

In my Introduction to Hadoop I talked about the basics of Hadoop. In this post, I wanted to cover some of the more common Hadoop technologies and tools and show how they work together, in addition to showing how they work well with Microsoft technologies and tools. So you don’t have to choose between going with Open-source software (OSS) and going with Microsoft. Instead, they can be combined and work together very nicely.
In short, Hadoop is an open-source software framework written in Java for distributed storage and distributed processing of very large data sets on computer clusters built from commodity hardware. The base Apache Hadoop framework is composed of the following modules:
- Hadoop Common – Contains libraries and utilities needed by other Hadoop modules
- Hadoop Distributed File System (HDFS) – A distributed file-system that stores data on commodity machines, providing very high aggregate bandwidth across the cluster
- Hadoop MapReduce – A programming model for large scale data processing. It is designed for batch processing. Although the Hadoop framework is implemented in Java, MapReduce applications can be written in other programming languages (R, Python, C# etc). But Java is the most popular
- Hadoop YARN – YARN is a resource manager introduced in Hadoop 2 that was created by separating the processing engine and resource management capabilities of MapReduce as it was implemented in Hadoop 1 (see Hadoop 1.0 vs Hadoop 2.0). YARN is often called the operating system of Hadoop because it is responsible for managing and monitoring workloads, maintaining a multi-tenant environment, implementing security controls, and managing high availability features of Hadoop
The term “Hadoop” has come to refer not just to the base modules above, but also to the “ecosystem”, or collection of additional software packages that can be installed on top of or alongside Hadoop. There are hundreds of such software packages (see the Apache Projects Directory) that are frequently updated, making it difficult to build a Hadoop solution that uses multiple software packages. Making things much easier are companies that provide “Hadoop in a box”. These are ready-to-use platforms that contain numerous Hadoop software packages pre-installed and where all the packages are tested to ensure they all work together. These include Microsoft’s HDInsight, Hortonworks Data Platform (HDP), Cloudera’s CDH, and MapR’s Distribution.
Microsoft’s HDInsight is simply a managed Hadoop service on the cloud (via Microsoft Azure) built on Apache Hadoop that is available for Windows and Linux. Microsoft Azure is a cloud computing platform and infrastructure, created by Microsoft, for building, deploying and managing applications and services through a global network of Microsoft-managed and Microsoft partner hosted datacenters. Behind the covers HDInsight uses the Hortonworks Data Platform (HDP) Hadoop distribution. Although there are many software packages installed by default on a HDInsight distribution, you can add any additional packages if you wish via a Script Action (see Customize HDInsight clusters using Script Action). With HDInsight you can easily build a Hadoop cluster in the cloud in minutes. The cluster will consist of virtual machines with the data stored separately in Azure Storage Blobs instead of HDFS (see Why use Blob Storage with HDInsight on Azure). The great thing about this is you can shut down the cluster and the data will remain (or you can store the data in the native HDFS file system that is local to the compute nodes but would lose the data if you deleted your cluster). This can result in substantial savings as you can do things like shut down the cluster on weekends if it is not needed. Since HDInsight is 100 percent Apache-based and not a special Microsoft version, this means as Hadoop evolves, Microsoft will embrace the newer versions. Moreover, Microsoft is a major contributor to the Hadoop/Apache project and has provided a great deal of time and effort into improving various Hadoop tools.
Shown below is the software packages and their versions included in the Hortonworks Data Platform:
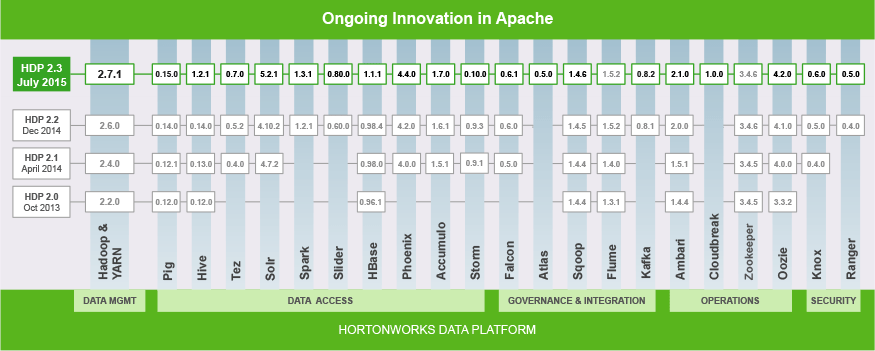
HDInsight is currently using HDP 2.2 and will be upgraded in the next couple of months to HDP 2.3 (see What’s new in the Hadoop cluster versions provided by HDInsight?). Microsoft also has a new partner program for Hadoop independent software vendors (ISVs) to expand their offerings on to HDInsight (see Azure HDInsight launches ISV Partner Program at WPC).
Pictured below is the HDInsight platform that shows how the most popular Hadoop software packages fit together:
- Hive – A data warehouse infrastructure built on top of Hadoop for providing data summarization, query, and analysis. The query language is similar to standard SQL statements and is called Hive Query Language (HQL). It converts queries to MapReduce, Apache Tez and Spark jobs (all three execution engines can run in Hadoop YARN). This makes querying data much easier as you are writing SQL instead of Java code
- Storm – A distributed real-time computation system for processing fast, large streams of data, adding real-time data processing to Apache Hadoop
- HBase – A scalable, distributed NoSQL database that supports structured data storage for large tables
- Tez – Provides API’s to write YARN apps. It is a replacement for MapReduce since it is much faster. It will process data for both batch and interactive use-cases
- Spark – Spark is intended to be a drop in replacement for Hadoop MapReduce providing the main benefit of improved performance. It does not require YARN. It is up to a 100x faster than MapReduce and can also perform real-time analysis of data and supports interactive processing. It can run on HDFS as well as the Cassandra File System (CFS)

Data in a Hadoop solution can be processed either in a batch or in real time.
For batch processing, your choices are MapReduce or Spark. MapReduce was the first and only way for a long time, but now Spark has become the best choice. Spark has a number of benefits over MapReduce such as performance, a unified programming model (can be used for both batch and real-time data processing), richer and simper API, and multiple datastore support.
For real-time processing, the most popular tools to use are Kafka and Storm for event queuing, and Cassandra or HBase for storage. These are all OSS solutions but there are many Microsoft equivalent products should you choose to go that route (with most of the Microsoft products easier to use than the OSS products). The equivalent on the Microsoft stack is Azure Event Hub for Kafka, Azure Stream Analytics for Storm, and Azure blob storage/Azure Data Lake for HBase.
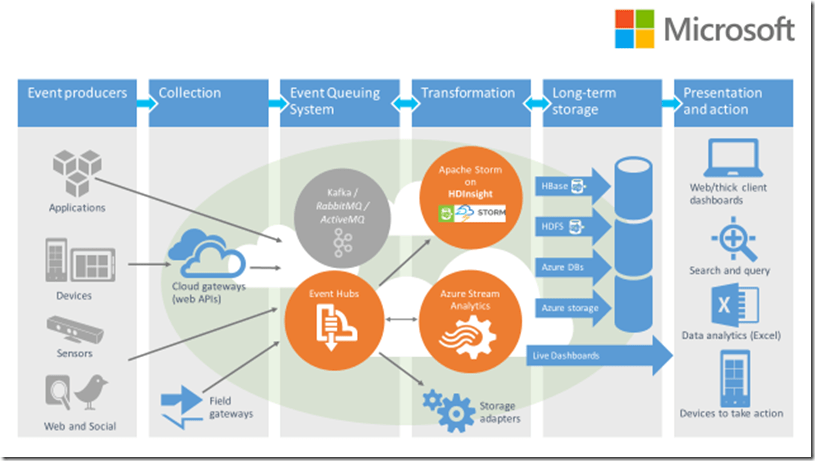
Note that Spark is quickly becoming the tool of choice over Storm. The difference between Hadoop and Storm in the way they work is that Storm is processing an event at a time versus Hadoop or Spark, which is processing a batch at a time. The batch can be large, the batch can be small, or the batch can be really small, which is called a micro-batch. The paradigm in Spark that processes a micro-batch is called Spark streaming.
Storm & Trident (Trident is a high-level abstraction for doing real-time computing on top of Storm) were previously the most popular solution for real-time streaming, but now the most popular is Spark Streaming (an abstraction on Spark to perform stateful stream processing). Spark is also supported on HDInsight (see Announcing Spark for Azure HDInsight public preview).

I hope this has provided a clearer picture to you on which Hadoop technologies are the most popular for building solutions today and how Microsoft supports those technologies via HDInsight. You can learn more about HDInsight and try it for free by clicking here.

![]()
