about the option (fast n) and acutal execution plan
-
- what kind of situation can I use "option (fast 1)" when I execute a Select/update/delete statement ? such as: select *from tablename where f1='test' option (fast 1)
- when I execute 2 select sql statement, the 2 sql statement is same ,but the difference is the first sql statment doesn't have "option (fast 1) but the second sql statement has "option (fast 1), when I show their actual execution plan, the first one Query cost(relative to the batch) 62%, the second Query cost(relative to the batch) 38% , but I double check the second sql statement takes more IO reads and more CPU time ?elapsed time , why the query cost of second statement is much lower than 1st statement?
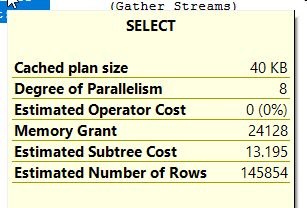
3. there are some parameters of execution plan such as cached plan size?Memory grant?Estimated subtree cost ...,
if we compare which sql statemest is better as the said sql statements with option (fast 1) and the sql without option (fast 1), so which parameter(s) is the critical index for us to decide which sql statement is better ?

-
Frankly the percentages from an estimated query plan are often so inaccurate they should just be ignored.
Look at the actual operations in the query plan, not the percentages.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
hmm, I saw some books or article says the execution plan is inaccurate , if like this how we can compare which sql statement is better ?
I used actual execution plan in my test. thanks!
-
Execution plans and the stats can look just like what you are seeing when you use option fast. And if you run the different queries together and see the costs relative to the batch, it will look like the no hint is the highest cost relative to the batch. You are telling the optimizer to worry about getting that fast number of rows - you can see that in the execution plans estimated rows if you hover on the select for each query. But you are still going to retrieve all the rows so the query plan is based on an incorrect number of rows. That's how you end up with an inefficient plan. That's why you see the higher reads, CPU time when using with option fast. That hint is really more for when you need to see some results rather than waiting for all the data before you see anything. It's not about overall performance or being fast, it generally hurts overall performance even if you see the first number of rows sooner.
Sue
-
thanks !
but there are some parameters of actual execution plan such as cached plan size/Memory grant/Estimated subtree cost ...,
if we compare which sql statemest is better as the said sql statements with option (fast 1) and the sql without option (fast 1), so which parameter(s) is the critical index for us to decide which sql statement is better ?
-
You don't want to run them together to compare them the way you are comparing them though - it's just not accurate. And you want to be sure you really, really, really need to use option fast. If you don't need it, don't use it. It's not going to make the query faster.
Other than that, look at the operators in the plans as Scott already suggested and look at stats io and time. Pretty much what you are doing.
Sue
- 892717952 wrote:
hmm, I saw some books or article says the execution plan is inaccurate , if like this how we can compare which sql statement is better ?
I used actual execution plan in my test. thanks!
Execution plans accurately portray "estimates" (and some actuals) if you understand the irony in that statement, which can be wildly different than what actually happens. Even the "Actual" Execution Plan is riddled with estimates.
You can use execution plans to see things like which indexes are going to be or have been used and are a very effective development tool BUT... the only way to tell which code is actually "better" for the likes of CPU, Duration, Reads, Writes, and Memory Usage is to actually run the code and measure it using SQL Profiler, Extended Events, or, if you're careful with what you're measuring (shouldn't be used when things like Scalar UDFs or mTVFs are present, for example), SET STATISTICS.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 7 posts - 1 through 7 (of 7 total)
You must be logged in to reply to this topic. Login to reply