Parse Semi colon data in seperate columns
-
Hi:
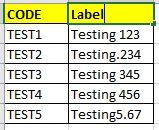
I have semi-colon separated data in one column and I would like to split that in separate columns.
CREATE TABLE #tblTest
(FileData nvarchar(MAX))
INSERT INTO #tblTest values ('TEST1;Testing 123;')
INSERT INTO #tblTest values ('TEST2;Testing.234;')
INSERT INTO #tblTest values ('TEST3;Testing 345;')
INSERT INTO #tblTest values ('TEST4;Testing 456;')
INSERT INTO #tblTest values ('TEST5;Testing5.67;')
SELECT * FROM #tblTestI tried using parsename(), but it is not working.
SELECT parsename(FileData, 3) AS Code
,parsename(FileData, 2) AS Label
FROM (
SELECT replace(FileData, ';', '.') FileData
FROM #tblTest
) tEXPECTED Output:

Thanks!
-
Parsename() works only on strings which have . (full-stop) as their delimiter.
If there are only ever two columns, here is one way:
DROP TABLE IF EXISTS #Test;
CREATE TABLE #Test
(
FileData NVARCHAR(MAX)
);
INSERT #Test
VALUES
('TEST1;Testing 123;')
,('TEST2;Testing.234;')
,('TEST3;Testing 345;')
,('TEST4;Testing 456;')
,('TEST5;Testing5.67;');
SELECT Code = TRIM(LEFT(t1.FileData, t2.Pos - 1))
,Label = TRIM(REPLACE(RIGHT(t1.FileData, LEN(t1.FileData) - t2.Pos), ';', ''))
FROM #Test t1
CROSS APPLY
(SELECT Pos = CHARINDEX(';', t1.FileData)) t2; -
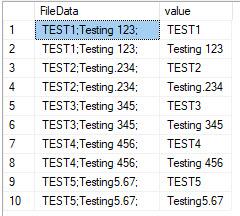
This worked:
SELECT t.*
, ca.value
FROM #tblTest t
CROSS APPLY STRING_SPLIT(t.FileData, ';') ca
WHERE LEN(TRIM(ca.Value))>0; -
It is giving me error on TRIM that 'TRIM' is not a recognized built-in function name. We are on SQL Server 2016.
- pietlinden wrote:
This worked:
SELECT t.*
, ca.value
FROM #tblTest t
CROSS APPLY STRING_SPLIT(t.FileData, ';') ca
WHERE LEN(TRIM(ca.Value))>0;Really?
-
Instead of
TRIM(x)
Use
LTRIM(RTRIM(x))
-
You can start with something like this:
Declare @pDelimiter char(1) = ';';
Select tt.FileData
, p01_pos = p01.pos
, p02_pos = p02.pos
, p03_pos = p03.pos
, col_01 = ltrim(substring(v.FileData, 1, p01.pos - 2))
, col_02 = ltrim(substring(v.FileData, p01.pos, p02.pos - p01.pos - 1))
, col_03 = ltrim(substring(v.FileData, p02.pos, p03.pos - p02.pos - 1))
From #tblTest tt
Cross Apply (Values (concat(tt.FileData, replicate(@pDelimiter, 3)))) As v(FileData)
Cross Apply (Values (charindex(@pDelimiter, v.FileData, 1) + 1)) As p01(pos)
Cross Apply (Values (charindex(@pDelimiter, v.FileData, p01.pos) + 1)) As p02(pos)
Cross Apply (Values (charindex(@pDelimiter, v.FileData, p02.pos) + 1)) As p03(pos);You can create an inline-table valued function from this and expand to as many columns you need returned or just incorporate into your code as needed.
This handles cases where you have no delimiters or less than 3 delimiters - for example:
Drop Table If Exists #tblTest;
Create Table #tblTest (FileData nvarchar(4000))
Insert Into #tblTest
Values ('Testing 0 delimiters')
, ('Testing 1 delimiter;One')
, ('Testing 2 delimiters;Two;')
, ('Testing 3 delimiters;Three;Third;');
Declare @pDelimiter nchar(1) = ';';
Select tt.FileData
, p01_pos = p01.pos
, p02_pos = p02.pos
, p03_pos = p03.pos
, col_01 = ltrim(substring(v.FileData, 1, p01.pos - 2))
, col_02 = ltrim(substring(v.FileData, p01.pos, p02.pos - p01.pos - 1))
, col_03 = ltrim(substring(v.FileData, p02.pos, p03.pos - p02.pos - 1))
From #tblTest As tt
Cross Apply (Values (concat(tt.FileData, replicate(@pDelimiter, 3)))) As v(FileData)
Cross Apply (Values (charindex(@pDelimiter, v.FileData, 1) + 1)) As p01(pos)
Cross Apply (Values (charindex(@pDelimiter, v.FileData, p01.pos) + 1)) As p02(pos)
Cross Apply (Values (charindex(@pDelimiter, v.FileData, p02.pos) + 1)) As p03(pos);Since a function cannot be dynamic - I would build out a function that meets the requirements for as many columns as might possibly be needed. Only return the columns that are required...for example, create a function to return 12 columns and only return the 2 columns you actually need - SQL Server will optimize out the extra calls if those columns are not used in the calling query.
One more note - don't use nvarchar(max) unless you know for sure your strings will exceed 4000 characters. This will force an implicit conversion that can cause cardinality issues for your queries.
Here is an example 12 column function:
CREATE Function [dbo].[fnSplitStringToColumns] (
@pString nvarchar(4000)
, @pDelimiter nchar(1)
)
Returns Table
With schemabinding
As
Return
Select InputString = @pString
, p01_pos = p01.pos
, p02_pos = p02.pos
, p03_pos = p03.pos
, p04_pos = p04.pos
, p05_pos = p05.pos
, p06_pos = p06.pos
, p07_pos = p07.pos
, p08_pos = p08.pos
, p09_pos = p09.pos
, p10_pos = p10.pos
, p11_pos = p11.pos
, p12_pos = p12.pos
, col_01 = ltrim(substring(v.inputString, 1, p01.pos - 2))
, col_02 = ltrim(substring(v.inputString, p01.pos, p02.pos - p01.pos - 1))
, col_03 = ltrim(substring(v.inputString, p02.pos, p03.pos - p02.pos - 1))
, col_04 = ltrim(substring(v.inputString, p03.pos, p04.pos - p03.pos - 1))
, col_05 = ltrim(substring(v.inputString, p04.pos, p05.pos - p04.pos - 1))
, col_06 = ltrim(substring(v.inputString, p05.pos, p06.pos - p05.pos - 1))
, col_07 = ltrim(substring(v.inputString, p06.pos, p07.pos - p06.pos - 1))
, col_08 = ltrim(substring(v.inputString, p07.pos, p08.pos - p07.pos - 1))
, col_09 = ltrim(substring(v.inputString, p08.pos, p09.pos - p08.pos - 1))
, col_10 = ltrim(substring(v.inputString, p09.pos, p10.pos - p09.pos - 1))
, col_11 = ltrim(substring(v.inputString, p10.pos, p11.pos - p10.pos - 1))
, col_12 = ltrim(substring(v.inputString, p11.pos, p12.pos - p11.pos - 1))
From (Values (concat(@pString, replicate(@pDelimiter, 12)))) As v(inputString)
Cross Apply (Values (charindex(@pDelimiter, v.inputString, 1) + 1)) As p01(pos)
Cross Apply (Values (charindex(@pDelimiter, v.inputString, p01.pos) + 1)) As p02(pos)
Cross Apply (Values (charindex(@pDelimiter, v.inputString, p02.pos) + 1)) As p03(pos)
Cross Apply (Values (charindex(@pDelimiter, v.inputString, p03.pos) + 1)) As p04(pos)
Cross Apply (Values (charindex(@pDelimiter, v.inputString, p04.pos) + 1)) As p05(pos)
Cross Apply (Values (charindex(@pDelimiter, v.inputString, p05.pos) + 1)) As p06(pos)
Cross Apply (Values (charindex(@pDelimiter, v.inputString, p06.pos) + 1)) As p07(pos)
Cross Apply (Values (charindex(@pDelimiter, v.inputString, p07.pos) + 1)) As p08(pos)
Cross Apply (Values (charindex(@pDelimiter, v.inputString, p08.pos) + 1)) As p09(pos)
Cross Apply (Values (charindex(@pDelimiter, v.inputString, p09.pos) + 1)) As p10(pos)
Cross Apply (Values (charindex(@pDelimiter, v.inputString, p10.pos) + 1)) As p11(pos)
Cross Apply (Values (charindex(@pDelimiter, v.inputString, p11.pos) + 1)) As p12(pos);Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs - SQL Server wrote:
Hi:
I have semi-colon separated data in one column and I would like to split that in separate columns.
May I ask you where do you have the data coming from and where do you want to send the separated columns?
_____________
Code for TallyGenerator -
Quick question, how large is the data set that you are working with? What is the actual table structure?
😎
There are many ways to solve this trivial problem, parsename() is not one of those, but performance will vary substantially
Viewing 9 posts - 1 through 9 (of 9 total)
You must be logged in to reply to this topic. Login to reply