

In any study of Data Types in SQL Server you are going to have to look at the various string data types. One important component is the difference between nChar vs Char and nVarChar vs VarChar. Most people reading this are probably thinking “Well that’s ridiculously easy.” If you are one of them then I want you to read these two facts about these data types.
| Char and VarChar | nChar and nVarChar | |
|---|---|---|
| Stores | ASCII | UNICODE |
| Size | Always one byte per character. | Always two bytes per character. |
One of these is incorrect. Do you know which one?
Believe it or not the number of bytes taken up per character is not a set amount. It’s actually a minimum. Characters in a Char/VarChar column can take up more than one byte and nChar/nVarChar can take up more than two. I knew this to a certain extent from one of the comments in my Collation: Definition post. As of 2012 there is a collation option called UTF-16 Supplementary Characters (SC) that supports UTF16 characters that require more than 2 bytes. I hadn’t really thought about it though until I was reading an interesting answer to a post on StackOverflow. Basically, it said that certain code pages contain characters that go beyond the available 256 characters available to the single byte varchar/char and so those characters take up two bytes.
So all of that is interesting but let’s see the demo! Note: I’m borrowing some code from the answer I mentioned 🙂
But wait! First let me point out a few important functions so everything makes sense.
- CHAR – Not actually used in the code below but I’m including it for completeness. Converts an integer into it’s associated ASCII value.
- NCHAR – Converts an integer into it’s associated UNICODE value.
- ASCII – Returns the integer associated (as defined by ASCII) with the leftmost character of the string passed to it.
- UNICODE – Returns the integer associated (as defined by UNICODE) with the leftmost character of the strong passed to it.
- DATALENGTH – Returns the number of byte used to store the string.
CREATE TABLE #TestTable (English VARCHAR(2), Japanese VARCHAR(2) COLLATE Japanese_Unicode_CI_AS); WITH nums (num) AS ( SELECT TOP (65536) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM [master].[sys].[columns] sc1 CROSS JOIN [master].[sys].[columns] sc2 ) INSERT INTO #TestTable SELECT NCHAR(num-1), NCHAR(num-1) FROM nums; -- Using the English collation -- There will be no double width characters. SELECT English, ASCII(English) English_ASCII, UNICODE(English) English_UNICODE FROM #TestTable WHERE DATALENGTH(English) > 1; -- Using the Japanese collation -- There are over 9000 rows with double -- width characters. SELECT Japanese, ASCII(Japanese) Japanese_ASCII, UNICODE(Japanese) Japanese_UNICODE FROM #TestTable WHERE DATALENGTH(Japanese) > 1;
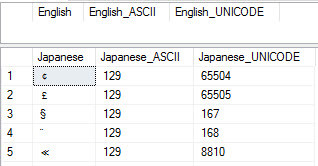
Another interesting query:
SELECT COUNT(DISTINCT English) English_Chars, COUNT(DISTINCT Japanese) Japanese_Chars FROM #TestTable
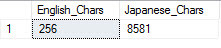
Even though I only inserted a single character (and the same one at that) into the two columns (different collations remember) one had the 256 characters I would expect and the other had a whopping 8581 distinct characters! (Actually if you look at the UNICODE values there are 9402 characters so I guess some are duplicates.)
Filed under: Microsoft SQL Server, SQLServerPedia Syndication, T-SQL 






![]()
