Creation of clustered primary key only utilizes 1 CPU core
-
Hi all,
I am once again facing an interesting issue with multi-threading in SQL Server 2016. But first of all, this is the setup: we are using the Enterprise Edition (SP2) on a 24 core single CPU socket server with 5 PCIe NVME SSDs (2 TB each). Filegroups are distributed on all 5 indpendent SSDs.
Here is the use case: a uncompressed heap table with about 20 columns and a size of 250 GByte should be page-compressed with a clustered PK (composite key containing 4 columns (INT and DATE mixed)
ALTER TABLE statement is used to add the primary key.
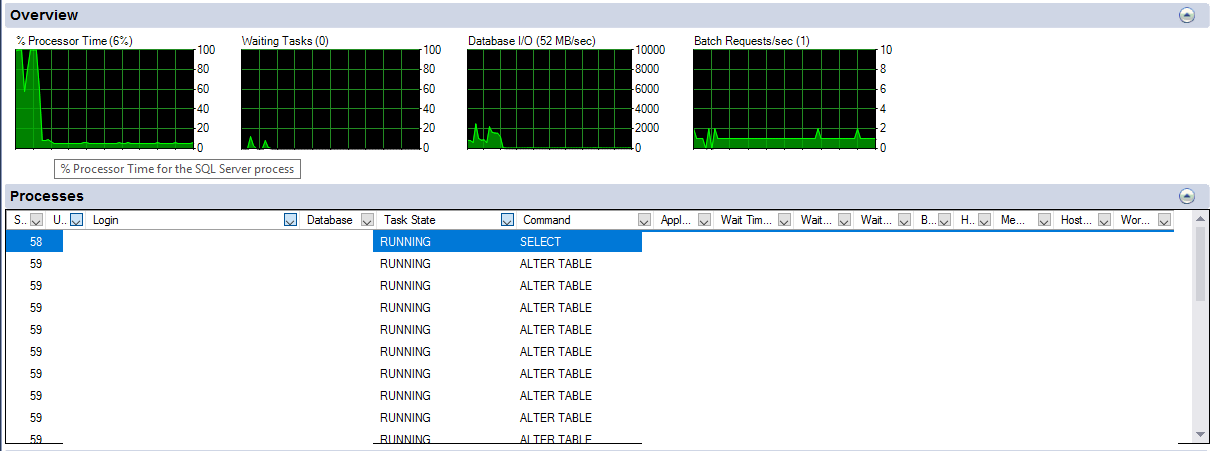
The issue: at first, all cores are utilized and the I/O is very high (between 800 MB/s and 2 GB/s) due to the (I assume) table rewrite. After 2-3 minutes the performance decreases dramatically, i.e. only one CPU core is used (though several threads are executed) and I/O is about 50 MB/s. It takes about an hour to complete the operation.
I have attached two screenshots. The first shows the utilization and I/O (only diagrams) during the high performance phase, the second shows the slow part of the ALTER TABLE statement.

I do not understand why this operation is not performed on all cores. Funny thing is that if I execute the same operation on a smaller machine (4 cores) with only 2% of the data (same SQL Server build), all cores are utilized and this behavior from the big machine cannot be reproduced.
Do you have any idea what is causing this behavior?
Thanks!
-
Edit: I know of the following article:
But the machine is using all cores at the beginning. Does it switch the behaviour dynamically?
-
I think it could.
I'd certainly expect the initial SELECTs from the table to be done in parallel, and thus likely the sorting as well. But the writes to the final result table could be done in serial mode, using only a single core.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Thanks for the quick reply.
So, you think that MAXDOP as option will get the number of cores up for writing the table? Or is the writing always a single core operation?
-
I'm not sure. I don't know if SQL can do parallel writes to a new clustered index.
Given all the possible table options -- data compression, large value types out of row, etc. -- it would be tricky, but it would still theoretically be possible, I would think. I just don't know if SQL can, and would, do it or not.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Oh, ok. I have to check that.
Is there any other option to avoid it? I have chosen to write all my staging data into an uncompressed heap due to minimal logging:
https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008/dd425070(v=sql.100)
Using TABLOCK and ORDER hint, I could try to add data to my table in an compressed clustered index right from the first place.
What's your opinion on that? Does an ordered INSERT INTO SELECT in a compressed clustered index works always in parallel?
-
SQL Server 2016 does allow far more minimally-logged INSERTs to an existing clustered index than any earlier version of SQL.
And, in some instances at least, it does allow simultaneous INSERTs to the index.
Whether or not those INSERTs can be parallelized, as I said, I'm not sure. If, for example, the data was coming from an existing index already sorted in the correct order, and SQL "knew" that, I think it should be possible for SQL do INSERTs to other table from that source index in parallel.
But, when SQL has had to sort random data as the input source, I'd be surprised if SQL was able to do parallel INSERTs of that just-sorted data (note that I'm not saying it can't happen, I'm saying I'd be surprised at it).
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Here's the main article I was basing my comments on about minimal logging in SQL Server 2016:
https://sqlperformance.com/2019/05/sql-performance/minimal-logging-fast-load-context
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Hi Scott,
sorry for keeping you waiting so long. I had to made several tests before. I have read your link about minimal logging on clustered indices.
I have a very simple question about that: how do I control all the variables to make it minimally logged?
For example, it shows the use case that 3 pages are fully logged, but not 1 or 2 pages during insert. It also tells that only the first page ist fully logged. If I have very big table with 3 billion records following the same row size, I would always fully log every record. Or just the first one? This not very clear to me.
Can you help me out with that?
Thanks,
Sven
-
Be sure to specify "WITH (TABLOCK)" on the table being loaded. It's not technically needed at 2016+ level but it doesn't hurt.
The very first page of a table that SQL writes is always fully logged.
If data falls within a page split, it will be fully logged.
Edit: CORRECTION: All new pages that are fully between keys and are not used to fill a page that was split should be minimally logged.
I don't have time right now to give fuller examples of this, will get back when I can.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Hi,
thanks, that would be nice if you could come back to me with details. Links to literature is fine for me, I just need help to get the buzzwords that I can google.
Another thing is that I have noticed that all index inserts (even if minimally logged) are done NOT in parallel. All operations before in the query plan shows parallel executions but once the insert into the table happens, it switches back to a single thread. Are there any additional requirements for a parallel index insert?
Thanks!
-
What's the MAXDOP setting for the server? And what's the Cost Threshold of Parallelism set to?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Cost Threshold of parallelism is set to 5 (I think it's default since stone age) and MAXDOP is number of logical cores of the machine (e.g. 10 physical cores with hyperthreating = 20 logical cores).

Viewing 13 posts - 1 through 13 (of 13 total)
You must be logged in to reply to this topic. Login to reply