Creating a unique Batch ID for Update
-
Hi There,
I'm trying to write a query that sets a batch of rows to have a single uniquely generated ID on the fly. Tried lots of things and just can't get it right.
Below are sample scripts to create the table and insert some test data along with two update queries that do not give me the desired results. I understand why they do not achieve what I'm looking for they are really there to show the kind of things I have tried.
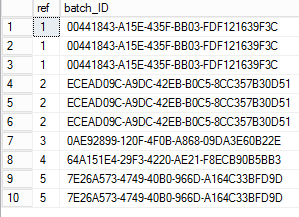
Here is an image of what i want the reults to look like. All ref numbers that match have the same uniquely generated ID. Any input would be appreciated, i might have to go a different route and happy to do so if there is a better option. Thanks for looking.

-- CODE SAMPLES
CREATE TABLE ##temp (
ref VARCHAR(MAX),
batch_ID VARCHAR(MAX)
);
INSERT INTO ##temp (ref) values(1)
INSERT INTO ##temp (ref) values(1)
INSERT INTO ##temp (ref) values(1)
INSERT INTO ##temp (ref) values(2)
INSERT INTO ##temp (ref) values(2)
INSERT INTO ##temp (ref) values(2)
INSERT INTO ##temp (ref) values(3)
INSERT INTO ##temp (ref) values(4)
INSERT INTO ##temp (ref) values(5)
INSERT INTO ##temp (ref) values(5)
select * from ##temp
-- DELETE from ##temp
-- update queries
--1
DECLARE @random_guid VARCHAR(250);
SET @random_guid = NEWID()
update ##temp set batch_id = @random_guid where ref=REF
--2
update ##temp set batch_id = NEWID() where ref=REF
DROP TABLE ##temp
-
I did something similar once. We had a version table. Everything did an insert to the version table to get a version ID, then that ID was used across all other inserts to other tables.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
Why not just use a SEQUENCE?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
As general issues go does this require ##temp to have global scope? Also, why make the variables varchar(max)? I got it to work like this
drop table if exists #temp;
go
CREATE TABLE #temp (
ref int not null,
batch_ID CHAR(36));
INSERT INTO #temp(ref) values
(1),(1),(1),(2),(2),(2),(3),(4),(5),(5);
update t
set batch_ID=rt.nid
from #temp t
join
(select distinct ref, newid() nid from #temp) rt on t.ref=rt.ref;Output
refbatch_ID
112EAAEFE-EC57-455A-ACCE-A18F3B6415D8
112EAAEFE-EC57-455A-ACCE-A18F3B6415D8
112EAAEFE-EC57-455A-ACCE-A18F3B6415D8
2F245A746-60C0-4FBA-B168-74ACB034243C
2F245A746-60C0-4FBA-B168-74ACB034243C
2F245A746-60C0-4FBA-B168-74ACB034243C
3AAF89776-C887-4245-B9DB-3CE47311E8A2
49DAD6FD8-D5AE-493C-AB94-276B2C73C30A
5AC0B546A-F21B-46C3-9CDB-07FF58E7FBE6
5AC0B546A-F21B-46C3-9CDB-07FF58E7FBE6Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
- Steve Collins wrote:
As general issues go does this require ##temp to have global scope? Also, why make the variables varchar(max)? I got it to work like this
drop table if exists #temp;
go
CREATE TABLE #temp (
ref int not null,
batch_ID CHAR(36));
INSERT INTO #temp(ref) values
(1),(1),(1),(2),(2),(2),(3),(4),(5),(5);
update t
set batch_ID=rt.nid
from #temp t
join
(select distinct ref, newid() nid from #temp) rt on t.ref=rt.ref;Output
refbatch_ID
112EAAEFE-EC57-455A-ACCE-A18F3B6415D8
112EAAEFE-EC57-455A-ACCE-A18F3B6415D8
112EAAEFE-EC57-455A-ACCE-A18F3B6415D8
2F245A746-60C0-4FBA-B168-74ACB034243C
2F245A746-60C0-4FBA-B168-74ACB034243C
2F245A746-60C0-4FBA-B168-74ACB034243C
3AAF89776-C887-4245-B9DB-3CE47311E8A2
49DAD6FD8-D5AE-493C-AB94-276B2C73C30A
5AC0B546A-F21B-46C3-9CDB-07FF58E7FBE6
5AC0B546A-F21B-46C3-9CDB-07FF58E7FBE6Just a performance tip... You might want to use a WHERE EXISTS instead of a SELECT DISTINCT with a join.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Steve Collins wrote:
As general issues go does this require ##temp to have global scope? Also, why make the variables varchar(max)? I got it to work like this
drop table if exists #temp;
go
CREATE TABLE #temp (
ref int not null,
batch_ID CHAR(36));
INSERT INTO #temp(ref) values
(1),(1),(1),(2),(2),(2),(3),(4),(5),(5);
update t
set batch_ID=rt.nid
from #temp t
join
(select distinct ref, newid() nid from #temp) rt on t.ref=rt.ref;Output
refbatch_ID
112EAAEFE-EC57-455A-ACCE-A18F3B6415D8
112EAAEFE-EC57-455A-ACCE-A18F3B6415D8
112EAAEFE-EC57-455A-ACCE-A18F3B6415D8
2F245A746-60C0-4FBA-B168-74ACB034243C
2F245A746-60C0-4FBA-B168-74ACB034243C
2F245A746-60C0-4FBA-B168-74ACB034243C
3AAF89776-C887-4245-B9DB-3CE47311E8A2
49DAD6FD8-D5AE-493C-AB94-276B2C73C30A
5AC0B546A-F21B-46C3-9CDB-07FF58E7FBE6
5AC0B546A-F21B-46C3-9CDB-07FF58E7FBE6Keep in mind that'll update all the batch id's every time which might not be intended or a good idea on a large table. Adding a WHERE batch_ID IS NULL on the self join should fix that.
- ZZartin wrote:
Keep in mind that'll update all the batch id's every time which might not be intended or a good idea on a large table. Adding a WHERE batch_ID IS NULL on the self join should fix that.
Something like this?
update t
set batch_ID=rt.nid
from #temp t
join (select distinct ref, newid() nid from #temp) rt on t.ref=rt.ref
where batch_ID is null;Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
Thanks guys really appreciate your input and great solutions.
Viewing 8 posts - 1 through 8 (of 8 total)
You must be logged in to reply to this topic. Login to reply