Profiler and Tuning Advisor Stats Recommendation
-
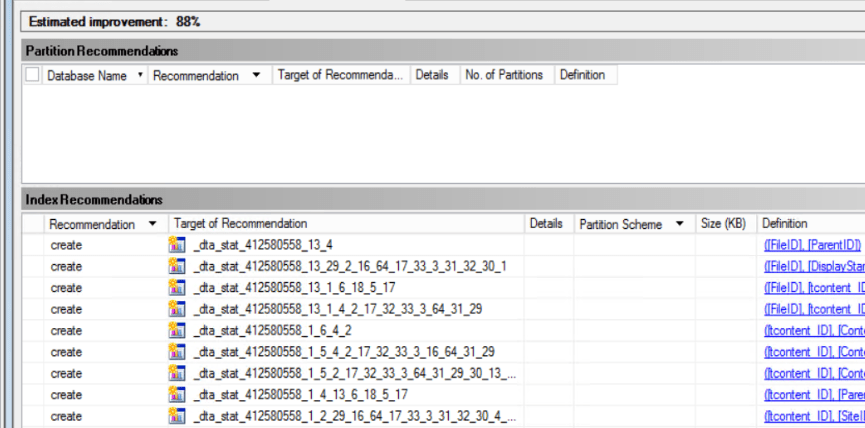
I ran SQL Profiler and did a trace, and after handing the file off to the Tuning Advisor, it had some Index recommendations which is understandable. However, there are a ton of statistics recommendations. The capture I did was only for about 20 seconds. The recommendations were very numerous, but the main thing is that it stated there would be an 88% performance benefit. Is this something to be concerned with?

-
The Database Tuning Advisor is an actively dangerous tool to use. It makes a lot of recommendations. Most of the time, they're useless. You can see right there in the column definitions that the leading edge for the first four recommendations is all FileID. Duplication of statistics (or indexes) is an issue. Not the third & fourth one have the same leading column and the same second column. Not sure what the third, fourth, etc., are, but I'd put money down, this stuff doesn't help you with your database. Further, adding all these will add overhead to your system because now you have to maintain all these stats. Further, any query referencing these stats will get recompiled as they update, so they better radically enhance performance (they won't).
The problem space of query tuning is difficult. It just is. There's a ton of knowledge needed, some skill and practice, and even a little bit of luck. What people want is either a very simple prescription, "if A do Z", or a tool that just does it all for you. DTA was supposed to be that tool. It isn't.
So, run it if you want to (although, I never use it), but take everything it recommends with a grain of salt the size of a Buick. Test it with the assumption that it's flat out wrong. Most importantly, watch for duplication of indexes (and stats). The more they stack up (like the second three in your graphic above, all with the same first three columns), the less you should trust them. Normally the saying is "trust but verify." However, with the DTA it should be "no trust at all, so verify."
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
Thanks for your feedback Grant, and for confirming my suspicion. I was noticing the many many duplicate suggestions and thought it seemed extremely generic in nature. It seems it wants a non-clustered index on just about every column. It seems like as a DBA I am at the mercy of how the developers configured the database, and just hope they did it correctly. I'd like to gain some insight and at least be able to spot some obvious changes that need to be made at the structure/design level of the database. Do you think that learning some basic SQL programming (beyond just the DBA basics) and query writing would be a good direction? Or, perhaps, just tracking down very obvious queries at first to gain some experience?
- Grant Fritchey wrote:
... but take everything it recommends with a grain of salt the size of a Buick.
BWAAAA-HAAAA-HAAAAA!!!! Man, am I ever glad I didn't have a mouthful of coffee when I read that! 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - stevec883 wrote:
Thanks for your feedback Grant, and for confirming my suspicion. I was noticing the many many duplicate suggestions and thought it seemed extremely generic in nature. It seems it wants a non-clustered index on just about every column. It seems like as a DBA I am at the mercy of how the developers configured the database, and just hope they did it correctly. I'd like to gain some insight and at least be able to spot some obvious changes that need to be made at the structure/design level of the database. Do you think that learning some basic SQL programming (beyond just the DBA basics) and query writing would be a good direction? Or, perhaps, just tracking down very obvious queries at first to gain some experience?
Yes. That's it entirely.
I'm not a fan of Profiler/Trace, however, it works well enough (Extended Events works better). Capture queries for 1/2 hour to an hour at the height of the day. Aggregate the info. Look for the ones that are 1) call most frequently, 2) Use the most resources 3) Run the longest 4) All of the above. Those are the first problem children. Don't worry, once you clear out those problem children, there will be more. Generally, identify the poorest performer, eyeball the code, see if you can spot common code smells. Attack those first. Then, get the execution plan. That will give you the nitty gritty to look at to understand if an index(es) will help or if you need to adjust the code.
Wash, rinse, repeat.
Welcome to query tuning.
If you can, get engaged with the dev team. Buy 'em a beer (or beverage). Start getting an eyeball on the code and structures before they go out the door. It's easier to tune stuff before it gets to production. A lot easier. However, you may have to work backwards from prod. Happens all the time. Document what you do, carefully. Identify patterns. Communicate those to the dev teams. Show how they could change the code, or structures, early on to prevent problems. All this ought to be, but frequently isn't, a partnership.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
Having been a sys admin for a long time, I do understand the separate worlds of developers vs everyone else, but sounds like a plan! I'll let you know how the first year goes LOL. Thanks again.
-
Sure thing. And since you're just getting started in the wide world of query tuning, I'd suggest getting copies of my books (one is free in digital mode). Also a copy of Itzik Ben-Gan's book on T-SQL.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
Even though I'm a fan of SQL Profiler, I don't use it to find queries that may be an issue. I've also found that "long running queries" are not usually the biggest problem even if they're the longest running code.
What I have found is that the shorter running queries are the biggest problem especially when it comes to memory reads (logical reads) and CPU. These are the same queries that show up when you right click on the instance name in the Explorer Window of SSMS and go through the IO and CPU performance reports. I also find those reports a bit annoying because they'll show you the troublesome part of a stored procedure or ad hoc query from the front-end but it won't show you all of the code.
For a long time, I didn't know about Adam Machanic's "sp_WhoIsActive" and wrote my own little ditty to find such things. I continue to use it because it does what I want for me but I strongly recommend landing a copy of Adam's code because it will actually help you find the true problems in your system. You might also want to have a look at the following article by Jonathan Kehayias on compile times, which doesn't show up in any of the suggested items above. We had a known issue with a stored procedure that run in "only"100 ms but the data for the screens it powered were taking a very, very long time to return. It turned out that the compile time for the proc was 2 to 22 SECONDs and because of the manner in which it was written, it compiled EVERY time it was called. After we fixed it, not only did it stop recompiling every time it was called but the compile times also dropped to less than 20 ms and the run time dropped to a range of between 4 and 10 ms.
As a bit of a warning and advice, be aware that all of the methods above are based on what's in cache. Some of what's in cache can be there for days or weeks (although most folks end up with some code that basically clears all cache) and so you MUST be aware of when the code appeared in cache to judge things like total I/O and CPU consumed.
To add some encouragement, back in my early days with my current company, we fixed (by rewriting parts of the code and creating the right indexes) the top 6 items that appeared on the ditty I wrote and CPU and I/O. Average CPU started out at about 60% and dropped to about 20% when we fixed those 6 items. It didn't take much effort to do so, either. We actively file off the high spots on an occasional basis and we've been able to keep CPU down in the 8-12% range for most of the daily activities even though our main databases have grown for 65GB to 2TB in the last 8 years and there's a shedload more code and databases. We call it the "Continuous Improvement Program" although the Dev Manager gave it the nickname of "The Dirty Dozen".
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Thanks Jeff! I will defintely take a look at the scripts and approach. Appreciate the input!
Viewing 9 posts - 1 through 9 (of 9 total)
You must be logged in to reply to this topic. Login to reply