to ranges scans and so your experience is spot on there.
ScottPletcher wrote:As Jeff said, a datetime plus identity to insure the index is unique (note: NOT identity only!) would almost certainly be a better clustered index for this table. You can keep the guid as a PK, just make it non-clustered.
I should have added a strong "It Depends" to my statement. What it depends on is the insert rate of new rows and the rate and timing of "ExpAnsive" updates.
Except for one very rare instance that I've documented in a recent article, INSERTs will always work to fill the page at the logical page at the end of any index that is temporally keyed the same as the temporal inserts into the index. That means that, despite what any assigned Fill Factor is, they will still fill a page to as close to 100% as the row width will allow. They also form a "hot spot" on that last page which can and will limit the speed at which INSERTs from multiple sources can be accomplished. They also fragment much worse than any properly maintained Random GUID index will IF the rows are first inserted and then suffer an "ExpAnsive" update such as a "Modified_By" column being filled from NULL to virtually any value before index maintenance that knocks the page density back down to the Fill Factor.
Properly maintained Random GUID keyed Clustered Indexes don't have either of those problems. Since they almost perfectly random, inserts will be made to pages across all the pages of the index which totally eliminates any "Insert Hot Spots", which makes for incredibly fast inserts. Because of the wide distribution (especially on larger indexes) and with the correct Fill Factor, pages normally don't fill up in such a short time as multiple inserts to a single page will and so you can eliminate all page splits, sometimes for months at a time. The space reserved by the lower fill Factor is not wasted. It's relatively slowing but surely being consumed.
It's also critical to realize that since all of the pages will reach 100% capacity at roughly the same time, you must REBUILD Random GUID keyed indexes as soon as the logical fragmentation on the Random GUID indexes goes over 1% or you'll suffer a massive cascade of bad page splits and all that goes with that. I call these "Low Threshold" Rebuilds. Waiting for 5% or 10% is too late... most of the damage will have been done by then.
It's also critical to understand that using REORGANIZE on Random GUID keyed indexes is a bit light having a shot of whiskey to celebrate sobriety. Since REORGANIZE WILL NOT CREATE NEW PAGES, the critical space above the assigned FILL FACTOR is never emptied and the nearly-as-critical free space below the FILL FACTOR is removed when it is most critically needed. That action actually sets the index up for even worse and perpetual fragmentation starting with the first instant after REORGANIZE has finished trashing in the index. NEVER use REORGANIZE on Random GUID keyed indexes, CI or NCI. It causes more harm than good. In fact, if you don't have the time to do a REBUILD (which is less than it will take for REORGANIZE), then accept the fact that it's going to settle on about a 68% natural FILL FACTOR and, because of it's single row lookups that occur anyway, logical fragmentation is not going to be a concern on such indexes. Not doing REBUILDS also means that you're going to have to tolerate page splits when you could be having none, instead. The page split will definitely be less severe than if you use REORGANIZE... a whole lot less severe.
As proof about not using REORGANIZE, here's an IndexDNA(tm) chart that I made 1 day before defragmentation of a Random GUID keyed index....

... and here's that same index right after using REORGANIZE on it with no additional inserts that have occurred... I defy you to find any of the differences between the two. What you can't see is that REORGANIZE did combine some of the pages to move them closer to the FILL FACTOR, which is a removal of critically need free space just when the index needs it the most.
And there is no good FILL FACTOR for REORGANIZE... notice that the "Brent Line" is the "don't do any index maintenance" line. Its slope is a lot less than any of the weekly growth lines except for the "Baseline", which uses inserts of the GUIDs sequentially.
If you shift to using REBUILDs, then it's difficult to find a bad FILL FACTOR unless it's above about 91%. The large flats in the heavy Blue line are where there was no page growth and no splits. The index wasn't checked every night (daily) but, near the end, was only rebuilding about once every 4.5 weeks on a 123 byte row size CI that received 1000 inserted rows per hour for 10 hours per day. Again, the horizontal flats are where there was zero fragmentation even though 10,000 additional rows we're being added per day.
The bottom line is that, while there may be some very good reasons to not use Random GUIDs, saying that then suffer massive fragmentation is a myth perpetuated by the myth of "Best Practices" and other incorrect knowledge. The use of REORGANIZE vs REBUILD is the only difference between massive fragmentation and virtually no fragmentation. Here's what happens when you apply the same principle to a 24 byte wide NCI that is Random GUID Keyed... no fragmentation for MONTHs (3 different Fill Factors portrayed). This has the same rate of inserts (10,000 rows per day) on a Random GUID keyed NCI and yet we literally go for months with zero fragmentation.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Thanks for the interest in this. If I am slow responding, it's not because I have lost interest! I am just checking on this one that I am not infringing anything by posting DDL, and gathering thoughts to make an intelligent reply with as much relevant info as possible.
I am not quite so intimately familiar with the guts of this DB as I'd like, it's never had much attention because it's not user facing, it works and there's always been something more important to do.
"Knowledge is of two kinds. We know a subject ourselves, or we know where we can find information upon it. When we enquire into any subject, the first thing we have to do is to know what books have treated of it. This leads us to look at catalogues, and at the backs of books in libraries."
— Samuel Johnson
I wonder, would the great Samuel Johnson have replaced that with "GIYF" now? -
Ok, here is DDL from the "persons" table and all six triggers on it. The other tables for incidents, computers, assets etc follow a similar format.
I have also included DDL for the History table (heap) and the one trigger on that.
Apologies for the length of this, I hadn't appreciated the full horror, until I started copying it!
I will caveat here - I sincerely doubt I will make any changes to the design, as mentioned before, it works and performance is adequate, plus is not "real user" facing. But I am grateful for any comments, it's all a valuable learning experience. Any significant changes would nullify our support.
My main reason for posting is to see if I can make a case for not archiving older data, using their built in method which creates multiple databases. I am also hoping to ensure that I do not allow performance problems to creep in through well-intentioned, but wrong "best practice" index maintenance.
This example table gets very few inserts (in the region of 100 per year) and ~500 updates a day (things like speedtest results).
The busiest area of the application is Incidents - the Incidents table follows the same design as the Persons table (table and triggers). Even this only has around 100 inserts a day and a similar number of updates. The only time I see really woeful performance, is if we need to do a batch update (rare - except the aforementioned speed-test results), almost all changes are through the front-end, one record at a time.
The History is useful in the front end, in that it allows an audit trail for things like: which Service Desk operator re-assigned tickets, changed status etc. This history is loaded "on demand" when the history tab (on the person, incident, computer etc record is selected).
CREATE TABLE [dbo].[Persons](
[ID] [uniqueidentifier] NOT NULL,
[Organization_ID] [uniqueidentifier] NULL,
[Location_ID] [uniqueidentifier] NULL,
[Calendar_ID] [uniqueidentifier] NULL,
[Technician] [bit] NOT NULL,
[Address] [nvarchar](max) NULL,
[IM_Address] [nvarchar](50) NULL,
[First_Name] [nvarchar](64) NULL,
[Last_Name] [nvarchar](64) NULL,
[Home_Phone] [nvarchar](64) NULL,
[Mobile_Phone] [nvarchar](64) NULL,
[Notes] [nvarchar](max) NULL,
[Business_Phone] [nvarchar](64) NULL,
[Fax] [nvarchar](64) NULL,
[Job_Title] [nvarchar](64) NULL,
[Title] [nvarchar](64) NULL,
[Address_2] [nvarchar](max) NULL,
[Address_3] [nvarchar](max) NULL,
[Middle_Name] [nvarchar](64) NULL,
[Hourly_Rate] [money] NULL,
[Skill_Level] [nvarchar](50) NULL,
[SMS_Email] [nvarchar](100) NULL,
[Manager_ID] [uniqueidentifier] NULL,
[UDF0001] [nvarchar](4) NULL,
[UDF0003] [nvarchar](8) NULL,
[Service] [bit] NOT NULL,
[UDF0004] [bit] NOT NULL,
[UDF0005] [nvarchar](30) NULL,
[Type_ID] [uniqueidentifier] NULL,
[Status_ID] [uniqueidentifier] NULL,
[Gender_ID] [uniqueidentifier] NULL,
[Birthday] [datetime] NULL,
[Full_Name] [nvarchar](276) NOT NULL,
[OID] [nvarchar](25) NULL,
[Primary_Email] [nvarchar](256) NULL,
[Primary_Login] [nvarchar](520) NULL,
[Picture] [varbinary](max) NULL,
[UDF_Company] [nvarchar](50) NULL,
[UDF_PMS_Dev] [bit] NOT NULL,
[UDF_AnnualLeave] [bit] NOT NULL,
[UDF_AnnualLeave_End] [datetime] NULL,
[UDF_AnnualLeave_Start] [datetime] NULL,
[UDF_DateTimeLastAssigned] [datetime] NULL,
[UDF_LeaveDate] [datetime] NULL,
[UDF_StartDate] [datetime] NULL,
[UDF_AdditionalEquipmentAllocated] [nvarchar](max) NULL,
[UDF_DownloadSpeed] [nvarchar](20) NULL,
[UDF_LastSpeedTest] [datetime] NULL,
[UDF_Ping] [nvarchar](20) NULL,
[UDF_UploadSpeed] [nvarchar](20) NULL,
[ADImport_ID] [nvarchar](max) NULL,
[UDF_Pager] [nvarchar](50) NULL,
[Data_Segment_ID] [uniqueidentifier] NOT NULL,
[UDF_StopAutoAssignToSelf] [bit] NOT NULL,
CONSTRAINT [Persons_PK] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
ALTER TABLE [dbo].[Persons] ADD DEFAULT (newid()) FOR [ID]
GO
ALTER TABLE [dbo].[Persons] ADD DEFAULT (0) FOR [Technician]
GO
ALTER TABLE [dbo].[Persons] ADD DEFAULT (0) FOR [Service]
GO
ALTER TABLE [dbo].[Persons] ADD CONSTRAINT [Persons_UDF0004_Default] DEFAULT (0) FOR [UDF0004]
GO
ALTER TABLE [dbo].[Persons] ADD DEFAULT ((0)) FOR [UDF_PMS_Dev]
GO
ALTER TABLE [dbo].[Persons] ADD DEFAULT ((0)) FOR [UDF_AnnualLeave]
GO
ALTER TABLE [dbo].[Persons] ADD DEFAULT ('{DF39AC82-8CBB-442F-B43F-DD085C8F4128}') FOR [Data_Segment_ID]
GO
ALTER TABLE [dbo].[Persons] ADD DEFAULT ((0)) FOR [UDF_StopAutoAssignToSelf]
GO
ALTER TABLE [dbo].[Persons] WITH CHECK ADD CONSTRAINT [Data_Segment_Persons_FK1] FOREIGN KEY([Data_Segment_ID])
REFERENCES [dbo].[Data_Segments] ([ID])
GO
ALTER TABLE [dbo].[Persons] CHECK CONSTRAINT [Data_Segment_Persons_FK1]
GO
ALTER TABLE [dbo].[Persons] WITH CHECK ADD CONSTRAINT [Gender_Persons_FK1] FOREIGN KEY([Gender_ID])
REFERENCES [dbo].[Gender] ([ID])
GO
ALTER TABLE [dbo].[Persons] CHECK CONSTRAINT [Gender_Persons_FK1]
GO
ALTER TABLE [dbo].[Persons] WITH CHECK ADD CONSTRAINT [Locations_Persons_FK1] FOREIGN KEY([Location_ID])
REFERENCES [dbo].[Locations] ([ID])
GO
ALTER TABLE [dbo].[Persons] CHECK CONSTRAINT [Locations_Persons_FK1]
GO
ALTER TABLE [dbo].[Persons] WITH CHECK ADD CONSTRAINT [Object_Type_Persons_FK1] FOREIGN KEY([Type_ID])
REFERENCES [dbo].[Object_Type] ([ID])
GO
ALTER TABLE [dbo].[Persons] CHECK CONSTRAINT [Object_Type_Persons_FK1]
GO
ALTER TABLE [dbo].[Persons] WITH CHECK ADD CONSTRAINT [Organizational_Units_Persons_FK1] FOREIGN KEY([Organization_ID])
REFERENCES [dbo].[Organizational_Units] ([ID])
GO
ALTER TABLE [dbo].[Persons] CHECK CONSTRAINT [Organizational_Units_Persons_FK1]
GO
ALTER TABLE [dbo].[Persons] WITH CHECK ADD CONSTRAINT [Persons_Persons_FK1] FOREIGN KEY([Manager_ID])
REFERENCES [dbo].[Persons] ([ID])
GO
ALTER TABLE [dbo].[Persons] CHECK CONSTRAINT [Persons_Persons_FK1]
GO
ALTER TABLE [dbo].[Persons] WITH CHECK ADD CONSTRAINT [Status_Persons_FK1] FOREIGN KEY([Status_ID])
REFERENCES [dbo].[Status] ([ID])
GO
ALTER TABLE [dbo].[Persons] CHECK CONSTRAINT [Status_Persons_FK1]
GO
ALTER TABLE [dbo].[Persons] WITH CHECK ADD CONSTRAINT [Work_Calendars_Persons_FK1] FOREIGN KEY([Calendar_ID])
REFERENCES [dbo].[Work_Calendars] ([ID])
GO
ALTER TABLE [dbo].[Persons] CHECK CONSTRAINT [Work_Calendars_Persons_FK1]
GOHere are the six triggers on Persons:
--
-- Triggers for update history table Persons
--
Create trigger [dbo].[Trigger_History_Persons_Update] on [dbo].[Persons]
instead of update
as
begin
set nocount on
-- Field Organization_ID
if Update([Organization_ID])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Organization_ID'),
'Organization_ID',
c_n.[Placement], -- [New_Value]
c_o.[Placement] -- [Old_Value]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join Organizational_Units c_n on c_n.[ID]=n.[Organization_ID]
left outer join Organizational_Units c_o on c_o.[ID]=o.[Organization_ID]
left outer join cfgCustFieldsView cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Organization_ID'
where n.[Organization_ID]<>o.[Organization_ID] or
n.[Organization_ID] IS NULL and o.[Organization_ID] IS NOT NULL or
n.[Organization_ID] IS NOT NULL and o.[Organization_ID] IS NULL
end
-- Field Location_ID
if Update([Location_ID])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Location_ID'),
'Location_ID',
c_n.[Placement], -- [New_Value]
c_o.[Placement] -- [Old_Value]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join Locations c_n on c_n.[ID]=n.[Location_ID]
left outer join Locations c_o on c_o.[ID]=o.[Location_ID]
left outer join cfgCustFieldsView cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Location_ID'
where n.[Location_ID]<>o.[Location_ID] or
n.[Location_ID] IS NULL and o.[Location_ID] IS NOT NULL or
n.[Location_ID] IS NOT NULL and o.[Location_ID] IS NULL
end
-- Field Calendar_ID
if Update([Calendar_ID])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Calendar_ID'),
'Calendar_ID',
c_n.[Name], -- [New_Value]
c_o.[Name] -- [Old_Value]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join Work_Calendars c_n on c_n.[ID]=n.[Calendar_ID]
left outer join Work_Calendars c_o on c_o.[ID]=o.[Calendar_ID]
left outer join cfgCustFieldsView cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Calendar_ID'
where n.[Calendar_ID]<>o.[Calendar_ID] or
n.[Calendar_ID] IS NULL and o.[Calendar_ID] IS NOT NULL or
n.[Calendar_ID] IS NOT NULL and o.[Calendar_ID] IS NULL
end
-- Field Technician
if Update([Technician])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Technician'),
'Technician',
convert(nvarchar(255),n.[Technician]),
convert(nvarchar(255),o.[Technician])
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Technician'
where n.[Technician]<>o.[Technician] or
n.[Technician] IS NULL and o.[Technician] IS NOT NULL or
n.[Technician] IS NOT NULL and o.[Technician] IS NULL
end
-- Field Address
if Update([Address])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Address'),
'Address',
n.[Address],
o.[Address]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Address'
where n.[Address]<>o.[Address] or
n.[Address] IS NULL and o.[Address] IS NOT NULL or
n.[Address] IS NOT NULL and o.[Address] IS NULL
end
-- Field IM_Address
if Update([IM_Address])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'IM_Address'),
'IM_Address',
n.[IM_Address],
o.[IM_Address]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='IM_Address'
where n.[IM_Address]<>o.[IM_Address] or
n.[IM_Address] IS NULL and o.[IM_Address] IS NOT NULL or
n.[IM_Address] IS NOT NULL and o.[IM_Address] IS NULL
end
-- Field First_Name
if Update([First_Name])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'First_Name'),
'First_Name',
n.[First_Name],
o.[First_Name]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='First_Name'
where n.[First_Name]<>o.[First_Name] or
n.[First_Name] IS NULL and o.[First_Name] IS NOT NULL or
n.[First_Name] IS NOT NULL and o.[First_Name] IS NULL
end
-- Field Last_Name
if Update([Last_Name])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Last_Name'),
'Last_Name',
n.[Last_Name],
o.[Last_Name]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Last_Name'
where n.[Last_Name]<>o.[Last_Name] or
n.[Last_Name] IS NULL and o.[Last_Name] IS NOT NULL or
n.[Last_Name] IS NOT NULL and o.[Last_Name] IS NULL
end
-- Field Home_Phone
if Update([Home_Phone])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Home_Phone'),
'Home_Phone',
n.[Home_Phone],
o.[Home_Phone]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Home_Phone'
where n.[Home_Phone]<>o.[Home_Phone] or
n.[Home_Phone] IS NULL and o.[Home_Phone] IS NOT NULL or
n.[Home_Phone] IS NOT NULL and o.[Home_Phone] IS NULL
end
-- Field Mobile_Phone
if Update([Mobile_Phone])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Mobile_Phone'),
'Mobile_Phone',
n.[Mobile_Phone],
o.[Mobile_Phone]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Mobile_Phone'
where n.[Mobile_Phone]<>o.[Mobile_Phone] or
n.[Mobile_Phone] IS NULL and o.[Mobile_Phone] IS NOT NULL or
n.[Mobile_Phone] IS NOT NULL and o.[Mobile_Phone] IS NULL
end
-- Field Notes
if Update([Notes])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Notes'),
'Notes',
n.[Notes],
o.[Notes]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Notes'
where n.[Notes]<>o.[Notes] or
n.[Notes] IS NULL and o.[Notes] IS NOT NULL or
n.[Notes] IS NOT NULL and o.[Notes] IS NULL
end
-- Field Business_Phone
if Update([Business_Phone])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Business_Phone'),
'Business_Phone',
n.[Business_Phone],
o.[Business_Phone]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Business_Phone'
where n.[Business_Phone]<>o.[Business_Phone] or
n.[Business_Phone] IS NULL and o.[Business_Phone] IS NOT NULL or
n.[Business_Phone] IS NOT NULL and o.[Business_Phone] IS NULL
end
-- Field Fax
if Update([Fax])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Fax'),
'Fax',
n.[Fax],
o.[Fax]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Fax'
where n.[Fax]<>o.[Fax] or
n.[Fax] IS NULL and o.[Fax] IS NOT NULL or
n.[Fax] IS NOT NULL and o.[Fax] IS NULL
end
-- Field Job_Title
if Update([Job_Title])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Job_Title'),
'Job_Title',
n.[Job_Title],
o.[Job_Title]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Job_Title'
where n.[Job_Title]<>o.[Job_Title] or
n.[Job_Title] IS NULL and o.[Job_Title] IS NOT NULL or
n.[Job_Title] IS NOT NULL and o.[Job_Title] IS NULL
end
-- Field Title
if Update([Title])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Title'),
'Title',
n.[Title],
o.[Title]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Title'
where n.[Title]<>o.[Title] or
n.[Title] IS NULL and o.[Title] IS NOT NULL or
n.[Title] IS NOT NULL and o.[Title] IS NULL
end
-- Field Address_2
if Update([Address_2])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Address_2'),
'Address_2',
n.[Address_2],
o.[Address_2]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Address_2'
where n.[Address_2]<>o.[Address_2] or
n.[Address_2] IS NULL and o.[Address_2] IS NOT NULL or
n.[Address_2] IS NOT NULL and o.[Address_2] IS NULL
end
-- Field Address_3
if Update([Address_3])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Address_3'),
'Address_3',
n.[Address_3],
o.[Address_3]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Address_3'
where n.[Address_3]<>o.[Address_3] or
n.[Address_3] IS NULL and o.[Address_3] IS NOT NULL or
n.[Address_3] IS NOT NULL and o.[Address_3] IS NULL
end
-- Field Middle_Name
if Update([Middle_Name])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Middle_Name'),
'Middle_Name',
n.[Middle_Name],
o.[Middle_Name]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Middle_Name'
where n.[Middle_Name]<>o.[Middle_Name] or
n.[Middle_Name] IS NULL and o.[Middle_Name] IS NOT NULL or
n.[Middle_Name] IS NOT NULL and o.[Middle_Name] IS NULL
end
-- Field Hourly_Rate
if Update([Hourly_Rate])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Hourly_Rate'),
'Hourly_Rate',
convert(nvarchar(255),n.[Hourly_Rate]),
convert(nvarchar(255),o.[Hourly_Rate])
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Hourly_Rate'
where n.[Hourly_Rate]<>o.[Hourly_Rate] or
n.[Hourly_Rate] IS NULL and o.[Hourly_Rate] IS NOT NULL or
n.[Hourly_Rate] IS NOT NULL and o.[Hourly_Rate] IS NULL
end
-- Field Skill_Level
if Update([Skill_Level])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Skill_Level'),
'Skill_Level',
n.[Skill_Level],
o.[Skill_Level]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Skill_Level'
where n.[Skill_Level]<>o.[Skill_Level] or
n.[Skill_Level] IS NULL and o.[Skill_Level] IS NOT NULL or
n.[Skill_Level] IS NOT NULL and o.[Skill_Level] IS NULL
end
-- Field SMS_Email
if Update([SMS_Email])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'SMS_Email'),
'SMS_Email',
n.[SMS_Email],
o.[SMS_Email]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='SMS_Email'
where n.[SMS_Email]<>o.[SMS_Email] or
n.[SMS_Email] IS NULL and o.[SMS_Email] IS NOT NULL or
n.[SMS_Email] IS NOT NULL and o.[SMS_Email] IS NULL
end
-- Field Manager_ID
if Update([Manager_ID])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Manager_ID'),
'Manager_ID',
c_n.[Full_Name], -- [New_Value]
c_o.[Full_Name] -- [Old_Value]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join Persons c_n on c_n.[ID]=n.[Manager_ID]
left outer join Persons c_o on c_o.[ID]=o.[Manager_ID]
left outer join cfgCustFieldsView cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Manager_ID'
where n.[Manager_ID]<>o.[Manager_ID] or
n.[Manager_ID] IS NULL and o.[Manager_ID] IS NOT NULL or
n.[Manager_ID] IS NOT NULL and o.[Manager_ID] IS NULL
end
-- Field UDF0001
if Update([UDF0001])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'UDF0001'),
'UDF0001',
n.[UDF0001],
o.[UDF0001]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='UDF0001'
where n.[UDF0001]<>o.[UDF0001] or
n.[UDF0001] IS NULL and o.[UDF0001] IS NOT NULL or
n.[UDF0001] IS NOT NULL and o.[UDF0001] IS NULL
end
-- Field UDF0003
if Update([UDF0003])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'UDF0003'),
'UDF0003',
n.[UDF0003],
o.[UDF0003]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='UDF0003'
where n.[UDF0003]<>o.[UDF0003] or
n.[UDF0003] IS NULL and o.[UDF0003] IS NOT NULL or
n.[UDF0003] IS NOT NULL and o.[UDF0003] IS NULL
end
-- Field Service
if Update([Service])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Service'),
'Service',
convert(nvarchar(255),n.[Service]),
convert(nvarchar(255),o.[Service])
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Service'
where n.[Service]<>o.[Service] or
n.[Service] IS NULL and o.[Service] IS NOT NULL or
n.[Service] IS NOT NULL and o.[Service] IS NULL
end
-- Field UDF0004
if Update([UDF0004])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'UDF0004'),
'UDF0004',
convert(nvarchar(255),n.[UDF0004]),
convert(nvarchar(255),o.[UDF0004])
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='UDF0004'
where n.[UDF0004]<>o.[UDF0004] or
n.[UDF0004] IS NULL and o.[UDF0004] IS NOT NULL or
n.[UDF0004] IS NOT NULL and o.[UDF0004] IS NULL
end
-- Field UDF0005
if Update([UDF0005])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'UDF0005'),
'UDF0005',
n.[UDF0005],
o.[UDF0005]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='UDF0005'
where n.[UDF0005]<>o.[UDF0005] or
n.[UDF0005] IS NULL and o.[UDF0005] IS NOT NULL or
n.[UDF0005] IS NOT NULL and o.[UDF0005] IS NULL
end
-- Field Type_ID
if Update([Type_ID])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Type_ID'),
'Type_ID',
c_n.[Type], -- [New_Value]
c_o.[Type] -- [Old_Value]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join Object_Type c_n on c_n.[ID]=n.[Type_ID]
left outer join Object_Type c_o on c_o.[ID]=o.[Type_ID]
left outer join cfgCustFieldsView cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Type_ID'
where n.[Type_ID]<>o.[Type_ID] or
n.[Type_ID] IS NULL and o.[Type_ID] IS NOT NULL or
n.[Type_ID] IS NOT NULL and o.[Type_ID] IS NULL
end
-- Field Status_ID
if Update([Status_ID])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Status_ID'),
'Status_ID',
c_n.[Status], -- [New_Value]
c_o.[Status] -- [Old_Value]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join Status c_n on c_n.[ID]=n.[Status_ID]
left outer join Status c_o on c_o.[ID]=o.[Status_ID]
left outer join cfgCustFieldsView cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Status_ID'
where n.[Status_ID]<>o.[Status_ID] or
n.[Status_ID] IS NULL and o.[Status_ID] IS NOT NULL or
n.[Status_ID] IS NOT NULL and o.[Status_ID] IS NULL
end
-- Field Gender_ID
if Update([Gender_ID])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Gender_ID'),
'Gender_ID',
c_n.[Gender], -- [New_Value]
c_o.[Gender] -- [Old_Value]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join Gender c_n on c_n.[ID]=n.[Gender_ID]
left outer join Gender c_o on c_o.[ID]=o.[Gender_ID]
left outer join cfgCustFieldsView cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Gender_ID'
where n.[Gender_ID]<>o.[Gender_ID] or
n.[Gender_ID] IS NULL and o.[Gender_ID] IS NOT NULL or
n.[Gender_ID] IS NOT NULL and o.[Gender_ID] IS NULL
end
-- Field Birthday
if Update([Birthday])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Birthday'),
'Birthday',
convert(nvarchar(255),n.[Birthday],120),
convert(nvarchar(255),o.[Birthday],120)
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Birthday'
where n.[Birthday]<>o.[Birthday] or
n.[Birthday] IS NULL and o.[Birthday] IS NOT NULL or
n.[Birthday] IS NOT NULL and o.[Birthday] IS NULL
end
-- Field Full_Name
if Update([Full_Name])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Full_Name'),
'Full_Name',
n.[Full_Name],
o.[Full_Name]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Full_Name'
where n.[Full_Name]<>o.[Full_Name] or
n.[Full_Name] IS NULL and o.[Full_Name] IS NOT NULL or
n.[Full_Name] IS NOT NULL and o.[Full_Name] IS NULL
end
-- Field OID
if Update([OID])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'OID'),
'OID',
n.[OID],
o.[OID]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='OID'
where n.[OID]<>o.[OID] or
n.[OID] IS NULL and o.[OID] IS NOT NULL or
n.[OID] IS NOT NULL and o.[OID] IS NULL
end
-- Field Primary_Email
if Update([Primary_Email])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Primary_Email'),
'Primary_Email',
n.[Primary_Email],
o.[Primary_Email]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Primary_Email'
where n.[Primary_Email]<>o.[Primary_Email] or
n.[Primary_Email] IS NULL and o.[Primary_Email] IS NOT NULL or
n.[Primary_Email] IS NOT NULL and o.[Primary_Email] IS NULL
end
-- Field Primary_Login
if Update([Primary_Login])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Primary_Login'),
'Primary_Login',
n.[Primary_Login],
o.[Primary_Login]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Primary_Login'
where n.[Primary_Login]<>o.[Primary_Login] or
n.[Primary_Login] IS NULL and o.[Primary_Login] IS NOT NULL or
n.[Primary_Login] IS NOT NULL and o.[Primary_Login] IS NULL
end
-- Field UDF_Company
if Update([UDF_Company])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'UDF_Company'),
'UDF_Company',
n.[UDF_Company],
o.[UDF_Company]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='UDF_Company'
where n.[UDF_Company]<>o.[UDF_Company] or
n.[UDF_Company] IS NULL and o.[UDF_Company] IS NOT NULL or
n.[UDF_Company] IS NOT NULL and o.[UDF_Company] IS NULL
end
-- Field UDF_PMS_Dev
if Update([UDF_PMS_Dev])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'UDF_PMS_Dev'),
'UDF_PMS_Dev',
convert(nvarchar(255),n.[UDF_PMS_Dev]),
convert(nvarchar(255),o.[UDF_PMS_Dev])
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='UDF_PMS_Dev'
where n.[UDF_PMS_Dev]<>o.[UDF_PMS_Dev] or
n.[UDF_PMS_Dev] IS NULL and o.[UDF_PMS_Dev] IS NOT NULL or
n.[UDF_PMS_Dev] IS NOT NULL and o.[UDF_PMS_Dev] IS NULL
end
-- Field UDF_AnnualLeave
if Update([UDF_AnnualLeave])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'UDF_AnnualLeave'),
'UDF_AnnualLeave',
convert(nvarchar(255),n.[UDF_AnnualLeave]),
convert(nvarchar(255),o.[UDF_AnnualLeave])
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='UDF_AnnualLeave'
where n.[UDF_AnnualLeave]<>o.[UDF_AnnualLeave] or
n.[UDF_AnnualLeave] IS NULL and o.[UDF_AnnualLeave] IS NOT NULL or
n.[UDF_AnnualLeave] IS NOT NULL and o.[UDF_AnnualLeave] IS NULL
end
-- Field UDF_AnnualLeave_End
if Update([UDF_AnnualLeave_End])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'UDF_AnnualLeave_End'),
'UDF_AnnualLeave_End',
convert(nvarchar(255),n.[UDF_AnnualLeave_End],120),
convert(nvarchar(255),o.[UDF_AnnualLeave_End],120)
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='UDF_AnnualLeave_End'
where n.[UDF_AnnualLeave_End]<>o.[UDF_AnnualLeave_End] or
n.[UDF_AnnualLeave_End] IS NULL and o.[UDF_AnnualLeave_End] IS NOT NULL or
n.[UDF_AnnualLeave_End] IS NOT NULL and o.[UDF_AnnualLeave_End] IS NULL
end
-- Field UDF_AnnualLeave_Start
if Update([UDF_AnnualLeave_Start])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'UDF_AnnualLeave_Start'),
'UDF_AnnualLeave_Start',
convert(nvarchar(255),n.[UDF_AnnualLeave_Start],120),
convert(nvarchar(255),o.[UDF_AnnualLeave_Start],120)
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='UDF_AnnualLeave_Start'
where n.[UDF_AnnualLeave_Start]<>o.[UDF_AnnualLeave_Start] or
n.[UDF_AnnualLeave_Start] IS NULL and o.[UDF_AnnualLeave_Start] IS NOT NULL or
n.[UDF_AnnualLeave_Start] IS NOT NULL and o.[UDF_AnnualLeave_Start] IS NULL
end
-- Field UDF_DateTimeLastAssigned
if Update([UDF_DateTimeLastAssigned])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'UDF_DateTimeLastAssigned'),
'UDF_DateTimeLastAssigned',
convert(nvarchar(255),n.[UDF_DateTimeLastAssigned],120),
convert(nvarchar(255),o.[UDF_DateTimeLastAssigned],120)
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='UDF_DateTimeLastAssigned'
where n.[UDF_DateTimeLastAssigned]<>o.[UDF_DateTimeLastAssigned] or
n.[UDF_DateTimeLastAssigned] IS NULL and o.[UDF_DateTimeLastAssigned] IS NOT NULL or
n.[UDF_DateTimeLastAssigned] IS NOT NULL and o.[UDF_DateTimeLastAssigned] IS NULL
end
-- Field UDF_LeaveDate
if Update([UDF_LeaveDate])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'UDF_LeaveDate'),
'UDF_LeaveDate',
convert(nvarchar(255),n.[UDF_LeaveDate],120),
convert(nvarchar(255),o.[UDF_LeaveDate],120)
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='UDF_LeaveDate'
where n.[UDF_LeaveDate]<>o.[UDF_LeaveDate] or
n.[UDF_LeaveDate] IS NULL and o.[UDF_LeaveDate] IS NOT NULL or
n.[UDF_LeaveDate] IS NOT NULL and o.[UDF_LeaveDate] IS NULL
end
-- Field UDF_StartDate
if Update([UDF_StartDate])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'UDF_StartDate'),
'UDF_StartDate',
convert(nvarchar(255),n.[UDF_StartDate],120),
convert(nvarchar(255),o.[UDF_StartDate],120)
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='UDF_StartDate'
where n.[UDF_StartDate]<>o.[UDF_StartDate] or
n.[UDF_StartDate] IS NULL and o.[UDF_StartDate] IS NOT NULL or
n.[UDF_StartDate] IS NOT NULL and o.[UDF_StartDate] IS NULL
end
-- Field UDF_AdditionalEquipmentAllocated
if Update([UDF_AdditionalEquipmentAllocated])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'UDF_AdditionalEquipmentAllocated'),
'UDF_AdditionalEquipmentAllocated',
n.[UDF_AdditionalEquipmentAllocated],
o.[UDF_AdditionalEquipmentAllocated]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='UDF_AdditionalEquipmentAllocated'
where n.[UDF_AdditionalEquipmentAllocated]<>o.[UDF_AdditionalEquipmentAllocated] or
n.[UDF_AdditionalEquipmentAllocated] IS NULL and o.[UDF_AdditionalEquipmentAllocated] IS NOT NULL or
n.[UDF_AdditionalEquipmentAllocated] IS NOT NULL and o.[UDF_AdditionalEquipmentAllocated] IS NULL
end
-- Field UDF_DownloadSpeed
if Update([UDF_DownloadSpeed])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'UDF_DownloadSpeed'),
'UDF_DownloadSpeed',
n.[UDF_DownloadSpeed],
o.[UDF_DownloadSpeed]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='UDF_DownloadSpeed'
where n.[UDF_DownloadSpeed]<>o.[UDF_DownloadSpeed] or
n.[UDF_DownloadSpeed] IS NULL and o.[UDF_DownloadSpeed] IS NOT NULL or
n.[UDF_DownloadSpeed] IS NOT NULL and o.[UDF_DownloadSpeed] IS NULL
end
-- Field UDF_LastSpeedTest
if Update([UDF_LastSpeedTest])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'UDF_LastSpeedTest'),
'UDF_LastSpeedTest',
convert(nvarchar(255),n.[UDF_LastSpeedTest],120),
convert(nvarchar(255),o.[UDF_LastSpeedTest],120)
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='UDF_LastSpeedTest'
where n.[UDF_LastSpeedTest]<>o.[UDF_LastSpeedTest] or
n.[UDF_LastSpeedTest] IS NULL and o.[UDF_LastSpeedTest] IS NOT NULL or
n.[UDF_LastSpeedTest] IS NOT NULL and o.[UDF_LastSpeedTest] IS NULL
end
-- Field UDF_Ping
if Update([UDF_Ping])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'UDF_Ping'),
'UDF_Ping',
n.[UDF_Ping],
o.[UDF_Ping]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='UDF_Ping'
where n.[UDF_Ping]<>o.[UDF_Ping] or
n.[UDF_Ping] IS NULL and o.[UDF_Ping] IS NOT NULL or
n.[UDF_Ping] IS NOT NULL and o.[UDF_Ping] IS NULL
end
-- Field UDF_UploadSpeed
if Update([UDF_UploadSpeed])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'UDF_UploadSpeed'),
'UDF_UploadSpeed',
n.[UDF_UploadSpeed],
o.[UDF_UploadSpeed]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='UDF_UploadSpeed'
where n.[UDF_UploadSpeed]<>o.[UDF_UploadSpeed] or
n.[UDF_UploadSpeed] IS NULL and o.[UDF_UploadSpeed] IS NOT NULL or
n.[UDF_UploadSpeed] IS NOT NULL and o.[UDF_UploadSpeed] IS NULL
end
-- Field ADImport_ID
if Update([ADImport_ID])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'ADImport_ID'),
'ADImport_ID',
n.[ADImport_ID],
o.[ADImport_ID]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='ADImport_ID'
where n.[ADImport_ID]<>o.[ADImport_ID] or
n.[ADImport_ID] IS NULL and o.[ADImport_ID] IS NOT NULL or
n.[ADImport_ID] IS NOT NULL and o.[ADImport_ID] IS NULL
end
-- Field UDF_Pager
if Update([UDF_Pager])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'UDF_Pager'),
'UDF_Pager',
n.[UDF_Pager],
o.[UDF_Pager]
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='UDF_Pager'
where n.[UDF_Pager]<>o.[UDF_Pager] or
n.[UDF_Pager] IS NULL and o.[UDF_Pager] IS NOT NULL or
n.[UDF_Pager] IS NOT NULL and o.[UDF_Pager] IS NULL
end
-- Field Data_Segment_ID
if Update([Data_Segment_ID])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'Data_Segment_ID'),
'Data_Segment_ID',
convert(nvarchar(255),n.[Data_Segment_ID]),
convert(nvarchar(255),o.[Data_Segment_ID])
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='Data_Segment_ID'
where n.[Data_Segment_ID]<>o.[Data_Segment_ID] or
n.[Data_Segment_ID] IS NULL and o.[Data_Segment_ID] IS NOT NULL or
n.[Data_Segment_ID] IS NOT NULL and o.[Data_Segment_ID] IS NULL
end
-- Field UDF_StopAutoAssignToSelf
if Update([UDF_StopAutoAssignToSelf])
begin
insert into History([Object_ID],[Changed_by_ID],[Action],[Attribute],[Field_Name],[New_Value],[Old_Value])
select
n.[ID],
oi.[Modified_by_ID],
'Changed',
isnull(cfv.[Field_Label],'UDF_StopAutoAssignToSelf'),
'UDF_StopAutoAssignToSelf',
convert(nvarchar(255),n.[UDF_StopAutoAssignToSelf]),
convert(nvarchar(255),o.[UDF_StopAutoAssignToSelf])
from inserted n
inner join deleted o on n.[ID]=o.[ID]
inner join Object_Index oi on n.[ID]=oi.[ID]
left outer join cfgCustFieldsLabels cfv on cfv.[Table_Name]='Persons' and cfv.[Field_Name]='UDF_StopAutoAssignToSelf'
where n.[UDF_StopAutoAssignToSelf]<>o.[UDF_StopAutoAssignToSelf] or
n.[UDF_StopAutoAssignToSelf] IS NULL and o.[UDF_StopAutoAssignToSelf] IS NOT NULL or
n.[UDF_StopAutoAssignToSelf] IS NOT NULL and o.[UDF_StopAutoAssignToSelf] IS NULL
end
update Persons set [Organization_ID]=n.[Organization_ID],
[Location_ID]=n.[Location_ID],
[Calendar_ID]=n.[Calendar_ID],
[Technician]=n.[Technician],
[Address]=n.[Address],
[IM_Address]=n.[IM_Address],
[First_Name]=n.[First_Name],
[Last_Name]=n.[Last_Name],
[Home_Phone]=n.[Home_Phone],
[Mobile_Phone]=n.[Mobile_Phone],
[Notes]=n.[Notes],
[Business_Phone]=n.[Business_Phone],
[Fax]=n.[Fax],
[Job_Title]=n.[Job_Title],
[Title]=n.[Title],
[Address_2]=n.[Address_2],
[Address_3]=n.[Address_3],
[Middle_Name]=n.[Middle_Name],
[Hourly_Rate]=n.[Hourly_Rate],
[Skill_Level]=n.[Skill_Level],
[SMS_Email]=n.[SMS_Email],
[Manager_ID]=n.[Manager_ID],
[UDF0001]=n.[UDF0001],
[UDF0003]=n.[UDF0003],
[Service]=n.[Service],
[UDF0004]=n.[UDF0004],
[UDF0005]=n.[UDF0005],
[Type_ID]=n.[Type_ID],
[Status_ID]=n.[Status_ID],
[Gender_ID]=n.[Gender_ID],
[Birthday]=n.[Birthday],
[Full_Name]=n.[Full_Name],
[OID]=n.[OID],
[Primary_Email]=n.[Primary_Email],
[Primary_Login]=n.[Primary_Login],
[Picture]=n.[Picture],
[UDF_Company]=n.[UDF_Company],
[UDF_PMS_Dev]=n.[UDF_PMS_Dev],
[UDF_AnnualLeave]=n.[UDF_AnnualLeave],
[UDF_AnnualLeave_End]=n.[UDF_AnnualLeave_End],
[UDF_AnnualLeave_Start]=n.[UDF_AnnualLeave_Start],
[UDF_DateTimeLastAssigned]=n.[UDF_DateTimeLastAssigned],
[UDF_LeaveDate]=n.[UDF_LeaveDate],
[UDF_StartDate]=n.[UDF_StartDate],
[UDF_AdditionalEquipmentAllocated]=n.[UDF_AdditionalEquipmentAllocated],
[UDF_DownloadSpeed]=n.[UDF_DownloadSpeed],
[UDF_LastSpeedTest]=n.[UDF_LastSpeedTest],
[UDF_Ping]=n.[UDF_Ping],
[UDF_UploadSpeed]=n.[UDF_UploadSpeed],
[ADImport_ID]=n.[ADImport_ID],
[UDF_Pager]=n.[UDF_Pager],
[Data_Segment_ID]=n.[Data_Segment_ID],
[UDF_StopAutoAssignToSelf]=n.[UDF_StopAutoAssignToSelf]
from Persons t,inserted n where t.[ID]=n.[ID]
set nocount off
endnext one:
/* Delete Persons */
Create trigger [dbo].[Trigger_Persons_Delete] on [dbo].[Persons]
instead of delete
as
BEGIN
set nocount on
update Persons set [Manager_ID]=null where [Manager_ID] in (select [ID] from deleted)
delete cfgSettings where [Person_ID] in (select [ID] from deleted)
delete cfgSystemLogNotifications where [Person_ID] in (select [ID] from deleted)
delete cfgViews where [Person_ID] in (select [ID] from deleted)
delete cfgDisabledViews where [Person_ID] in (select [ID] from deleted)
delete cfgCalendarObjects where [Person_ID] in (select [ID] from deleted)
delete Person_Logins where [Person_ID] in (select [ID] from deleted)
delete Person_Emails where [Person_ID] in (select [ID] from deleted)
delete Group_Members where [Person_ID] in (select [ID] from deleted)
delete Person_Devices where [Person_ID] in (select [ID] from deleted)
delete Change_Request_Approvals where [Approver_ID] in (select [ID] from deleted)
delete Solution_Ratings where [Person_ID] in (select [ID] from deleted)
delete Work_Calendars where [Person_ID] in (select [ID] from deleted)
delete cfgSnippets where [Person_ID] in (select [ID] from deleted)
delete cfgSnippetCategory where [Person_ID] in (select [ID] from deleted)
delete License_Allocations where [Object_ID] in (select [ID] from deleted)
delete Software_License_Persons where [Person_ID] in (select [ID] from deleted)
delete cfgDashboards where [Person_ID] in (select [ID] from deleted)
delete Object_Flags where [Person_ID] in (select [ID] from deleted)
delete Activity where [Object_ID] in (select [ID] from deleted)
delete Object_Index where [ID] in (select [ID] from deleted)
update Stock_Movements set [Stock_Manager_OID]=d.[OID], [Stock_Manager_Name]=d.[Full_Name] from deleted d where [Stock_Manager_ID]=d.[ID]
update Stock_Movements set [Source_Person_OID]=d.[OID], [Source_Person_Name]=d.[Full_Name] from deleted d where [Source_Person_ID]=d.[ID]
update Stock_Movements set [Target_Person_OID]=d.[OID], [Target_Person_Name]=d.[Full_Name] from deleted d where [Target_Person_ID]=d.[ID]
update Attachments set [Created_by_ID] = null where [Created_by_ID] in (select [ID] from deleted)
update Attachments set [Modified_by_ID] = null where [Modified_by_ID] in (select [ID] from deleted)
update Library_History set [User_ID] = null where [User_ID] in (select [ID] from deleted)
update cfgWFLogs set [User_ID] = null where [User_ID] in (select [ID] from deleted)
if dbo.fnIsExpress() = 1
update Assets set [Owner_ID] = null where [Owner_ID] in (select [ID] from deleted)
delete Persons where [ID] in (select [ID] from deleted)
if exists(select * from cfgInfo where [Name] = 'Lookup_Tables_Modification_Time')
update cfgInfo set [Value] = convert(nvarchar, GETDATE(), 120) where [Name] = 'Lookup_Tables_Modification_Time'
else
insert cfgInfo ([Name], [Value]) values ('Lookup_Tables_Modification_Time', convert(nvarchar, GETDATE(), 120))
set nocount off
ENDNext one:
CREATE TRIGGER [dbo].[Trigger_Persons_DeleteTemplateDefinition] ON [dbo].[Persons] FOR DELETE AS BEGIN
SET NOCOUNT ON
DELETE cfgLCFormDefinition WHERE UPPER(CAST([Field_Value] AS NVARCHAR(38))) IN (SELECT UPPER('{' + CAST([ID] AS NVARCHAR(36)) + '}') FROM deleted)
DELETE cfgLCTemplateDefinition WHERE UPPER(CAST([Field_Value] AS NVARCHAR(38))) IN (SELECT UPPER('{' + CAST([ID] AS NVARCHAR(36)) + '}') FROM deleted)
DELETE cfgLCParamsMap WHERE UPPER(CAST([Value] AS NVARCHAR(38))) IN (SELECT UPPER('{' + CAST([ID] AS NVARCHAR(36)) + '}') FROM deleted)
DELETE cfgLCEmailParamsMap WHERE UPPER(CAST([Value] AS NVARCHAR(38))) IN (SELECT UPPER('{' + CAST([ID] AS NVARCHAR(36)) + '}') FROM deleted)
SET NOCOUNT OFF
END
GONext one:
/* Create table level triggers for table Persons. */
CREATE TRIGGER [dbo].[Trigger_Persons_Insert] ON [dbo].[Persons]
FOR INSERT
AS
BEGIN
SET NOCOUNT ON
DECLARE @u_id UNIQUEIDENTIFIER
SELECT @u_id=[ID] FROM Object_Class WHERE [Class_Index]=12
INSERT INTO Object_Index([ID],[Class_ID],[Object_Name],[OID],[Status_ID],[Type_ID],[Data_Segment_ID])
SELECT h.[ID],@u_id,h.[Full_Name],h.[OID], h.[Status_ID], h.[Type_ID], h.[Data_Segment_ID] FROM inserted h
IF EXISTS(SELECT 1 FROM inserted WHERE ISNULL([Primary_Email], '') <> '')
INSERT INTO Person_Emails([Person_ID], [Email], [Type_ID], [Primary])
SELECT [ID], [Primary_Email], '{719BEF62-C1BF-454B-853B-BD82CF0057B5}', 1
FROM inserted WHERE NOT ([Primary_Email] IS NULL)
IF EXISTS(SELECT 1 FROM inserted WHERE ISNULL([Primary_Login], '') <> '')
INSERT INTO Person_Logins([Person_ID], [Domain], [Login], [Primary])
SELECT [ID], dbo.fnGetLoginPart([Primary_Login], 'D'), dbo.fnGetLoginPart([Primary_Login], 'L'), 1
FROM inserted WHERE NOT ([Primary_Login] IS NULL)
IF dbo.fnIsExpress() = 1 AND EXISTS (
SELECT * FROM inserted i, Persons p
WHERE p.[ID] = i.[ID] AND (
p.[Technician] = 1 AND ISNULL(p.[Type_ID], 0x0) <> '{A8790D51-21EE-41D4-AC1F-704A339271AD}' OR
p.[Technician] = 0 AND ISNULL(p.[Type_ID], 0x0) = '{A8790D51-21EE-41D4-AC1F-704A339271AD}'))
UPDATE p
SET p.[Technician] = CASE WHEN p.[Type_ID] = '{A8790D51-21EE-41D4-AC1F-704A339271AD}' THEN 1 ELSE 0 END
FROM Persons p, inserted i
WHERE p.[ID] = i.[ID] AND (
p.[Technician] = 1 AND ISNULL(p.[Type_ID], 0x0) <> '{A8790D51-21EE-41D4-AC1F-704A339271AD}' OR
p.[Technician] = 0 AND ISNULL(p.[Type_ID], 0x0) = '{A8790D51-21EE-41D4-AC1F-704A339271AD}')
IF EXISTS(SELECT * FROM cfgInfo WHERE [Name] = 'Lookup_Tables_Modification_Time')
UPDATE cfgInfo SET [Value] = CONVERT(NVARCHAR, GETDATE(), 120) WHERE [Name] = 'Lookup_Tables_Modification_Time'
ELSE
INSERT cfgInfo ([Name], [Value]) VALUES ('Lookup_Tables_Modification_Time', CONVERT(NVARCHAR, GETDATE(), 120))
SET NOCOUNT OFF
ENDNext one:
CREATE TRIGGER [dbo].[Trigger_Persons_Update] ON [dbo].[Persons]
FOR UPDATE
AS
BEGIN
set nocount on
if Update([Full_Name])
begin
update Object_Index set [Object_Name]=h.[Full_Name]
from inserted h,Object_Index oi where oi.[ID]=h.[ID]
IF (SELECT COUNT(*) FROM inserted i, deleted d
WHERE i.[ID] = d.[ID] AND (ISNULL(i.[Full_Name], '') <> ISNULL(d.[Full_Name], ''))) > 0
IF EXISTS(SELECT * FROM cfgInfo WHERE [Name] = 'Lookup_Tables_Modification_Time')
update cfgInfo set [Value] = convert(nvarchar, GETDATE(), 120) where [Name] = 'Lookup_Tables_Modification_Time'
ELSE
INSERT cfgInfo ([Name], [Value]) VALUES ('Lookup_Tables_Modification_Time', CONVERT(NVARCHAR, GETDATE(), 120))
END
if Update([OID])
begin
update Object_Index
set [OID]=h.[OID]
from inserted h,Object_Index oi where oi.[ID]=h.[ID]
end
if Update([Primary_Email])
begin
if (select count(*) from inserted i, deleted d
where i.[ID] = d.[ID] and (UPPER(ISNULL(i.[Primary_Email], '')) + 'x') <> (UPPER(ISNULL(d.[Primary_Email], ''))) + 'x') > 0
begin
update Person_Emails
set [Primary] = 0
from Person_Emails e, inserted i
where e.[Person_ID] = i.[ID] and (UPPER(e.[Email]) + 'x') <> (UPPER(ISNULL(i.[Primary_Email], '')) + 'x') and
e.[Primary] = 1
update Person_Emails
set [Primary] = 1
from Person_Emails e, inserted i
where e.[Person_ID] = i.[ID] and (UPPER(e.[Email]) + 'x') = (UPPER(i.[Primary_Email]) + 'x') and
e.[Primary] = 0
INSERT INTO Person_Emails
([Person_ID], [Email], [Primary], [Type_ID])
SELECT i.[ID], i.[Primary_Email], 1, '{719BEF62-C1BF-454B-853B-BD82CF0057B5}'
FROM inserted i
WHERE (ISNULL(i.[Primary_Email], '') + 'x') <> 'x' AND NOT EXISTS(
SELECT * FROM Person_Emails e
WHERE e.[Person_ID] = i.[ID] AND (UPPER(e.[Email]) + 'x') = (UPPER(i.[Primary_Email])) + 'x')
END
END
if Update([Primary_Login])
begin
if (select count(*) from inserted i, deleted d
where i.[ID] = d.[ID] and UPPER(ISNULL(i.[Primary_Login], '')) <> UPPER(ISNULL(d.[Primary_Login], ''))) > 0
begin
update Person_Logins
set [Primary] = 0
from Person_Logins l, inserted i
where l.[Person_ID] = i.[ID] and UPPER(dbo.fnGetFullLogin(l.[Domain], l.[Login])) <> UPPER(ISNULL(i.[Primary_Login], '')) and
l.[Primary] = 1
update Person_Logins
set [Primary] = 1
from Person_Logins l, inserted i
where l.[Person_ID] = i.[ID] and UPPER(dbo.fnGetFullLogin(l.[Domain], l.[Login])) = UPPER(i.[Primary_Login]) and
l.[Primary] = 0
INSERT INTO Person_Logins
([Person_ID], [Domain], [Login], [Primary])
SELECT i.[ID], dbo.fnGetLoginPart(i.[Primary_Login], 'D'), dbo.fnGetLoginPart(i.[Primary_Login], 'L'), 1
FROM inserted i
WHERE ISNULL(i.[Primary_Login], '') <> '' AND NOT EXISTS(
SELECT * FROM Person_Logins l
WHERE l.[Person_ID] = i.[ID] AND UPPER(dbo.fnGetFullLogin(l.[Domain], l.[Login])) = UPPER(i.[Primary_Login]))
END
END
if Update([Status_ID]) and
(select count(*) from inserted i, deleted d
where i.[ID] = d.[ID] and ISNULL(i.[Status_ID], 0x0) <> ISNULL(d.[Status_ID], 0x0)) > 0
begin
if not exists (select 1 from inserted i, [Status] s
where i.[Status_ID] = s.[ID] and s.[Class_ID] = '{88CFCCC2-2235-4AA3-9BBA-FE5DAEED25FE}' or i.[Status_ID] is null)
begin
raiserror('Unable to assign this Status value because it belongs to a different object class.',15,1)
ROLLBACK TRAN
END
UPDATE Object_Index SET [Status_ID] = h.[Status_ID]
FROM inserted h,Object_Index oi WHERE oi.[ID] = h.[ID]
END
if Update([Data_Segment_ID]) and
(select count(*) from inserted i, deleted d
where i.[ID] = d.[ID] and ISNULL(i.[Data_Segment_ID], 0x0) <> ISNULL(d.[Data_Segment_ID], 0x0)) > 0
begin
update Object_Index set [Data_Segment_ID] = h.[Data_Segment_ID]
from inserted h,Object_Index oi where oi.[ID] = h.[ID]
end
IF UPDATE([Type_ID]) AND
(SELECT COUNT(*) FROM inserted i, deleted d
WHERE i.[ID] = d.[ID] AND ISNULL(i.[Type_ID], 0x0) <> ISNULL(d.[Type_ID], 0x0)) > 0
BEGIN
if not exists (select 1 from inserted i, [Object_Type] t
where i.[Type_ID] = t.[ID] and t.[Class_ID] = '{88CFCCC2-2235-4AA3-9BBA-FE5DAEED25FE}' or i.[Type_ID] is null)
begin
raiserror('Unable to assign this Type value because it belongs to a different object class.',15,1)
ROLLBACK TRAN
END
update Object_Index set [Type_ID] = h.[Type_ID]
from inserted h,Object_Index oi where oi.[ID] = h.[ID]
END
IF UPDATE([Technician]) AND
(SELECT COUNT(*) FROM inserted i, deleted d
WHERE i.[ID] = d.[ID] AND i.[Technician] <> d.[Technician]) > 0
BEGIN
DECLARE @Err NVARCHAR(MAX), @PersName NVARCHAR(276), @GroupName NVARCHAR(50)
SELECT TOP 1 @PersName = i.[Full_Name], @GroupName = g.[Name]
FROM inserted i
LEFT JOIN Group_Members m ON m.[Person_ID] = i.[ID]
LEFT JOIN User_Groups g ON g.[ID] = m.[Group_ID] AND g.[Technicians_Only] = 1
WHERE i.[Technician] = 0 AND g.[ID] IS NOT NULL
IF @PersName IS NOT NULL
BEGIN
SET @Err = 'Technician groups can contain only technicians. Person "' + @PersName + '" is not a technician and cannot be a member of a technician group "'+ISNULL(@GroupName,'')+'".'
RAISERROR(@Err,15,1)
ROLLBACK TRAN
END
END
IF (SELECT COUNT(*) FROM inserted i, deleted d
WHERE i.[ID] = d.[ID] AND (ISNULL(i.[Status_ID], 0x0) <> ISNULL(d.[Status_ID], 0x0))
) > 0
BEGIN
DECLARE @id UNIQUEIDENTIFIER
DECLARE sl_cursor CURSOR LOCAL FOR
SELECT [Software_License_ID] FROM License_Allocations la, inserted i
WHERE la.[Object_ID] = i.[ID]
OPEN sl_cursor
FETCH NEXT FROM sl_cursor INTO @id
WHILE @@FETCH_STATUS = 0
BEGIN
EXEC spUpdateLicenseStaticCompliance @id
FETCH NEXT FROM sl_cursor INTO @id
END
CLOSE sl_cursor
DEALLOCATE sl_cursor
END
SET NOCOUNT OFF
ENDLast one:
CREATE TRIGGER [dbo].[Trigger_Persons_UpdateUDFLookupValue] ON [dbo].[Persons]
FOR UPDATE
AS
BEGIN
IF UPDATE([Full_Name])
UPDATE [KB_Articles]
SET [UDF_Approved_by] = (
SELECT [Full_Name] FROM [Persons] ref WHERE ref.[ID] = tbl.[UDF_Approved_by_ID])
FROM [KB_Articles] tbl WHERE [UDF_Approved_by_ID] IN (SELECT [ID] FROM inserted)
IF UPDATE([Full_Name])
UPDATE [Incidents]
SET [UDF_InternallyTransferred] = (
SELECT [Full_Name] FROM [Persons] ref WHERE ref.[ID] = tbl.[UDF_InternallyTransferred_ID])
FROM [Incidents] tbl WHERE [UDF_InternallyTransferred_ID] IN (SELECT [ID] FROM inserted)
IF UPDATE([Full_Name])
UPDATE [Incidents]
SET [UDF_MattersphereDevAssigned] = (
SELECT [Full_Name] FROM [Persons] ref WHERE ref.[ID] = tbl.[UDF_MattersphereDevAssigned_ID])
FROM [Incidents] tbl WHERE [UDF_MattersphereDevAssigned_ID] IN (SELECT [ID] FROM inserted)
ENDFinally, DDL for the "History" heap:
CREATE TABLE [dbo].[History](
[ID] [UNIQUEIDENTIFIER] NOT NULL,
[Object_ID] [UNIQUEIDENTIFIER] NOT NULL,
[Ref_Object_ID] [UNIQUEIDENTIFIER] NULL,
[Changed_by] [NVARCHAR](276) NULL,
[Changed_by_ID] [UNIQUEIDENTIFIER] NULL,
[Change_Date] [DATETIME] NULL,
[Action] [NVARCHAR](50) NOT NULL,
[Attribute] [NVARCHAR](100) NOT NULL,
[New_Value] [NVARCHAR](MAX) NULL,
[Old_Value] [NVARCHAR](MAX) NULL,
[WF_Item_Num] [NVARCHAR](30) NULL,
[WF_Action_Num] [NVARCHAR](30) NULL,
[Field_Name] [NVARCHAR](100) NULL,
[Is_HTML_Field] [BIT] NULL,
CONSTRAINT [History_PK] PRIMARY KEY NONCLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
ALTER TABLE [dbo].[History] ADD DEFAULT (NEWID()) FOR [ID]
GO
ALTER TABLE [dbo].[History] ADD DEFAULT (GETDATE()) FOR [Change_Date]
GO
ALTER TABLE [dbo].[History] WITH CHECK ADD CONSTRAINT [Object_Index_History_FK1] FOREIGN KEY([Object_ID])
REFERENCES [dbo].[Object_Index] ([ID])
GO
ALTER TABLE [dbo].[History] CHECK CONSTRAINT [Object_Index_History_FK1]
GOAnd the trigger on History:
CREATE TRIGGER [dbo].[Trigger_History_Insert] ON [dbo].[History]
INSTEAD OF INSERT
AS
BEGIN
set nocount on
if IsNull((select [Value] from dbo.cfgSettings where [Name] = 'HistoryEnabled' and [Group_Name] = 'System'), 'True') = 'False'
return
if dbo.fnIsExpress() = 1 and not exists (
select * from Object_Index oi, inserted n
where oi.[ID] = n.[Object_ID] and oi.[Class_ID] IN (
'{64308C82-A2AB-4FA2-BCB1-AC9C6B7C72EC}', -- Work Orders
'{68F5801B-8B74-4148-9DB4-82F256CAFD30}', -- Change Request
'{C73482C8-A913-48BF-9898-88AE449C9F19}', -- Computers
'{18076F4A-4224-4EB1-A6ED-5C4F4E506505}')) -- Hardware
return
declare @Prs_ID uniqueidentifier -- Person ID
declare @Prs nvarchar(276) -- Person
declare @Op_Date datetime
declare @LC_Action nvarchar(30)
DECLARE @LC_Item NVARCHAR(30)
DECLARE @Fields NVARCHAR(1024)
IF EXISTS(SELECT 1 FROM cfgSPID WHERE [SPID]=@@spid)
BEGIN
SELECT @Prs_ID=[Author_ID], @Prs=[Author], @Op_Date=[Operation_Date],
@LC_Action = [Action], @LC_Item = [WF_Item], @Fields = [Fields]
FROM cfgSPID WHERE [SPID] = @@spid
END
ELSE
BEGIN
SET @Op_Date=GETDATE()
SET @LC_Action=NULL
SELECT @Prs_ID=p.[ID], @Prs=p.[Full_Name]
FROM User_Accounts cua
INNER JOIN Persons p ON p.[ID]=cua.[Person_ID]
WHERE cua.[Login]=dbo.fnSessionLogin()
END
INSERT INTO History([ID],[Object_ID],[Ref_Object_ID],[Changed_by],[Changed_by_ID],[Change_Date],[Action],
[Attribute],[Field_Name],[New_Value],[Old_Value],[Is_HTML_Field],[WF_Item_Num],[WF_Action_Num])
SELECT
n.[ID],
n.[Object_ID],
n.[Ref_Object_ID],
@Prs,
@Prs_ID,
@Op_Date,
n.[Action],
n.[Attribute],
n.[Field_Name],
n.[New_Value],
n.[Old_Value],
n.[Is_HTML_Field],
CASE
WHEN CHARINDEX('#' + n.[Field_Name], @Fields) > 0 THEN
CAST(SUBSTRING(@Fields, CHARINDEX('#' + n.[Field_Name], @Fields) - 10, 10) AS INT)
ELSE ISNULL(n.[WF_Item_Num], @LC_Item)
END,
ISNULL(n.[WF_Action_Num], @LC_Action)
FROM inserted n
SET NOCOUNT OFF
END"Knowledge is of two kinds. We know a subject ourselves, or we know where we can find information upon it. When we enquire into any subject, the first thing we have to do is to know what books have treated of it. This leads us to look at catalogues, and at the backs of books in libraries."
— Samuel Johnson
I wonder, would the great Samuel Johnson have replaced that with "GIYF" now? -
Just went through all that code and lordy.
First, they're using a MAX datatype on address columns. I guess they never want to do lookups on those columns. 😀 Either that or someone realized that the NOTES column should be defaulted to blank and forced our of row to prevent "ExpAnsive" updates on the CI and thought it would be a good idea to send the address columns along with that (it could be but they're rarely going to be updated so I doubt such knowledge of out-of-row data was the intent).
Of course, you're already aware that it's a denormalized bit of train-wreck for things like telephone numbers and "leave".
Because of the width of the table , some one did understand that it's probably better to do column auditing instead of row auditing to make updates take a fair bit less space in the audit table. Oddly enough, the main trigger on the table is written almost correctly. The IF UPDATE() stuff is right and it's right to be hardcoded instead of trying to go dynamic, which would cause full material materialization of an otherwise logical pair of tables (INSERTED/DELETED and I've got personal experience of how slow that will make things and, no, it wasn't me that made that type of mistake... I'm the one that fixed it). The end of each IF UPDATE is appropriate to prevent logging stuff that hasn't actually changed (IF UPDATE() doesn't check for that).
However, in my quick read of the code, I have no idea why they decided to make it an INSTEAD OF TRIGGER. It's just not necessary and could cause some issues with cascading triggers if they allow such a thing and aren't aware of what the trigger has done.
I'll also say that putting a trigger on an audit table should be against the law. Then to have a scalar or multistatement Table Valued Function in it? Not good. It's also an INSTEAD OF trigger... I can maybe see that to cut down on the number of rows audited like it's designed but, lordy.
I guess I don't understand why they encapsulated the GUID literals in braces. While that still works, the braces aren't necessary. It's just more clock cycles for the system to do.
Then there's the issue of the audit table (history) design. Although it's a pretty standard design, the standard design has a couple of unhealthy flaws in it. First, there's the unnecessary duplication of data between the old and new values. For some reason, people think that's going to make reading the audit table easier than simply finding the previous row for similar entries. If you're only going to look at one row at a time, that's fine but they almost always want to reconstruct "records" for a given point in time, as well. With all the time they spent in the triggers, it would be good if they worked it like temporal tables work with a start and end date for when the row was actually active (Type 6 SCD, which is a combination of Type 2 and Type 4).
To make a much longer story shorter, someone spent a whole lot of time doing things they needed to do. They also made it quite complex for what it does. There are some things that can be done to increase the performance but I don't believe that performance is going to get worse with scale for this (famous last words, I know). It would also take a whole lot of regression testing for any fixes you make.
With that being said (and I hate to say the following because I'm a bit of a freak for performance), what would be the ROI of just fixing parts of this and what would be the ROI of rewriting the whole system of things that supports this audit table or a rewrite and migration of the data to a new audit table? As much as I hate to admit it, probably not enough to justify the expense in the people power to make it happen (although I don't know that for this particular case... you folks would need to decide).
Some will suggest that changing the ID in the audit (history) table to a BIGINT would be worthwhile. It could be but it might actually make things worse because a BIGINT would make a hotspot at the end of the table instead of it distributing new rows across the breadth of the table.
My best suggestion would be to partition the audit table temporally (I prefer Partitioned Views over Partitioned Tables every day and can explain that on another thread) so that you can maybe do compression (which would also provide a final defrag) on the table, set it to Read_Only (if each month or year is in a separate file group), do one final backup on each older Read_Only file group, and NEVER have to do another backup on the old data that will never change again nor have to maintain indexes, probably not even on the current month (it probably won't fragment enough to warrant defragmentation if you do like I talked about on other threads with Fill Factor and NOT using REORGANIZE on that month).
That's about it. If there's not significant enough problems with the current performance to justify a good ROI, leave the code alone because I don't believe scalability is going to hurt this code any more than it has, consider temporally partitioning the table to be able to make the older partitions READ_ONLY to reduce backup times (and allow for Piece-Meal restores... whole 'nuther subject there), and use the Fill Factor trick with REBUILD-only (no REORGANIZE for this one) to prevent as much fragmentation for the writable partitions so you don't have to defrag those until you want to make the underlying File Group Read_Only.
And no... if you plan it out right, a super low FILL Factor of 61 or 51 on the current writable partition (if you partition) isn't going to waste space or kill performance on this because it's a growing audit table and you can just think of it as preallocating space that will be filled that month.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
OK, if you set the fillfactor to 51 and rebuild you will have far fewer splits, perhaps none, because you've already at least doubled the size of the table. Any scan of the table must now read twice as many pages. This is a case where the "cure" is probably worse than the disease. Why not just use a more useful clustering?
Also, there's no way to know for sure how evenly distributed future inserts will be, and thus no way to know what % of the half(or more)-empty pages will eventually be filled in.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
It's an audit table, Scott. Most people are going to be doing a lot of reads from it. You're talking about doubling the size but a lot of people also preallocate MDF and LDF files to prevent growth spurts. There's no difference between that and an audit table that you know is going to continue to grow.
If you're using Random GUIDs, I can assure you (and prove if you need me to) that the distribution will be incredibly even. That's also why you can go for months with no page splits and still have the performance advantage of no "hot spot" at the end of the table if you use a more traditional CI Key.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
Just went through all that code and lordy.
8<
Many thanks for taking the time to wade through that lot Jeff, and I hope your blood pressure didn't rise too much in the process.
I will investigate partitioning, thanks. It's not something I've had the need/opportunity to play with. We only use Std edition and have only just gone to 2016, so not been in the arsenal until recently.
You are quite right, the ROI of anything more than a few hours would just not be worth it on this system. As a product to use, it is actually a very good CMDB, mostly very well thought out and not (yet) forcing users down a Web UI only - although I have a nasty feeling that is coming soon. Another of my pet hates, the advantage of cross-platform compatibility and no installation never seems to make up for the loss in functionality, reliability and performance. (Vsphere - I'm looking at you!)
"Knowledge is of two kinds. We know a subject ourselves, or we know where we can find information upon it. When we enquire into any subject, the first thing we have to do is to know what books have treated of it. This leads us to look at catalogues, and at the backs of books in libraries."
— Samuel Johnson
I wonder, would the great Samuel Johnson have replaced that with "GIYF" now? - david.edwards 76768 wrote:Jeff Moden wrote:
Just went through all that code and lordy.
8<
Many thanks for taking the time to wade through that lot Jeff, and I hope your blood pressure didn't rise too much in the process.
I will investigate partitioning, thanks. It's not something I've had the need/opportunity to play with. We only use Std edition and have only just gone to 2016, so not been in the arsenal until recently.
You are quite right, the ROI of anything more than a few hours would just not be worth it on this system. As a product to use, it is actually a very good CMDB, mostly very well thought out and not (yet) forcing users down a Web UI only - although I have a nasty feeling that is coming soon. Another of my pet hates, the advantage of cross-platform compatibility and no installation never seems to make up for the loss in functionality, reliability and performance. (Vsphere - I'm looking at you!)
On the partitioning thing... Partitioned Views work in all versions and all editions. It used to be that you needed the Enterprise Edition to do Partitioned Tables but that hasn't been true since 2016 SP1 where it's now a feature of (at least) the Standard Edition (haven't use Express in nearly two decades so don't have that tidbit memorized).
Although a lot of people (including the people that wrote the MS documentation on the subject) strongly recommend the use of Partitioned Tables over the much older technology of Partitioned Views and with the understanding that I've used both, I find Partitioned Views to be far superior to Partitioned Tables for the things I want and need to do, which I don't believe are all that different from what the general population wants and needs to do.
And, no... no blood pressure rises on seeing the code. Someone was definitely on a mission when they wrote that code and seeing things like the denormalization of the base table doesn't even cause the vein in my forehead to throb anymore because it's not my code, wasn't written by anyone I know, and there's little I can do about it except to provide some opinions and, sometimes, recommendations.
If that code were on a box I owned, I'd have done a litany of documented performance tests, done the ROI eval, and (probably) would have already sent a "please fix this in your code with the following code" request accompanied by all that documentation, free of charge. I'd also have started research on a replacement product if they blew me off as well as purchasing a large amount of frozen pork chops for the upcoming lesson they were due. 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
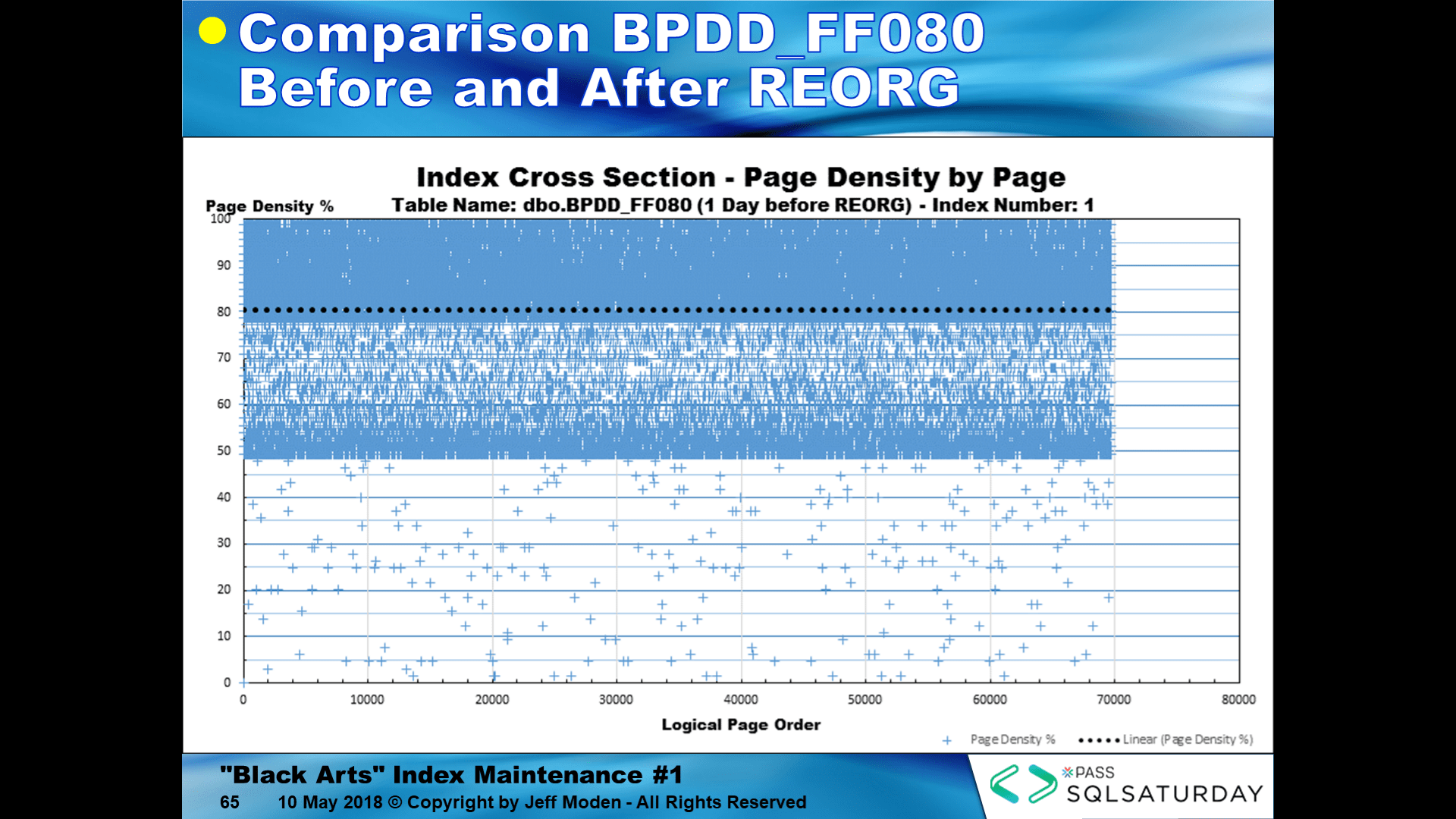
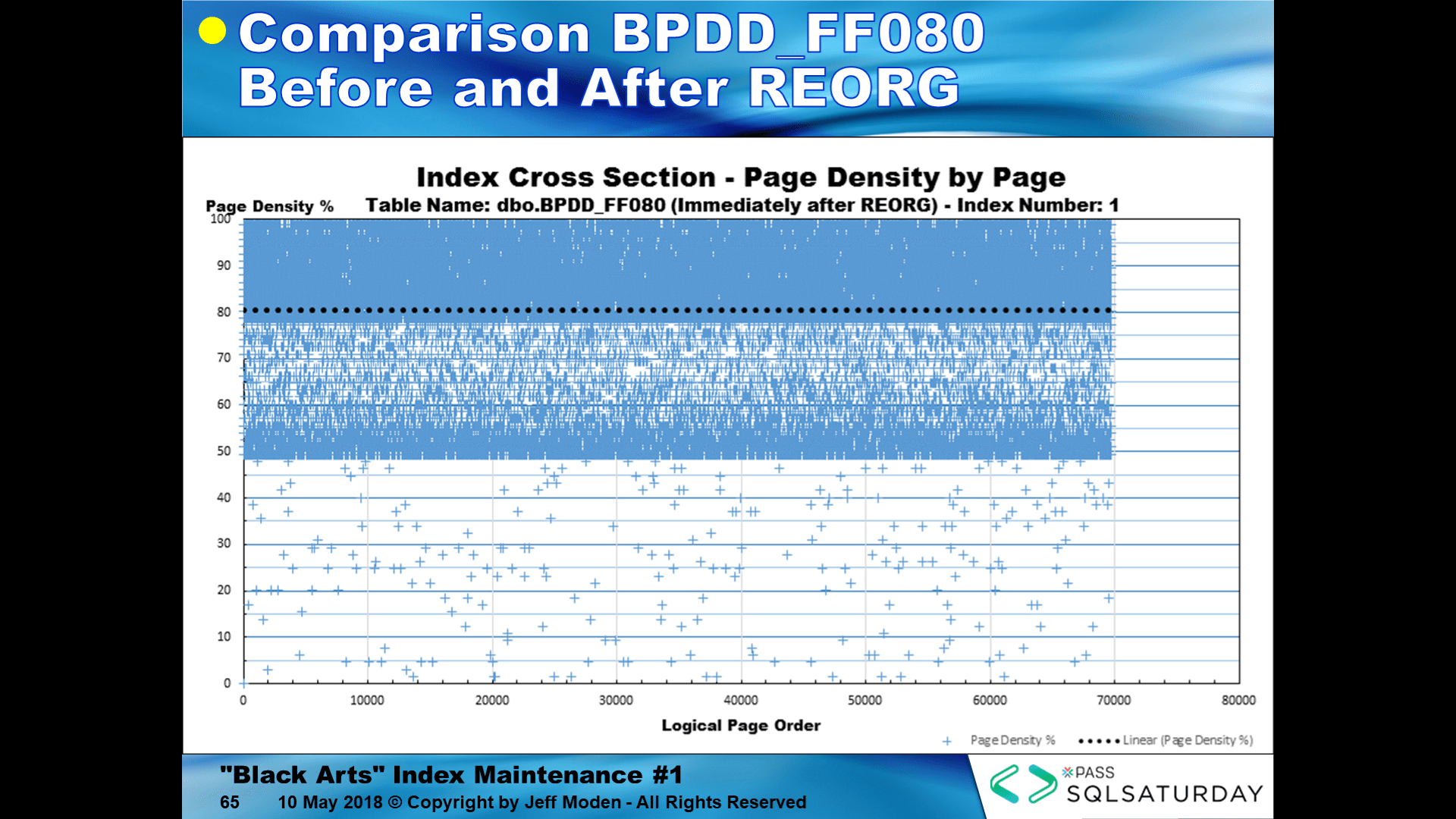
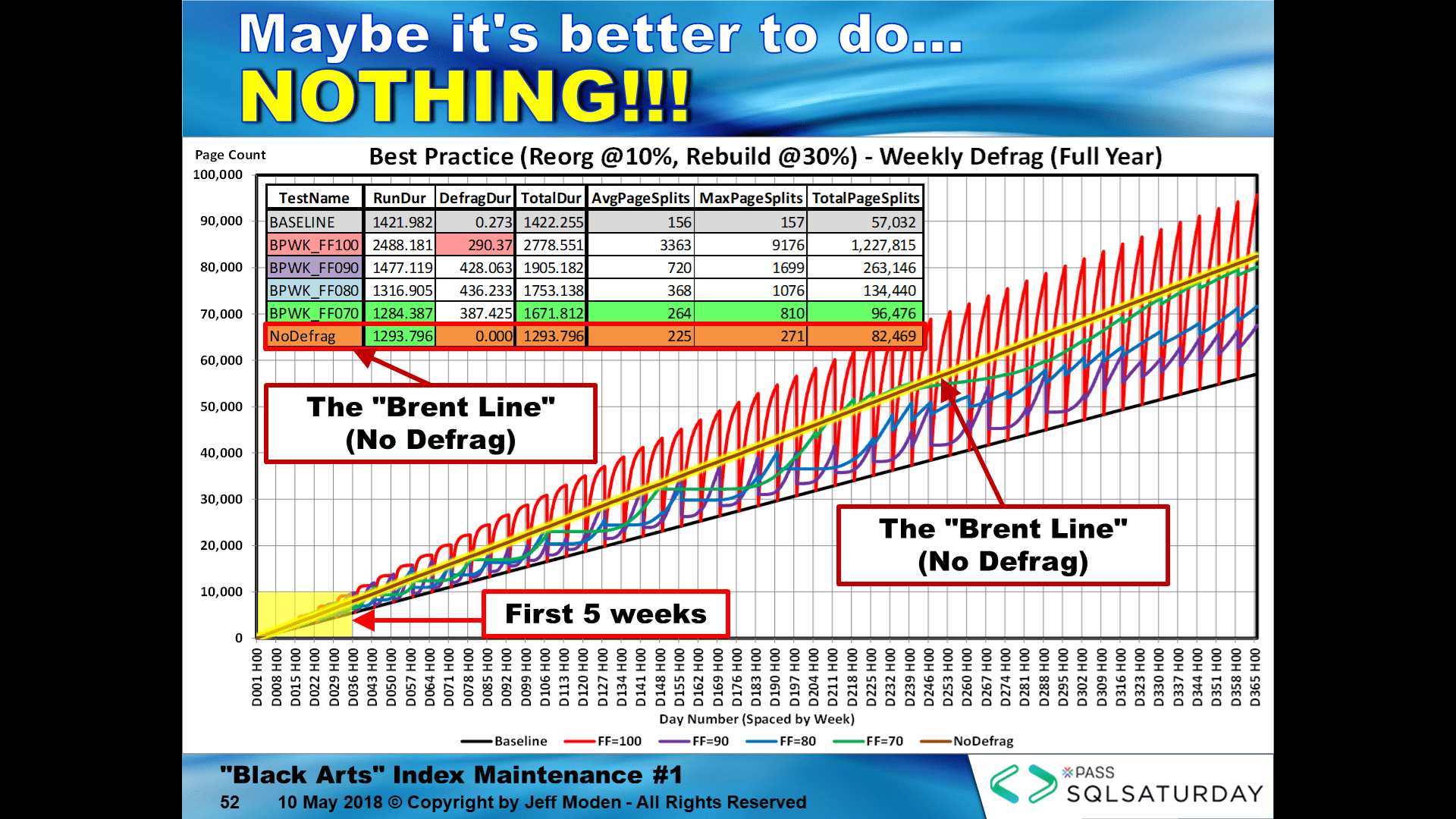
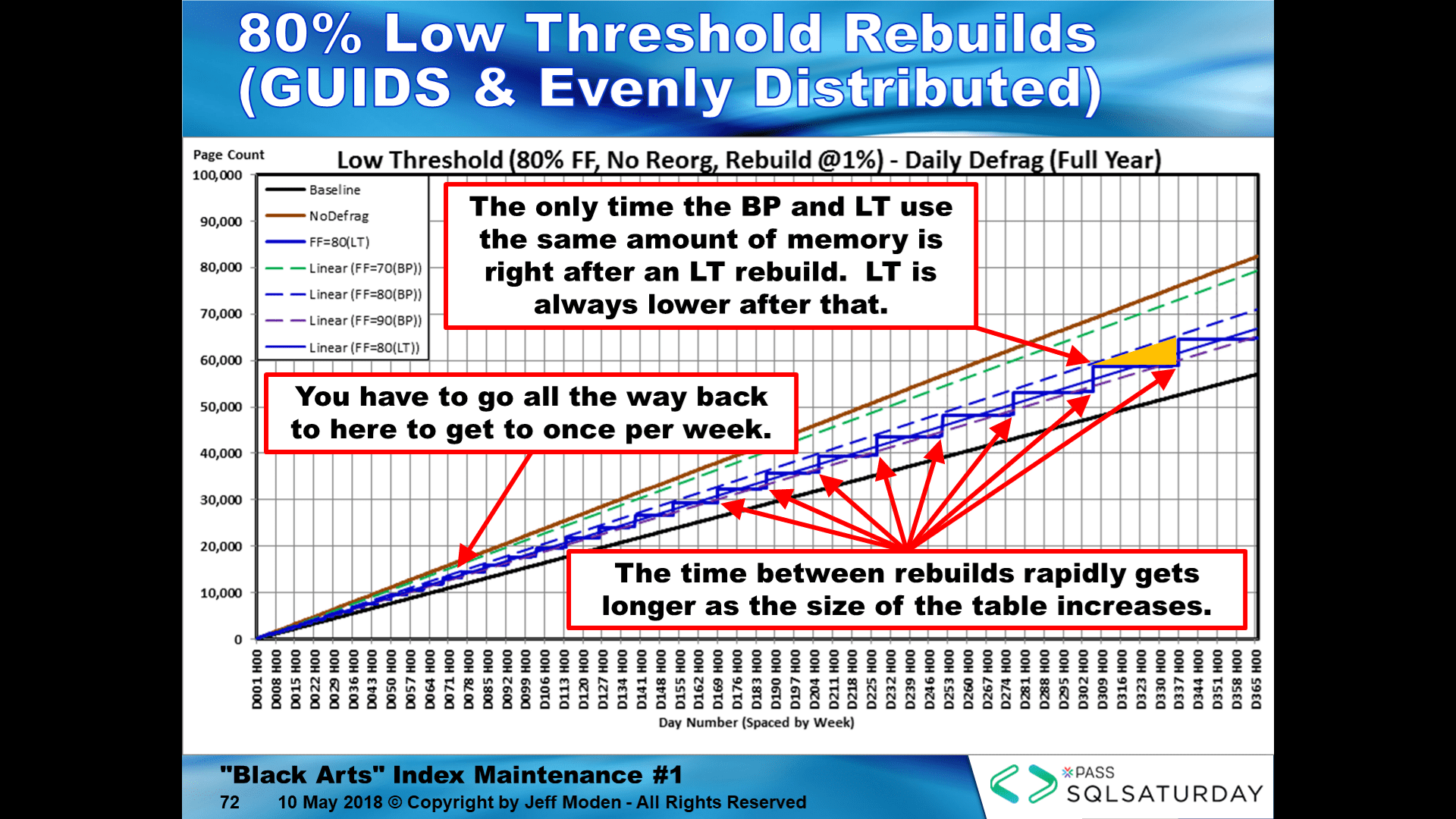
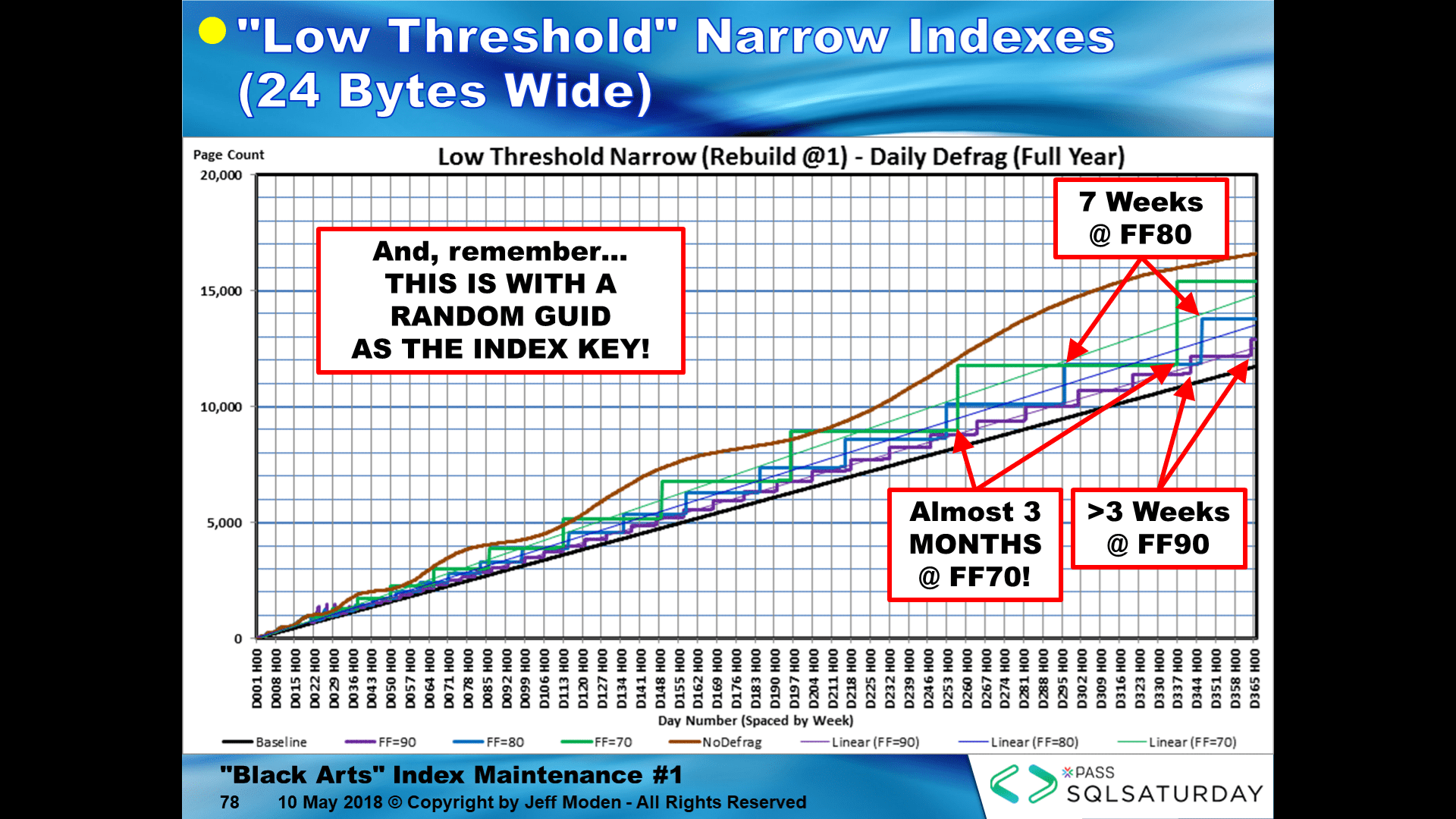
Viewing 14 posts - 1 through 14 (of 14 total)
You must be logged in to reply to this topic. Login to reply