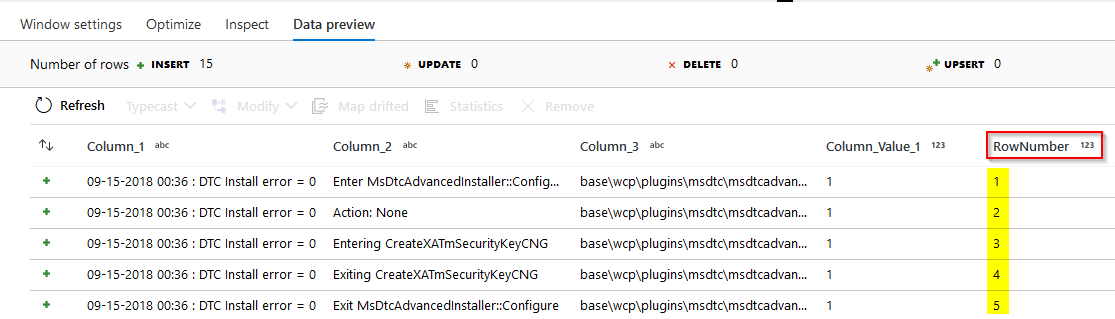
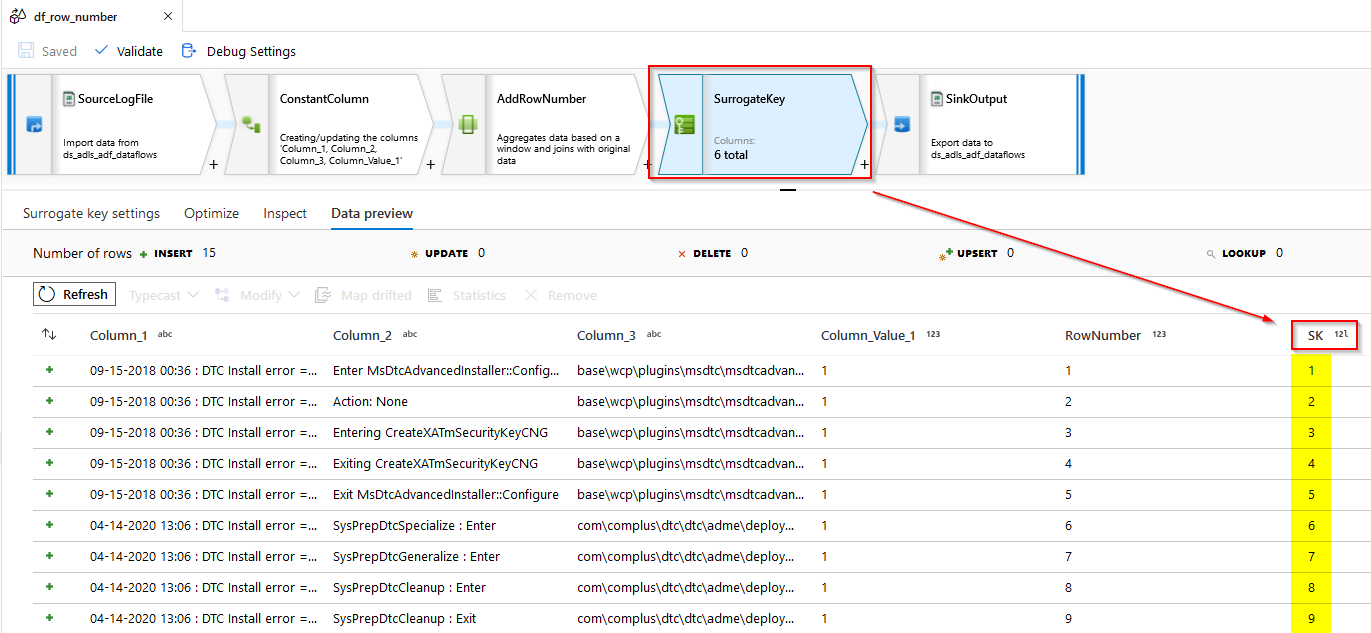
(2020-Oct-05) Adding a row number to your dataset could a trivial task. Both ANSI and Spark SQL have the row_number() window function that can enrich your data with a unique number for your whole or partitioned data recordset.
Recently I had a case of creating a data flow in Azure Data Factory (ADF) where there was a need to add a row number.

Instant reaction was to this new additional row number column using a derived column transformation - https://docs.microsoft.com/en-us/azure//data-factory/data-flow-derived-column. However, this was my mistake and ADF notified me that rowNumber() - data flow function was only available in the Windows transformations - https://docs.microsoft.com/en-us/azure/data-factory/data-flow-window.

OK, I moved on and added a Window Transformation task, which does require at least one sorting column.

However, this was a bit of an issue in my data case. I didn’t need to sort and change the order of my recordset. Transformed dataset needed to be in the same order as its original sourcing data, as it would help to locate a transformed data record with its sourcing sibling record with the help of the new Row Number column.