

I created this example several years ago that illustrates how foreign key constraints can help performance. It’s a contrived example. Granted. I feel like it illustrates the point.
However, over the years, people have questioned one aspect of it. The optimizer uses the foreign keys to figure out which tables can be eliminated from the query, making for a more efficient plan and making the query run faster. The pushback has always been, “Yeah, Grant, but nobody writes T-SQL where they include extra tables that they don’t need.”
My initial response, after I stop laughing, is to point out any number of ORM tools. But, you know what, let’s assume that’s correct. No one would ever create a giant catch-all view that has all their JOINs in one place so they don’t have to write them for different queries. Stuff like that never happens. Everyone will only, ever, write a query based on the exact tables they need, so this simplification process of the optimizer is a bad example. I agree.
Please go read through the other post for all the details of the set up. I’m just going to focus on one query in this post.
First, in the example, the SELECT only references the Person table and there is no WHERE clause. So we could completely eliminate all the other tables. But, I still want to illustrate how foreign keys help, so let’s assume, for some reason, we need the JOIN (yes, contrived, but it’s going to illustrate the point, again):
SELECT p.LastName + ',' + p.FirstName AS PersonName FROM person.BusinessEntityAddress AS bea JOIN Person.Person AS p ON p.BusinessEntityID = bea.BusinessEntityID; GO SELECT p.LastName + ',' + p.FirstName AS PersonName FROM dbo.MyBusinessEntityAddress AS bea JOIN dbo.MyPerson AS p ON p.BusinessEntityID = bea.BusinessEntityID; GO
The first query goes against a pair of tables with enforced referential constraints. The other query goes against an identical set of tables (indexes are all the same, so is the data and the statistics), but no foreign keys (the final point at the old blog post). If we capture performance metrics on these two queries we see the following:
| Execution Time (Avg ms) | Reads | |
| Foreign Key | 134095.6667 | 155 |
| No Foreign Key | 193937.6667 | 3929 |
On average, the second query is about 60ms slower and has 18 times as many reads. Why? Let’s look at the execution plans:
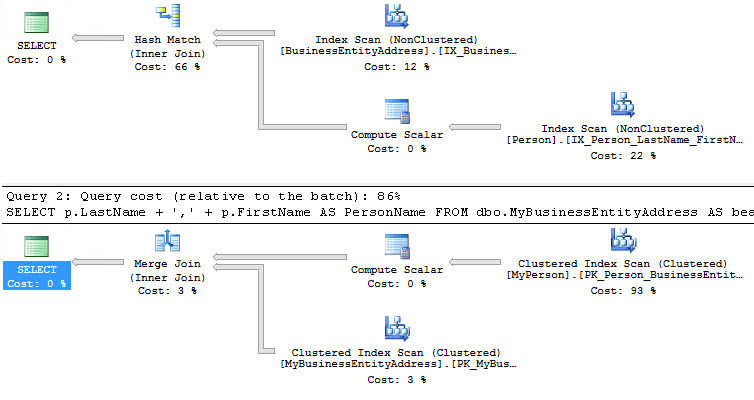
The only difference between these tables is the existence of foreign key constraints, which leads to differences in the estimated number of rows. This occurs because the optimizer knows that the INNER JOIN is going to limit the data coming back to only matching data AND it knows that because there’s an enforced referential constraint, exactly how many rows that will be. Because of this knowledge, it chooses an execution plan that is more efficient.
Foreign keys help performance in SQL Server.
The post Yes, Foreign Keys Help Performance appeared first on Home Of The Scary DBA.
![]()
