

What is partitioning.
To start with partition is the feature provided by SQL server in which very large tables are split between multiple files and file-groups for ease of access and faster retrieval/ update purposes.
Consider a table which consists of millions of records. When we insert all the records in one table, in one file; retrieval or update time for any of the record even if it involves index seek is considerably high. A better option would be to split the table based on certain column values. Let the data be spread across multiple file-groups.
When a search condition is encountered comprising on that column value SQL server will now have to look at smaller chunks of data of any one of those multiple files, thus resulting faster retrieval and execution time.
Consider a table which consists of millions of records. When we insert all the records in one table, in one file; retrieval or update time for any of the record even if it involves index seek is considerably high. A better option would be to split the table based on certain column values. Let the data be spread across multiple file-groups.
When a search condition is encountered comprising on that column value SQL server will now have to look at smaller chunks of data of any one of those multiple files, thus resulting faster retrieval and execution time.
How to create partitions
Step 1: Create File Groups
Obviously we shall first begin with creating different file groups and allocating files to each group. This can be done from the management studio as follows under the Database Property-> Filegroups Section
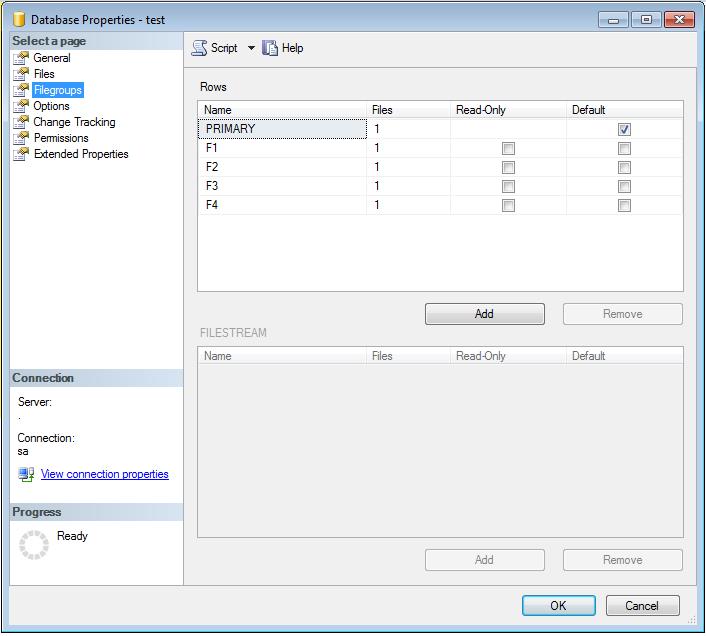
Step 2: Assign files to these groups
Next step is creating files and assigning them to these groups. We may assign multiple files to one file group. SQL server will use proportional fill algorithm when data is inserted into these files.Below image depicts one file assigned to each groups.
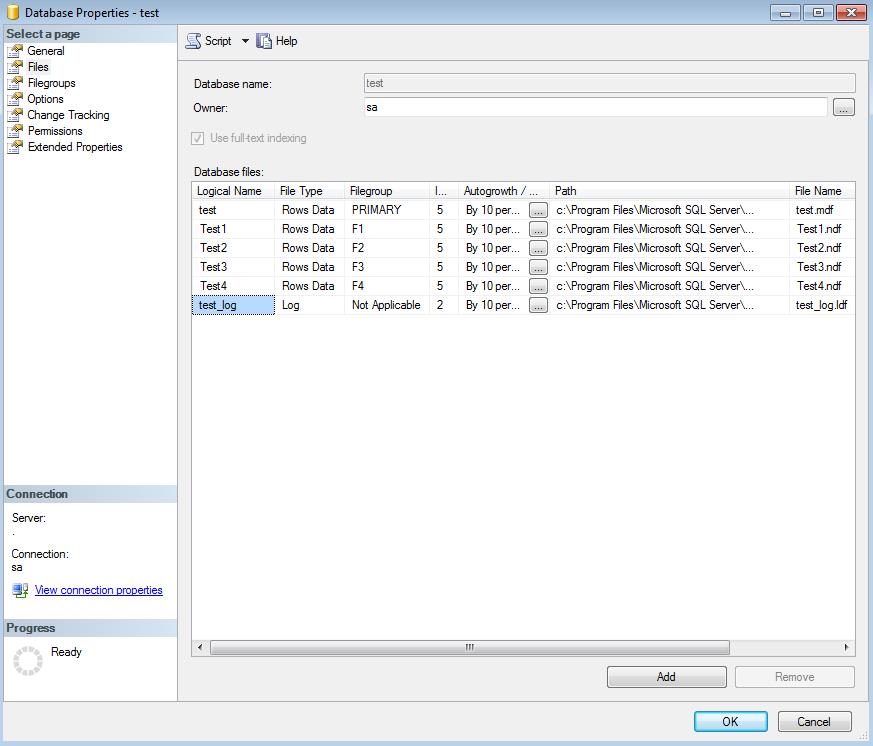
If you love coding below is the T-SQL for the same
USE [master]
GO
ALTER DATABASE[test] ADD FILEGROUP[F1]
GO
ALTER DATABASE[test] ADD FILE ( NAME = N'Test1', FILENAME = N'c:\Program Files\Microsoft SQL Server\MSSQL11.SQL\MSSQL\DATA\Test1.ndf' ,SIZE = 5120KB ,FILEGROWTH = 10%)TO FILEGROUP[F1]
GO
ALTER DATABASE[test] ADD FILEGROUP[F2]
GO
ALTER DATABASE[test] ADD FILE ( NAME = N'Test2', FILENAME = N'c:\Program Files\Microsoft SQL Server\MSSQL11.SQL\MSSQL\DATA\Test2.ndf' ,SIZE = 5120KB ,FILEGROWTH = 10%)TO FILEGROUP[F2]
GO
ALTER DATABASE[test] ADD FILEGROUP[F3]
GO
ALTER DATABASE[test] ADD FILE ( NAME = N'Test3', FILENAME = N'c:\Program Files\Microsoft SQL Server\MSSQL11.SQL\MSSQL\DATA\Test3.ndf', SIZE = 5120KB , FILEGROWTH =10%) TO FILEGROUP [F3]
GO
ALTER DATABASE[test] ADD FILEGROUP[F4]
GO
ALTER DATABASE[test] ADD FILE ( NAME = N'Test4', FILENAME = N'c:\Program Files\Microsoft SQL Server\MSSQL11.SQL\MSSQL\DATA\Test4.ndf', SIZE = 5120KB , FILEGROWTH =10%) TO FILEGROUP [F4]
GO
Step 3: Deciding the column for partition
Next step is for us to decide the criteria on which data will be partitioned. Ideally tables that contain historic data are partitioned. In our example we will be implementing this for similar OrderDetail Table. Data will be partitioned based on OrderDate. Structure is as follows.
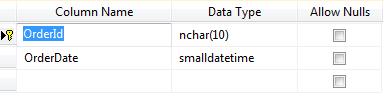
Step 4: Creating Partition Function
First we shall create decide the ranges which is defined by the partition function
In our case the function will be as below
CREATE PARTITIONFUNCTION [OrderDatesMonthly] (datetime)
In our case the function will be as below
CREATE PARTITIONFUNCTION [OrderDatesMonthly] (datetime)
AS RANGELEFT FOR VALUES ('20150401','20150701','20151001');
Since we have specified 11 values our total number of partitions will be 3+1 =4.
Partition | Values | |
1 | date<=20150401 | <= 1st April 2015 |
2 | date<=20150701 | <= 1st July 2015 |
3 | date<=20151001 | <= 1st October 2015 |
4 | date>20151201 | > 1st October 2015 |
I’ve used theRANGE LEFT option here. One may also choose to opt for RANGE RIGHT. For example
CREATE PARTITIONFUNCTION [OrderDatesMonthly] (datetime)
AS RANGERIGHT FOR VALUES ('20150330','20150630','20150930');
Step 5 : Creating Partition Scheme
Now that we’ve split the range lets map it to different filegroups. Ranges are split with functions. Split ranges are mapped with schemes. In our case the scheme will be
CREATE PARTITION SCHEME [OrderDatesMonthlyScheme]
AS PARTITION [OrderDatesMonthly] TO (F1, F2, F3, F4);
Step 6: Breaking the table
Our range is set our file-groups are mapped so now let’s break our tables into smaller manageable chunks.
CREATE TABLE dbo.[OrderTable](
[OrderId] [nchar](10) NOT NULL,
[OrderId] [nchar](10) NOT NULL,
[OrderDate] [smalldatetime] NOT NULL,
CONSTRAINT[PK_OrderTable] PRIMARY KEY CLUSTERED
(
[OrderId] ASC
)
) ONOrderDatesMonthlyScheme(OrderDate)
GO
In just 6 steps we saw how too break large tables into partition tables.
In the coming blogs we will learn how to move data between such tables.
In just 6 steps we saw how too break large tables into partition tables.
In the coming blogs we will learn how to move data between such tables.
