

Introduction
As part of ETL (SSIS/DataStage) processing, data files are loaded into tables. There are times when data files received have issues, causing the ETL process to abort. The ETL (SSIS/DataStage) process on failure would give some idea on cause for failure but would not pinpoint to the exact set of records that are causing a problem. In this article we go over some very useful Unix commands that would help use us debug and resolve issues more efficiently and in a timely manner.
Helpful awk Unix Commands
ETL processes (SSIS/DataStage) are designed to ingest files that are in an expected file layout/schema. These files could be either pipe, comma delimited or fixed width. There are many instances when a production job fails because the data file either has more or less columns than expected. The ETL process fails when schema issues are encountered with data files. The ETL process normally fails the moment it encounters first record that has this issue and does not list all records with issues in the file. If the developer just looks at that record and fixes/removes it and restarts the process, the ETL process would fail again at the very next record that does not comply with expected layout. In order to efficiently resolve all issues with the file knowledge of Unix commands would be very helpful for developers.
In this example we are expecting the Invoice.txt data file with 10 fields/columns.
awk command to check number of fields in a file
Following awk command will give number of fields for each record. The sort command will display only the unique entries outputted from awk command. That way it is easy to know distinct number of fields across all records in the entire file.
awk -F”|” ‘{print NF}’ file_name | sort -u-F represent field delimiter. You would put the delimiter for your file.
NF represent Number of Fields
Example:
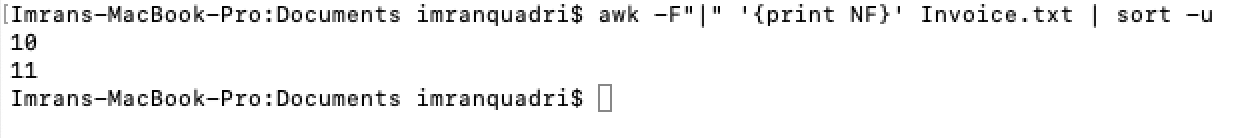
Output of the awk command shows that we have records in file that have either 10 or 11 fields. As the ETL is only expecting records with 10 fields the records with 11 fields would cause ETL process to abort.
awk Command to identify the record’s line number that have fields not equal to 10
awk -F”|” ‘NF!=10{print NR}’ file_nameNR ordinal number of record (record number in file)

awk command to count number of records that have fields not equal to 10
awk -F”|” ‘NF!=10{print NR}’ file_name | wc -l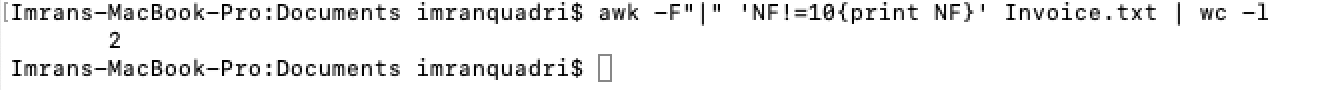
awk command to see records that have incorrect number of fields.
awk -F”|” ‘NF!=10{print $0}’ file_name
There are times when the ETL processing has failed due to a few records havings issue, but in order to meet SLA, it is imperative that the records with correct layout are loaded. The bad records could be requested again or fixed manually and loaded at a later time. In some instances, if it is a known issue, the production support personnel would fix the record and load it once they get appropriate permissions from management to manipulate data to get cycle going.
awk commands to separate bad and records and good records.
First, we will make copy of the source file. Then we use the copied file to create error file with bad records. We will also use copied file to create a file with good records so, that ETL process would find the file with correct format that it is looking for.

Please Note: There are many times when a data file comes along with corresponding control files. In the cases where the source data file is modified and error records are removed, the corresponding control file should also be modified in order to be consumed by the ETL process so the ETL process audit mechanism does not break.
awk command to verify the fixed width file received is correct.
Many times ETL systems receive data files that are fixed width, and when the fixed width file records are not of correct length then the ETL process aborts. It can be challenging to find the records that do not have the expected file layout. The below awk command would print the length of each record and we can verify that the file records are correct.
awk '{print length($0)}' filenameSay in this case the expected record length is supposed to be 32.

We are seeing records whose length is less than 32. In that case we would like to create a file with correct length records and the separate bad records. The bad records can be sent to the source system for correction, and we can restart our failed ETL load process. There are 3 steps involved in the process.
- First, we will make copy of file Invoice_Fixedwidth.txt as Invoice_Fixedwidth_Original.txt
- Create Invoice_Fixedwidth.txt with only correct records of length 32 using file Invoice_Fixedwidth_Original.txt
- Create Invoice_Fixedwidth_error.txt with only correct records of length 32 using file Invoice_Fixedwidth_Original.txt

Carriage Returns
Many times, ETL processes uses files that are generated by a user manually and saved in a versioning tool, like Subversion. These files are basically business control files that are used to control which data is loaded and which data is not loaded into reporting tables. There are many times the ETL processes do not work as expected because of carriage returns (Control+M) that are added to end of each line, as the file was created on a Windows system and then being processed on a Unix system.
Viewing Carriage Returns
The Control M characters are not visible by just using “cat” command. Here we have a file that is generated on a Windows machine:

If you see above, there are no carriage returns (Control+M) characters visible. You could make special characters visible with following commands.
Cat command to view special characters.
The cat command with following options would show the special characters.:
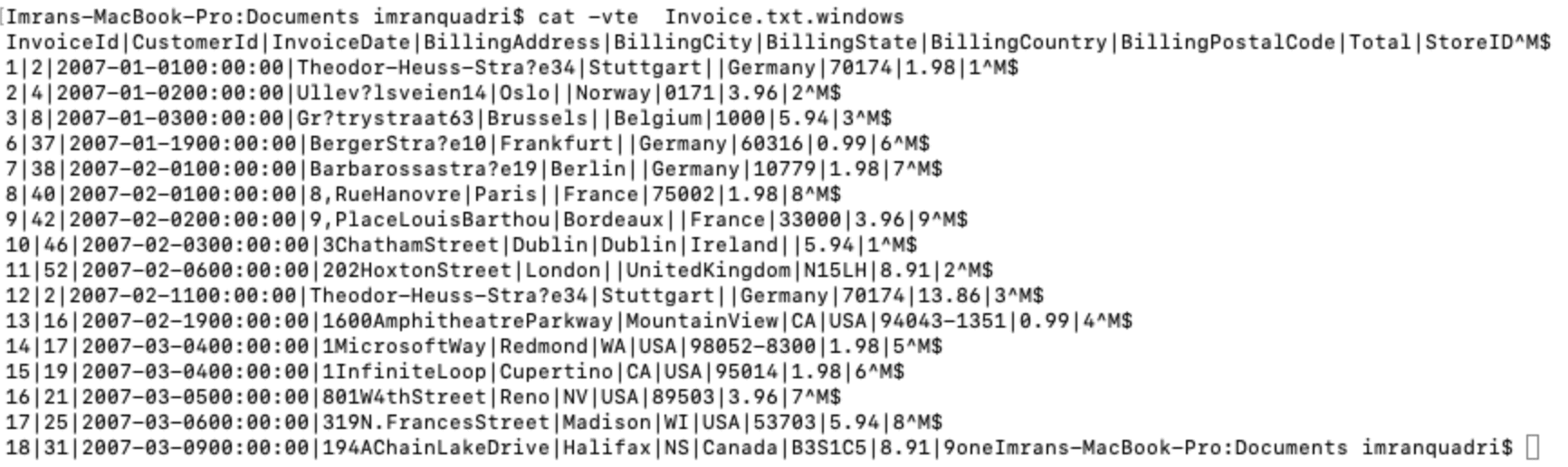
cat -vte file_name
Using vi editor
On a Unix machine, the vi editor would show some of the special characters. On a Linux machine the vi editor would convert the file from DOS to Unix format and would not show return carriage on screen. In Linux at bottom of screen it would display saying converted from DOS format.
vi filename
Using Octal Dump command
Other than control+M characters, there are times the ETL would fail/not work as expected due to special characters in data. These special characters could also be seen using octal dump as follows:
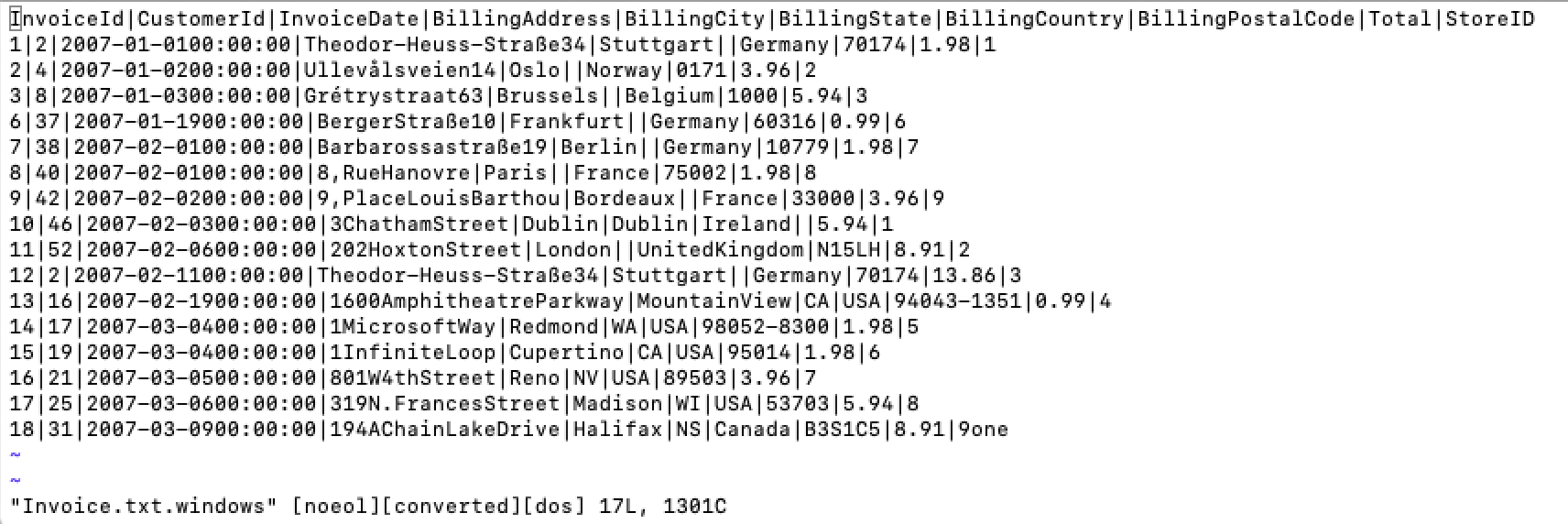
head -2 Invoice.txt.windows| tail -1 | od -bc
or
cat filename| od -bc

If you notice the last 2 characters Carriage and new line character are both displayed. Similarly, you could find other special characters using octal dump.
Removing Carriage Returns
Use the following awk command to remove carriage returns and write corrected records to different file.
awk '{gsub("\r","",$0); print}' Invoice.txt.windows > Invoice.NoCarriageUsingAwk.txt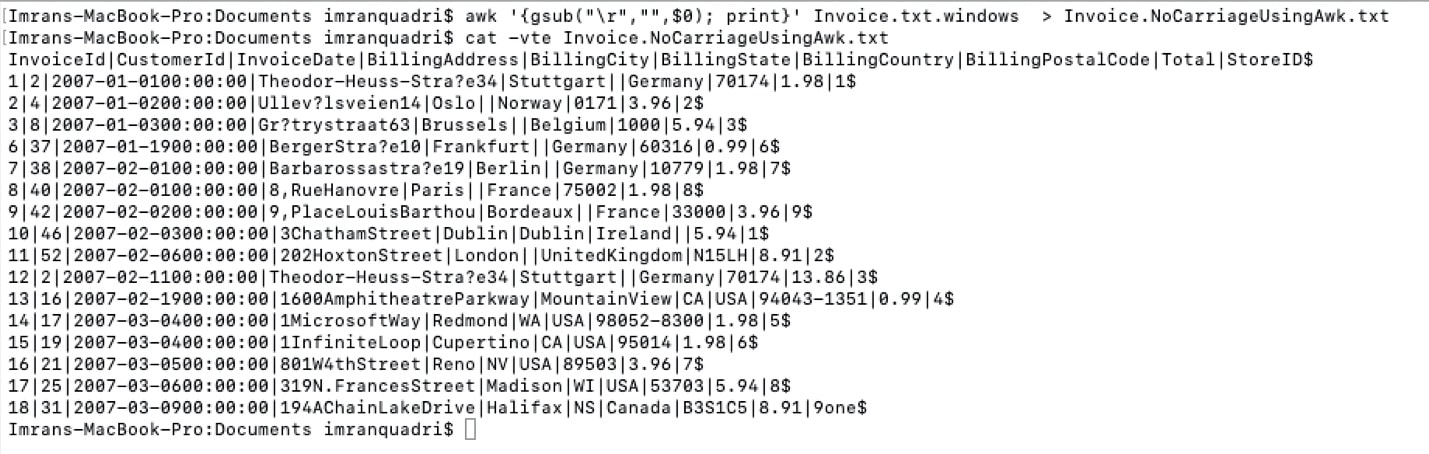
Sed Command to remove carriage returns
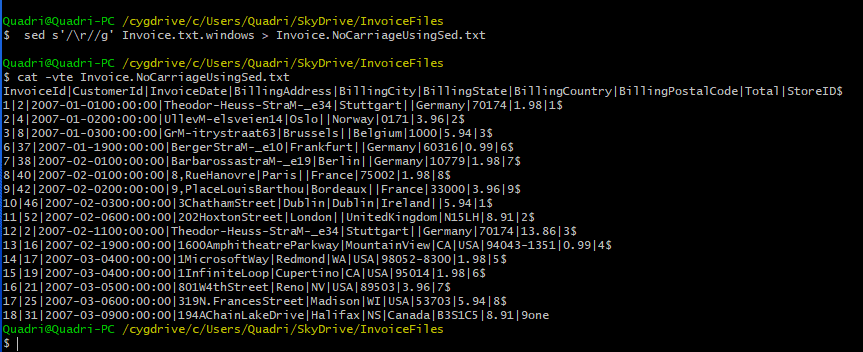
Use the following sed command to remove carriage returns.
sed s'/\r//g' Invoice.txt.windows > Invoice.NoCarriageUsingSed.txt
Translate command to remove carriage returns
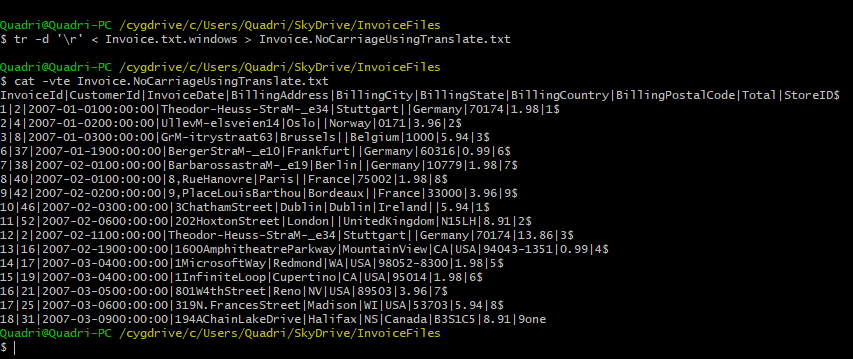
Use the following Translate command to remove carriage returns from the file.
tr -d '\r' < Invoice.txt.windows > Invoice.NoCarriageUsingTranslate.txt
The dos2unix command
Using “dos2unix” command, the carriage returns can be removed.
dos2unix filename
In this case the same file will be modified. There is no need to place the output of the command into a different file.
Nohup command
There are many times when a command or script needs to be kicked off, and it would run for few hours. In cases like this if the command is directly triggered from the command line, then the job will be running for a long time and you can’t use the terminal for any other tasks. Also, if you have to close your computer, then the process would abort. To avoid this, we use “nohup” command and run the process in background by using “&” at the end of the command.
“nohup” stands for “No Hang Up”. Using this command would not result in your process terminate even if you close or exit your terminal. nohup is normally used in conjunction with “&”. “&” would make the process run in the background and would return the command prompt to the user. The standard output for commands invoked using “nohup” are routed to “nohup.out” file and would be located in same directory from where “nohup” command was invoked.
nohup command &
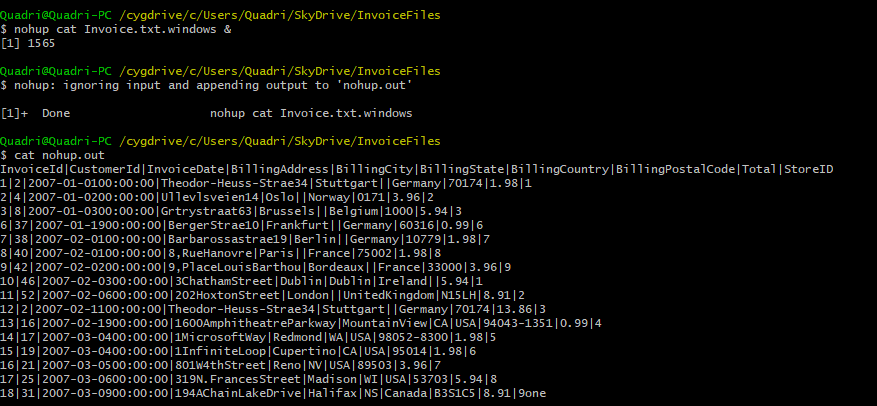
If you see here the “cat” command was invoked with nohup and “&” option. The content of the file was not displayed on standard output (screen) but was directed to nohup.out file.
Checking the your logged in ID
Many times, as part of production support the on-call person has to “su” between multiple user ids to access different folders. A user could lose track of which account with which he/she is currently logged in. In this case “whoami” command would give the user the account with which he is logged in.
whoami

Checking Groups
There are many times that one user has access to execute specific script or access a specific application or directory location whereas the other developer does not. One of the easy ways to identify access mismatch would be to compare the groups you belong to and compare with other developers’ groups. By running following command, you can see all groups that a user id belongs to.
groups userid

The Groups command would give all the groups the userid is part of.
Using the “id” command
You could also use the “id” command to see list of groups the user id belongs to
id

The uid represent the real and effective user id (UID). GID is the group id and then all the groups are listed.
Check all the groups on the system
You can check all the groups on the server by using command:
cat /etc/group

Check the content of gzip file without gunzipping
Normally large files are gzipped once data is loaded using ETL process. But there are times when the files in archive are needed for debugging purposes. In these cases, there could be multiple gzip files that need to be searched to look for a particular record. Unzipping lot of files will take storage and would also take lot of time to gunzip lot of large gzip files. The easiest way is to look at the data without unzipping them and this could be done using following command.
gzip -dc file name
Example:
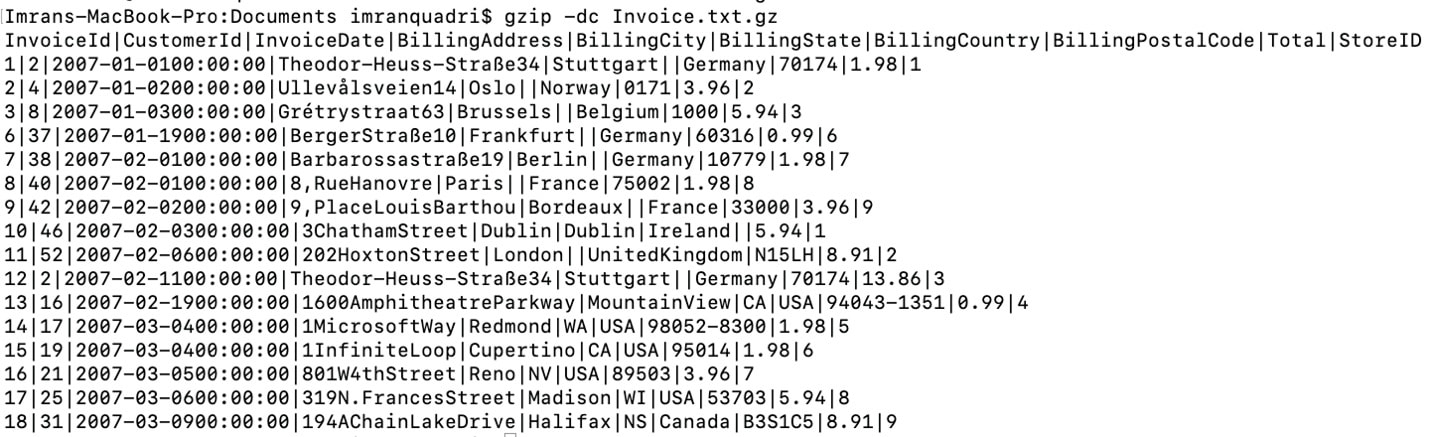
You could also calculate the file count without unzipping the file using following command:
zgrep -Ec “$” filename.gz

Finding space left on Unix mount point and space utilization
During new project implementation, we would need to know how much space is available and how much more space is needed for the new project implementation on a mount point. This could be found on a server using following commands.
The AIX Unix command to list all mount point storage:
df -g
The Linux command to list all mount point storage:
df -h

To check space left for a specific mount point, we use these commands. The AIX Unix command to list all mount points:
df -g mountpoint
The Linux command to list all mount points:
df -h mountpoint

Finding files that take large space.
Find duplicate records in a file
There times were ETL process would fail due to duplicates in the source file. When the ETL process fails it gets difficult to find all the rows that are duplicate with in the file. Use the following command to find duplicates in file
cat Invoice.txt.WithDuplicates | sort | uniq -d

Finding unique records in the file
If you received a file that has duplicates and like to see only the unique records in the file you could use the following command.
cat Invoice.txt.WithDuplicates | sort | uniq -u
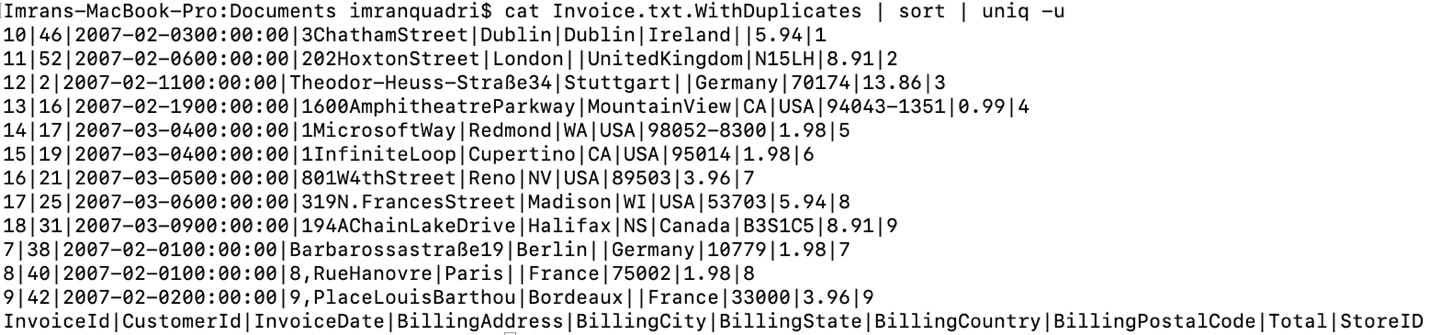
If you like to create a file with only unique records from a file that has duplicates. You could use the following commands.
cat Invoice.txt.WithDuplicates | sort | uniq -u > Invoice.NoDuplicates.txt

Removing a file older than a certain period
In a regular ETL process, after loading the files into tables, the source files are archived for 60 to 90 days and then they are purged to make space for new files and avoid storage space issues. The following command could be used to remove files that are older than 60 days.
find <filepath> -type f -mtime +60 -exec rm {} \;Check to see if the ETL process is still running on the server.
There are many times that we kick of shell script or Unix command in background and but not sure script or the command is still running in background. Here is the command to see all process running on the server.
ps -ef
The command to see any specific process running on a server.
ps -ef | grep Processrelatedkeyword
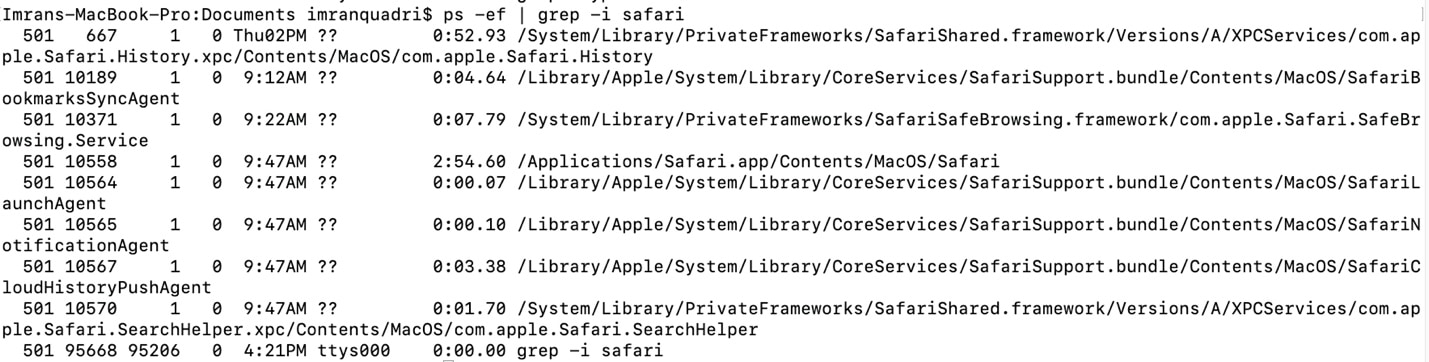
To see processes being executed by a specific user use the following command.
ps -fu username

Check all users on the system
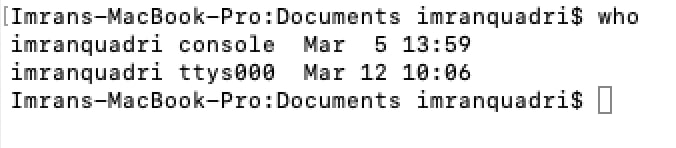
There are times when you like to know who are all the users logged into system/server. You could use the following command.
who
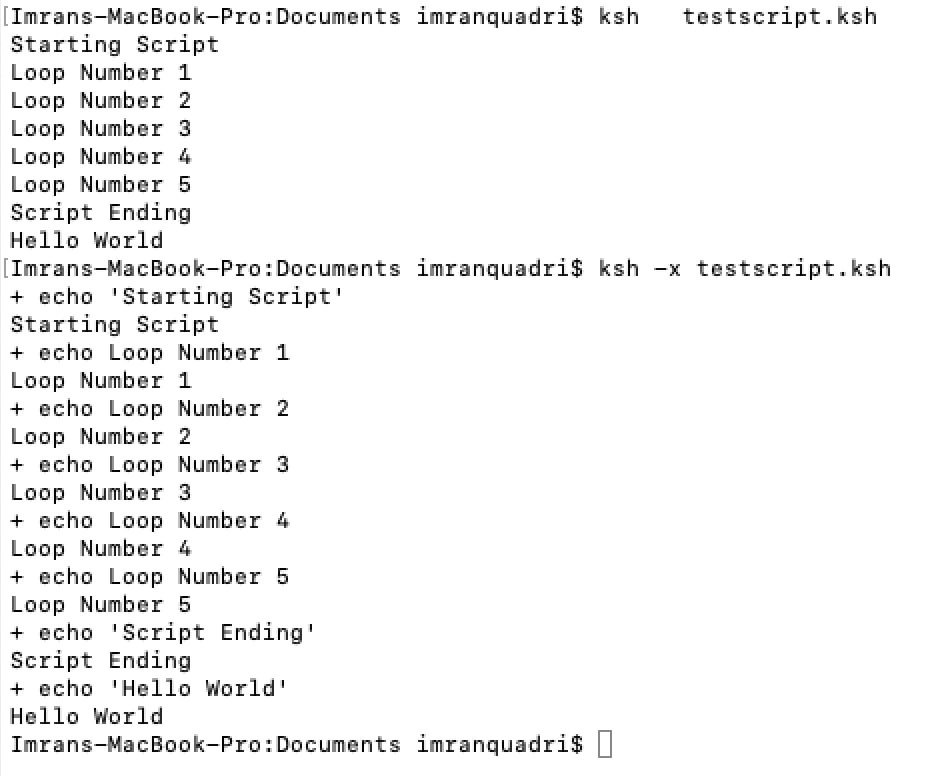
Run a Shell Script in debug mode
There are times when an ETL shell script would fail and it would be required to run the shell script in debug mode in order get more verbose. We can invoke the shell script in debug mode using following command:
ksh -x ShellScriptName – For Korn Shell Scripts
bash -x ShellScriptName – For Bash Shell Scripts.
You can also run the shell script in debug mode by using the following set option.
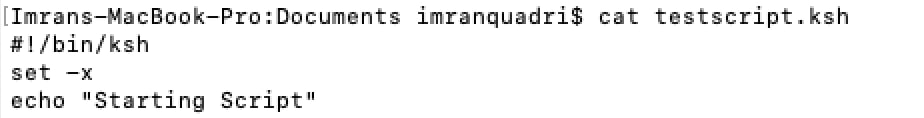
Set Shell script to abort on any command failure.
Set the following option in script for it to abort if any of the commands fail instead of continuing.
set -e

Example:
Without set -e option in script. The script continues with next command even when “mv” command failed.
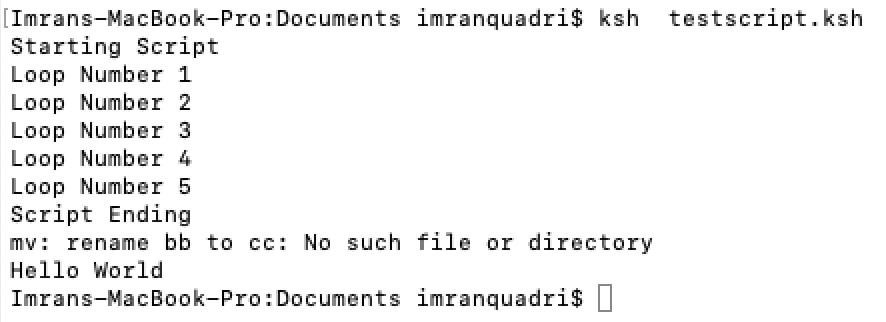
With set -e option in script. The script aborts when any of the command fails in this case, move command failed.

Set vi editor to access previous commands.
Type the following command on command line.
set -o vi
Once you set the vi editor you could access previous commands that you typed on command prompt by typing Esc and then press “-“ hyphen key to access the previous command. Keep pressing “-“ hyphen key to keep accessing older commands.
Conclusion
By using above helpful Unix commands explained in above article, it would help development/production support resources better use a Unix/Linux operating system to debug and resolve any issues in a more efficient and timely manner.
Biographical Notes
Imran Quadri Syed is a Lead System Developer at Prime Therapeutics and has 12 plus years of professional experience in Data Warehousing and Client-Server application packages. Imran’s main area of work involves implementing complex technical solutions to support Business Intelligence Reporting Systems. Imran vast experience varies from legacy technologies like mainframes, Data warehousing technologies (DataStage/Informatica) and latest big data technologies. Imran has completed Bachelor’s in Electronics and Communication Engineering from Jawaharlal Nehru Technology University in 2004. He has completed his Masters in Electrical Engineering from City University of New York in 2006.