How to identify if data is skewed in a table
-
Hi,
I'm seeing key lookup which is taking 95% of time for a query. I have verified and made sure that there is no index fragmentation and stats are up to date.
Still the query is taking almost 8 seconds to complete. I want to check if the tables are skewed with data ? How do I make sure that?
-
A key lookup occurs when the cardinality estimator does not have a better index than the primary key to use in the query plan.
The solution to this is to add an index.
Do a search for "Key lookup". There are numerous articles about them, and how to fix them.
Michael L John
If you assassinate a DBA, would you pull a trigger?
To properly post on a forum:
http://www.sqlservercentral.com/articles/61537/ -
How many rows are you returning? How many are there in the table?
Follow the suggestions on this article to get better help on performance problems.
https://www.sqlservercentral.com/articles/how-to-post-performance-problems-1
- Michael L John wrote:
A key lookup occurs when the cardinality estimator does not have a better index than the primary key to use in the query plan.
The solution to this is to add an index.
Do a search for "Key lookup". There are numerous articles about them, and how to fix them.
Or modify an existing index.
You're already looking at the execution plan. It's using one index to identify the rows and then the clustered index to retrieve columns. That's three sets of work; the index seek/scan, the key lookup and the join. The goal is not to try to make the key lookup more efficient. The goal is to eliminate the key lookup and join, reducing to a single set of work. So, look at the Key Lookup operator and see which, and how many, columns are being returned. If it's only a few, modify your index to add those columns as an INCLUDE operation. If it's a substantial part of the table, maybe you need to change the clustered index key to be the key used by the other index.
If you really want to look at the possibility of skew, DBCC_SHOWSTATISTICS will let you look at what the optimizer is using to determine row counts. Compare the compile time values (located in the SELECT operator at the front of the plan) to the values in the histogram. You'll get an idea if the suggested rows are similar to the actual rows. However, that's really not the issue here.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
A key lookup is used when all the columns the query needs are not contained in the index, the database engine will have to go to the clustered index (actual row) of the table to get those additional columns. All you need to do is recreate the index the query is already using to INCLUDE the other columns on the table that are referenced in the query. After that, there will be no need for the query to do a key lookup.
- jdc wrote:
Hi,
I'm seeing key lookup which is taking 95% of time for a query. I have verified and made sure that there is no index fragmentation and stats are up to date.
Still the query is taking almost 8 seconds to complete. I want to check if the tables are skewed with data ? How do I make sure that?
There's a whole lot more that can cause the problem you're having and having skewed data is normally at the bottom of the list if you have a correct index that isn't based on low cardinality data. But, you've not cited how many rows you're returning, haven't posted the query, haven't posted the actual execution plan, etc, etc., so we can't help you make a determination.
To answer your question though, determine the keys of the index in question and simply to a COUNT with a GROUP BY that matches the keys if you want to determine if there's a skew worth worrying about. It'll also give you the Cardinality of the data if you include WITH ROLLUP.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Hi Jeff,
Below is the index that key lookup is using. Can you please let me know how I can use COUNT with a GROUP BY that matches the keys ? Sorry, I'm little confused here.
ALTER TABLE [dbo].[Product] ADD CONSTRAINT [PK_dbo.Product] PRIMARY KEY CLUSTERED
(
[UnitId] ASC,
[ProductId] ASC,
[StartDte] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
-
It would help if you could post the full query in the thread with the DDL for the indexes on the tables in the query.
- jdc wrote:
Hi Jeff,
Below is the index that key lookup is using. Can you please let me know how I can use COUNT with a GROUP BY that matches the keys ? Sorry, I'm little confused here.
ALTER TABLE [dbo].[Product] ADD CONSTRAINT [PK_dbo.Product] PRIMARY KEY CLUSTERED
(
[UnitId] ASC,
[ProductId] ASC,
[StartDte] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
From that, I'm assuming that both UnitID and ProductID are what you're trying to check the skew of data on. With that, you can simply do the following (untested because I don't have access to your data)...
SELECT UnitId, ProductID, Occurences = COUNT(*)
FROM dbo.Product
GROUP BY UnitId, ProductID WITH ROLLUP
;Be advised that this might look a little wonky to you because the GROUP BY WITH ROLLUP is based on two columns and will produce subtotals. The SubTotals and Grand Total will have NULLs in the return.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
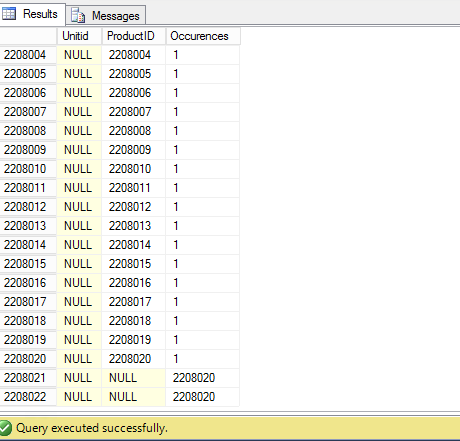
SELECT UnitId, ProductID, Occurences = COUNT(*)
FROM dbo.Product
GROUP BY UnitId, ProductID WITH ROLLUP
having count(*)>1
Results:
UnitId ProductID Occurences
NULL NULL 2208020
NULL NULL 2208020I see 2 million occurrences twice and rest are just one occurrence.
From above result, having 2 million rows, can we say data is skewed?

-
The results with the UnitID and ProductID of NULL are the ROLLUP records, and represent the total count of records in the table, not a skew in the data.
-
Why did you add the "HAVING"? You need to see it all to actually make a determination.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 12 posts - 1 through 12 (of 12 total)
You must be logged in to reply to this topic. Login to reply