Index Optimize
-
Based on my understanding during the index optimize it will not take the whole database down. However, there would be impact on the performance. Do you agree with this? If yes, would you schedule any jobs during the index maintenance?
-
Also integrity check.
-
TLDR: If you can avoid running other performance-sensitive or resource-intensive jobs during reindexing and CHECK* jobs, do it.
Longer explanation:
Here are some of the major possible pain points.
IO:
Both reindexing and CHECK* commands can be very IO-intensive, so if you don't have a lot of performance headroom in your IO subsystem, you can see performance degradation from hitting an IO bottleneck.
CPU:
Typically this is hit to a lesser degree than IO, but both reindexing and CHECK* commands (especially the latter when doing full logical checks) can use a decent bit of CPU, so if your system doesn't have ample CPU headroom, you could see performance degradation from hitting a CPU bottleneck.
Blocking:
CHECK* commands use a database snapshot by default, so you won't see blocking issues from that (although you can choose to run them using locks instead, which will block any concurrent activity) . However, in Standard edition, index rebuilds hold a schema modification lock on the object for the duration of the rebuild. Schema modification locks block-and-are -blocked-by everything, so this can be a major pain point.
In all editions, index reorganizations also take locks, but these are both more granular and shorter-lived than the schema modification locks taken by rebuilds in standard edition. Nevertheless, they can cause performance degradation from blocking if there's a lot of concurrent access taking conflicting locks.
Snapshot overhead:
When using CHECK* commands with the default behavior using a snapshot, the first time a page changes after the snapshot is created, the pre-change version of the change is written to the snapshot. If you have a lot of write activity, this can lead to substantial performance overhead.
Disk space:
With CHECK* commands using a snapshot, you'll need enough disk space to accommodate the growth of the sparse files implementing the snapshot. The more write-intensive your workload and the longer the CHECK* command runs, the bigger the snapshot will be.
With online index rebuilds, you'll need enough extra space to accommodate the extra copy of the index SQL Server builds behind the scenes before it swaps it in. If you have very large indexes relative to your free space, this can be a concern.
Index rebuilds are done in a single transaction, so they will prevent log truncation for the duration of the rebuild, in addition to writing pretty heavily to the log.
Index reorganizations are done in a bunch of small transactions, so they don't prevent log truncation as dramatically as rebuilds, but they do still write pretty heavily to the log, depending on how much work they have to do.
Cheers!
-
Thanks! I have seen some places these maintenance are run daily and other places once a week. My understanding is the decision should be made based on how bad the indexes are fragmented. Do you agree? Also, if you run integrity check once a week that means there is a risk of corruption if it runs once a week? Please advise?
-
On integrity checks, yes, the longer you go between checks, the more potential data loss you're exposed to in a worst-case scenario.
For that reason, the more frequently you can get away with running checks, the better, all else being equal. If you have the resources to do it, it's nice to have a dedicated system where you restore your full/diff backups and run CHECK* there. This not only offloads most of the CHECK* work (if it shows errors on the system with the restored copy, you'll still need to run it on the source, and you may want to run it occasionally on the source anyway), but tests your backups as well.
For reindexing, the "standard" advice floating around is still to reindex based on logical fragmentation percent.
For a variety of reasons we can get into if necessary, I don't think running some blanket reindexing process based only on logical fragmentation percent provides a net benefit in most environments, but it is still the most commonly given advice.
Cheers!
-
Thanks again! For reindexing, so decision has to be made based on logical fragmentation percent right? So wanted to make sure i have the %Fragmentation for few tables approx 70, 80% , 90% even after running daily index rebuild job. It's pretty huge db, but not sure many tables get's updated Vs we have other DB where we run once a week index rebuild and more tables get updated. Any idea why? Is this because they may not have maintenance window to run?
-
The decision on whether to reindex definitely does NOT have to be made based on logical fragmentation percent.
That is most common, but as I said in the previous post, for many reasons I doubt that approach is a net benefit in most environments.
I prefer to reindex only those indexes for which there is a compelling case based on the workload.
Cheers!
- Jacob Wilkins wrote:
For reindexing, the "standard" advice floating around is still to reindex based on logical fragmentation percent.
For a variety of reasons we can get into if necessary, I don't think running some blanket reindexing process based only on logical fragmentation percent provides a net benefit in most environments, but it is still the most commonly given advice.
Cheers!
I've created a series of presentations on that very subject and your thoughts on what you're calling a "blanket reindexing process" are absolutely correct. In fact, what people are calling a "Best Practice" of Reorganizing at 5-30% logical fragmentation and Rebuilding at > 30% was never intended to be a "Best Practice". It was a suggested starting point and it says so right in Books Online.
I'll also state that Reorganizing is one of the worst things you can actually do to a whole lot of indexes (especially ones based on random GUIDs and other "evenly distributed" indexes) and the starting point of 5% is quite incorrect for a lot of indexes (especially random GUIDs where you should REBUILD at 1% and NEVER REORGANIZE) not to mention that they should usually be rebuilds even if you have Standard Edition because REORGANIZE is not the tame little kitty that a lot of people think it is.
Heh... and anyone that rebuilds or reorganizes tables in a database with the default Fill Factor of "0" has no idea how much "morning after" blocking, page splits, extra log file usage, and fragmentation they're actually causing.
People also need to stop calling tools that do simple index maintenance, especially those based only on logical fragmentation and especially those that REORGANIZE indexes based on some trite parameter, index "optimizers" because they not only NOT optimizing squat but they also causing blocking, page splits, extra log file usage, and fragmentation. Oddly enough, they're like a bad drug habit because the more you use them, the more you need to use them especially (like I said) for indexes that have been left at the default of "0".
There's also another really bad habit that people need to stop doing. Another supposed "Best Practice" is that if you have an index that fragments, you just need to lower the Fill Factor. That is SO WRONG in so many cases, especially if you have "ever increasing keys" like IDENTITY, NEWSEQUENTIALID, or dates or whatever. Again, people don't know what they don't know. If you do an insert on such an index, the new rows always go into the last logical page of the index. It doesn't matter what the Fill Factor is, that page will continue to fill until it's full (as close to 100% as the number of rows per page will allow) with no "BAD" page splits. If you then turn around and process those new full pages and make virtually ANY change that expands the size of the row even by as little as one byte, BOOM! The pages will split even if the Fill Factor is as low as 1% because the pages are FULL! And having the lower Fill Factor where none of the already processed rows live is just wasting memory and disk space.
I also went from Jan 18th, 2016 until very recently with NO scheduled index maintenance as a long term experiment. The only thing I'd do on a regular basis was to update the statistics. Without me doing anything else, my CPU usage across 16 core (32 threads back then, 48 two years ago) dropped from an average of 22% to 8% after 3 months of not doing any index maintenance and stayed there (but there are some long term disadvantages)!
On the flip side of things, people that are doing REBUILDs at 70% logical fragmentation (several articles around that on the internet) are also doing it wrong.
And, no... my 4 year long experiment also shows that you can't just not do any index maintenance although not doing any index maintenance (still rebuilding stats, though) is MUCH better than doing the wrong index maintenance.
And that's just the beginning. I actually did find a "right way" to assign the proper Fill Factors and do defragmentation of indexes but it would take too long here. Even that's not a panacea though. There's always that "special" exception. 😀
So, yeah... +1000 for your post, Jacob.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
And, no... my 4 year long experiment also shows that you can't just not do any index maintenance although not doing any index maintenance (still rebuilding stats, though) is MUCH better than doing the wrong index maintenance.
And that's just the beginning. I actually did find a "right way" to assign the proper Fill Factors and do defragmentation of indexes but it would take too long here. Even that's not a panacea though. There's always that "special" exception. 😀
If I read this correctly - it seems you are saying that index maintenance needs to be based on that system. And based upon the data access patterns and table structures - and how fast/frequently the table becomes fragmented to a point where it can then (potentially) cause performance issues.
If you have a table that uses a multi-column PK as the clustered index and generally reaches 20-30% fragmentation in under 7 days - then rebuilding that index once a week with an appropriate fill factor (not 100%) would be correct for that table?
On the other hand - if you have a table with an IDENTITY as the PK clustered index and that table is only ever inserted to (infrequent or no updates) then it doesn't need to be rebuilt? If batch inserts and parallelism comes into play - then rebuilding after the batch insert would be warranted?
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs - Jeffrey Williams wrote:
If I read this correctly - it seems you are saying that index maintenance needs to be based on that system. And based upon the data access patterns and table structures - and how fast/frequently the table becomes fragmented to a point where it can then (potentially) cause performance issues.
Yes and no. What I'm saying is that if you're following currently accepted "Best Practices" of REORGANIZING when Logical Fragmentation is between 5% and 30% and REBUILDing for anything greater than 30%, you're very likely doing it all wrong. And it's not the "access patterns" that you need to be concerned with. It's the INSERT, UPDATE, and DELETE patterns (collectively "modification pattern" from here on) that you need to be concerned with because those are the only things that cause fragmentation. You also need to understand that there is both Logical Fragmentation and (what people call) Physical Fragmentation (which I simply refer to as "Page Density").
You also have to understand that the only tool that we currently use to detect either type of fragmentation is based only on averages and really provides very little insight as to what the actual modification pattern actually is. There are some types of indexes where you can make a really good guess. For example, if you have an index that has had no modifications at all (or a very tiny number) for, say, 4 weeks, there's a pretty good bet that it's either a static reference table, a rarely updated almost static reference table, or an unused table (you also need "no reads" for the latter to be true). Those can be rebuilt at 100% just to mark them as Static/Nearly static (and I DO use the Fill Factor to classify the modification pattern to control the index maintenance without the use of a separate permanent table).
I mark ever increasing indexes that have little or no fragmentation (<=1%) after 4 or more weeks that suffer modifications with a 99% Fill Factor so that I know what they are. They can still become logically fragmented over time simply because the underlying pages aren't aren't always going to be physically contiguous and I'll rebuild them if they go over 1%, which can take years to get to that point.
If similar ever increasing indexes suffer a lot of Logical Fragmentation or low Page Density, then "ExpAnsive" UPDATEs are the likely cause and I'll typically rebuild those with a 97% Fill Factor (the "7" looks like a "2" without the "foot", I'll explain that in a minute) so I recover the disk/memory space but know I have some work to do on them to prevent "ExpAnsive" UPDATEs in the future. Lowering the Fill Factor for these does absolutely nothing except to waste disk/memory space.
There are some indexes that always have a very high page density no matter how many rows you add but can fragment logically fragment to more than 20% literally overnight. If you do an analysis of the index keys, you'll probably find out that they're what I call a "Sequential Siloed" index. There's NOTHING you can to prevent the fragmentation on these because they like an "Ever-Increasing" index but they have multiple (sometimes hundreds) of insert points (not to be confused with "Evenly-Distributed" indexes, which can be fixed just by changing the Fill Factor). I rebuild these at 98% (the "8" laid on it's side looks like the infinity symbol for "always fragmenting forever") just so read aheads can work faster and I'll wait until they get to 10% to rebuild them. That sometimes means they get rebuilt every night if you do index maintenance every night.
Then there are indexes based on Random GUIDs and other very evenly distributed modification patterns. These are the ones that I'll lower the Fill Factor for. Depending on their modification rate, I'll set these to either 91%, 81%, or 71% and rebuild them when the go over 1% logical fragmentation. The "1" in the Fill Factor tells me they're "Evenly Distributed" so I know to rebuild them when they go over 1% logic fragmentation. And, no... this isn't the waste of memory or disk space you might think. We don't have the time nor space on this thread to prove it but (for example) an 81% Fill Factor will AVERAGE out at 87% memory/disk usage and have a max usage of nearly 100% (whatever the number of rows per page dictates) before they even start to fragment (which is why I rebuild them at 1% Logical Fragmentation).
Of course, "ExpAnsive" UPDATEs, out of order INSERTs (Random Silos, not GUIDs or Sequential Silos, etc) and DELETEs all play hell with all the above. The only way to fix them is to look at the index pattern of usage at the PAGE level. I've designed a tool that I call "IndexDNA™" that will actually let you see what the usage by page is in graphical form. I also created another tool that will auto-magically create an accumulator table and a trigger on the table you want to check for "Expansive Updates" and a stored procedure to help you do the analysis on the variable with columns that suffer expansion so you can decide how to fix the "ExpAnsive" UPDATEs.
So what do I do with those unknown indexes if I don't have the time to analyze them or fix them? I set their Fill Factors to 92% or 82%. The "2" in the Fill Factors is an indication to me that I don't know what the hell the index is doing but I wanted to recover the memory and disk space they're wasting while still giving them the opportunity to fill pages full without splitting (if that's what they're actually doing but don't know, at this point). Think of the "2" as "to do" because I eventually need to get to them especially if they go nuts on low page density a lot and they're big indexes (fat, long, or both).
I always do an IndexDNA™ on the really big indexes if they fragment a lot or suffer page density issues. For example, I have one Clustered Index that's now 200GB and fragments both logically and by low page density a lot even though it has an ever-increasing key. sys.dm_db_index_physical_stats and sys.dm_db_index_usage_stats would lead you to believe you have "ExpAnsive" UPDATEs working against you. That wasn't it at all, though. It turns out that there are NO "ExpAnsive" UPDATEs taking place on this index. The problem is that the people that designed the code that populates the table don't actually know how to do certain things and so they do a shedload of INSERTs and they follow that with a shedload of DELETEs. Without me figuring that out using IndexDNA™ and the "ExpAnsive" UPDATE analysis tools I built, I would have made the HUGE mistake of lowering the Fill Factor on this table. Instead and following my own rules, I rebuild it at 97% because they're never going to fix the damned thing. Since they only delete from the data they just inserted, I may be able to partition the table based on temporal keys so that I don't have to do such a large (>200GB) rebuild.
And, BTW, doing a REORGANIZE on this table when it was only 146GB caused my log file to explode from 20GB to 227GB even though the index was "only" 12% logically fragmented.
It'll be a cold day in hell (sometimes spelled as "Inrow LOBs", which I also have a fix for) before I use REORGANIZE ever again (it was also the leading cause of a lot of the major blocking I went through in Jan 2016 even on things that Fill Factors assigned).
Jeffrey Williams wrote:If you have a table that uses a multi-column PK as the clustered index and generally reaches 20-30% fragmentation in under 7 days - then rebuilding that index once a week with an appropriate fill factor (not 100%) would be correct for that table?
Ok, so for you question above, what do you now think the answer is? If your answer isn't in the form of "it might be this or that but the real answer is "It Depends"", you'd might be wrong. 😀
Jeffrey Williams wrote:On the other hand - if you have a table with an IDENTITY as the PK clustered index and that table is only ever inserted to (infrequent or no updates) then it doesn't need to be rebuilt? If batch inserts and parallelism comes into play - then rebuilding after the batch insert would be warranted?
Again, look back at what I wrote in the "rules" above and realize that, truly, "It Depends" and there is no panacea recommendation that anyone can make (especially since you can have multiple modification patterns on the same index from different sources). Like I said, I'll typically rebuild Static/Nearly Static tables at 100% and non-ExpAnsive but frequently inserted indexes at 99%. Both can go years without needing defragmentation (even if parallelism comes into play because inserts are "gathered" prior to the insert happening). If "ExpAnsive" UPDATES occur, I would have rebuilt the index at 97% and it could be a great idea to rebuild the index after large batch of UPDATEs but not after a large batch of INSERTs because it's ever-increasing and the end-of-index inserts will always fill the pages to as close to 100% as possible prior to creating a new page.
You also don't want to rebuild a 200GB Clustered Index just because such an event happened because you might be crippling everyone that's using the new data.
"Ah!", you say... "I'm going to use the ONLINE option because I have the Enterprise Edition". Heh... good luck with that. ONLINE rebuilds don't use as much log file as REORGANIZE does but, on a 146GB Clustered Index, you can expect ONLINE Rebuilds to use 146GB of log file as well as 146GB of data file space just like an OFFLINE Rebuild would. You're going to need to make a better plan like, partitioning the table or whatever.
The bottom line is that you "Must Look Eye" because, as is true with everything else in SQL Server, "It Depends" and "Nothing is a 100% panacea".
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
'data access patterns and table structure' is meant to include inserts/deletes/updates/selects - all methods of accessing and using that table. And your answer is the same answer I have been giving...it depends.
We can go over different scenarios all day long - but your final statement says it all...you need to look at that system and how it is used to determine how to maintain that system. You cannot just assume that a fill factor of 90 will work across the board - some tables will be perfectly fine with a 100% fill factor, some will need a different fill factor...
And - how often you rebuild (note - I did not say reorganize) that index depends on how fast it fragments to the point where we start to see bad page splits causing performance issues. As for reorganize...there are times when that is the only option available, especially when looking at non-Enterprise Editions that are required to be available 7/24/365 - and you cannot change the table structure.
As for being concerned about the transaction log - that is less of a concern for me. If I have done the analysis and know that these indexes need to be rebuilt - I have identified the optimal fill factor - and determined that rebuilding online over the weekend is the better option for that system - then whatever size is needed for the transaction log is what is needed. There is no way to avoid having the necessary space available in the transaction log...so we make sure we have enough space available.
And seriously - moving to partitioning because the index rebuild takes 200GB of transaction log isn't a good enough reason to partition a table. In fact, changing the structure of a table to attempt to avoid rebuilding the index isn't the correct approach either - using the correct clustered index for that table is much more important.
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs - Jeffrey Williams wrote:
As for reorganize...there are times when that is the only option available, especially when looking at non-Enterprise Editions that are required to be available 7/24/365 - and you cannot change the table structure.
In the cases above, it's usually better to not do any index maintenance at all rather than to use REORGANIZE. People just don't understand that REORGANIZE does two things. Of course, one of them is the highly desirable reorganization of pages to reduce logical fragmentation. The other is what people don't understand and can be (frequently IS) the cause of major page splits when its had its way with your index... it manipulates data to make pages below the Fill Factor to fill up to the Fill Factor. It does NOT create extra space in the critical area above the Fill Factor to help prevent fragmentation. That means that pages that still had "room to grow" are suddenly closer to the line of death (100%) where page splits occur and NOTHING has been done to the existing almost full pages to give them more room to grow.
This was what caused my major blocking issues in Jan 2016 (and the 12 Mondays leading up to that fateful day). Like I said, it's better to not do any index on critical tables that must always be available than it is to REORGANIZE them and that's whether you're using Express, Standard, or Enterprise Editions.
Jeffrey Williams wrote:As for being concerned about the transaction log - that is less of a concern for me. If I have done the analysis and know that these indexes need to be rebuilt - I have identified the optimal fill factor - and determined that rebuilding online over the weekend is the better option for that system - then whatever size is needed for the transaction log is what is needed. There is no way to avoid having the necessary space available in the transaction log...so we make sure we have enough space available.
If you're not running AG or something else that depends on transactions in the Transaction Log, there actually IS a way to greatly reduce the amount of log file space used if you don't mind a trip through the BULK LOGGED Recovery Model. I've proven that you CAN rebuild a 146GB CI in less than 20GB of log file space in the BULK LOGGED Recovery Model. Of course, if you're 24/7/365, you'd be taking a chance with not being able to do a PIT restore to the middle of the TRN backup file(s) while that was active and so shouldn't use that method on such tables.
Still, OFFLINE Rebuilds on non-huge tables are really fast and if you stagger your rebuilds, you might get away with it even on 24/7/365 tables depending, of course, on the table hit rate.
Jeffrey Williams wrote:And seriously - moving to partitioning because the index rebuild takes 200GB of transaction log isn't a good enough reason to partition a table. In fact, changing the structure of a table to attempt to avoid rebuilding the index isn't the correct approach either - using the correct clustered index for that table is much more important.
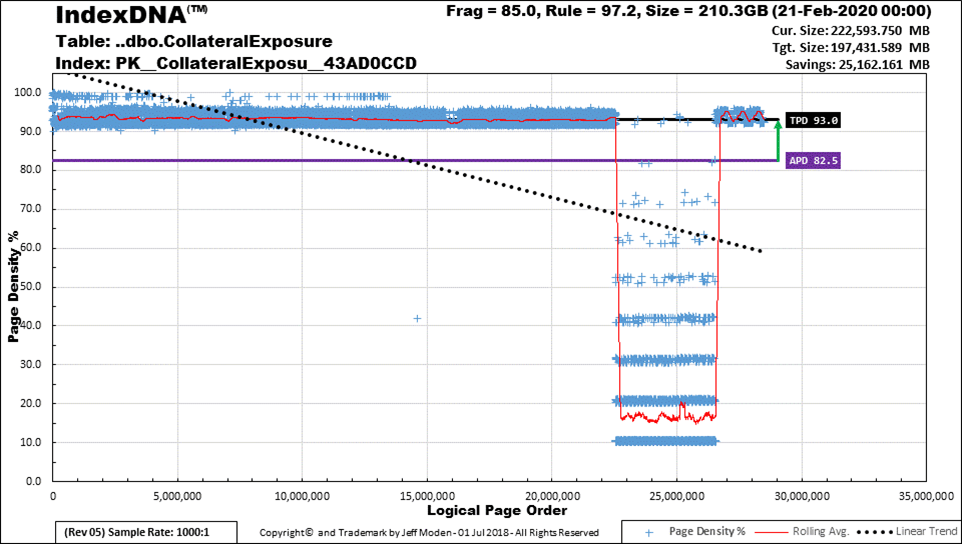
Totally NOT true, especially on really large "ever_increasing" CIs that are inserted to and then the recently added data unavoidably suffers "ExpAnsive" updates or deletes. Consider the following 222GB CI that I've let go without rebuilding for some time (logical page order over time is from left to right)...

Starting at the left and moving to the right, the page density is as high as it can get (only 9 rows per page on this puppy) and is NEVER fragmented again. In other words, that part of the index has become STATIC in nature and contains 175.8GB of this 222GB index (that will become only 197GB after a REBUILD). It's a total waste of time to rebuild that part of the index.
If the index were partitioned correctly, there would be no need to rebuild that STATIC section. In the FULL Recovery Model, this index takes over an hour to rebuild offline and nearly an hour and a half to rebuild online (or to REORGANIZE). Why go through all of that when only 20% of this particular index needs to be rebuilt? (It would take much less % if I rebuilt the fragmented section more often than every couple of months).
I know you don't care about log file space but you should if for no other reason than for how long it would take to do restores. This index is in a 1TB database... I don't want a 197GB (or more) log file to restore if I can get away with a 10 or 20GB log file (currently, 20GB only because I left room for a bit of growth). I also don't want the extra 197GB worth of MDF file caused by a rebuild of this index (actually and so far, I've been doing the WITH DROP EXISTING style of "rebuilds" with swappable file groups to prevent that for this index but that's another story).
Another benefit of partitioning this particular CI to reduce Index Maintenance is that the STATIC portion of this table (~80% as of the time of this analysis) can be relegated to READ ONLY File Groups, which also helps backup time/space (the RO FGs only need to be backed up once) and restores (they don't need to be rolled forward or back).
So, partitioning this table for the sake of much faster and much less resource intensive index maintenance IS actually one of the better reasons to partition tables, not to mention the side benefits for Backup/Restore, especially on this table which occupies 1/5th of the total space of used by the entire database. Why do you think otherwise?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Crap... I'm sorry Jeffrey. I hit "report" instead of "quote" on your post by mistake.
As for the partitioning, please don't put words in my mouth. The original decision to partition the table was based solely on index maintenance requirements. The only other considerations on that table was the fact that it wouldn't hurt anything else. The fact that it's going to help in other areas is purely by chance.
And, nope... that table is a couple of years older than my employment at the company. I wasn't the one who decided to make it on an ever-increasing key but, I have to ask, would you do otherwise considering its use?
And understood on you having a table based on the ideal clustering key being PatientID rather than DocumentID. I'd do the same thing but your table wasn't what we were talking about when you said that partitioning for the sake of index maintenance wasn't a reasonable consideration for doing so. It's perfect for my needs and I agree it's not for yours, in this case. 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
Crap... I'm sorry Jeffrey. I hit "report" instead of "quote" on your post by mistake.
As for the partitioning, please don't put words in my mouth. The original decision to partition the table was based solely on index maintenance requirements. The only other considerations on that table was the fact that it wouldn't hurt anything else. The fact that it's going to help in other areas is purely by chance.
All I am trying to say is that I would not decide to partition a table solely on index maintenance. If the analysis has been done - and the correct clustering key defined - and data usage patterns reviewed and we know that there are no updates/inserts/deletes to those portions of the table, then partitioning is valid for that table. The key is that the analysis has been done first...
And, nope... that table is a couple of years older than my employment at the company. I wasn't the one who decided to make it on an ever-increasing key but, I have to ask, would you do otherwise considering its use?
Considering its use - I would use an ever-increasing key for that table and probably partition just as you have done. Again - the key is that analysis has to be done first...
And understood on you having a table based on the ideal clustering key being PatientID rather than DocumentID. I'd do the same thing but your table wasn't what we were talking about when you said that partitioning for the sake of index maintenance wasn't a reasonable consideration for doing so. It's perfect for my needs and I agree it's not for yours, in this case. 😀
I brought this up to show a counterpoint - again, the analysis has been done for this table. Since we know it cannot be partitioned - and it must be rebuilt, then we need to make sure we have enough space in the transaction log to account for that index maintenance.
It all comes down to...how did you put it
The bottom line is that you "Must Look Eye" because, as is true with everything else in SQL Server, "It Depends" and "Nothing is a 100% panacea".
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
That would be correct.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 15 posts - 1 through 15 (of 15 total)
You must be logged in to reply to this topic. Login to reply