

Not long ago, we were notified of a query timing out in an application after three minutes. We were consulted to help find out why. No, it was not SQL Server itself timing out, we explained. SQL Server doesn’t understand what a time out is. Something is just taking too long to run on the application, and we need to figure out what it is.
It didn’t take a lot of time to find the culprit. It was a query that was bringing in gobs of data to SQL Server and choking the life out of it. One of our DBAs got the same query to run in seconds. How? By using temp tables and bringing in the data more appropriately.
SQL Server is a powerful, set-based application, which can process a lot of data. That processing capacity is not unlimited, however, and it doesn’t mean we shouldn’t be good citizens when we use it. When processing huge chunks of data, keep the following in mind:
- Filter early rather than late (columns and rows)! I’ll show you in the demo below how much it can help.
- Remember that a badly constructed query can take down tempdb, or really slow it down.
Most people will either choose temporary tables, derived tables or table variables as homes for their temporary structures. How do you know which to choose? There is no magic (unless you’re Paul White). However, there are some guidelines:
- Table variables are for when the data must survive a transaction rollback, or with SSIS, or to prevent unwanted recompiles, but know that the optimizer will assume that any query to the structure will return 1 row. That can be good, or really, really bad. This, by the way, will be addressed in the SQL Server 2019 release.s
- Derived tables are great when needing to bring data locally.
- Temp tables offer the advantage of indexing, which can really help. When in doubt, try this first
- On rare occasions, I have even seen a stacked CTE outperform every other option.
Please copy and paste the scripts below, which uses AdventureWorks2012. Each should be run separately.
Script 1
Let's say that I need to get rowcounts of all the tables on the server with over 5000 rows. I write a cursor to go out and get the rowcounts, then I filter for the rows over 5000. What are my logical reads?
/* Script 1 - Setup tables and SET changes */DECLARE @DB INT = (SELECT DB_ID() AS AdventureWorks2012);
DBCC FLUSHPROCINDB(@DB);
GO
USE AdventureWorks2012;
GO
SET NOCOUNT ON;
SET STATISTICS TIME, IO ON;
IF OBJECT_ID('tempdb..#RowCountTablePrelim') IS NOT NULL
DROP TABLE #RowCountTablePrelim;
IF OBJECT_ID('tempdb..#RowCountTableFinal') IS NOT NULL
DROP TABLE #RowCountTableFinal;
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
CREATE TABLE #RowCountTablePrelim
(
TableName sysname NULL,
[RowCount] BIGINT NULL
);
CREATE TABLE #RowCountTableFinal
(
TableName sysname NULL,
[RowCount] BIGINT NULL
);
First, let's grab the row counts for all the tables on the server. We only want tables big enough to consider (> 5000 rows). This will spit out separate row counts for each table partition as a separate entry, but we'll deal with that in a minute.
/* Script 2 - Add data */DECLARE @dbName sysname; DECLARE @dbCursor CURSOR; DECLARE @dbSQL NVARCHAR(MAX); SET @dbCursor = CURSOR FAST_FORWARD LOCAL FOR SELECT name FROM sys.databases WHERE source_database_id IS NULL AND database_id > 4 AND is_read_only = 0 AND state_desc = 'ONLINE' ORDER BY name; OPEN @dbCursor; FETCH NEXT FROM @dbCursor INTO @dbName; WHILE (@@FETCH_STATUS = 0) BEGIN SET @dbSQL = N'USE [' + @dbName + N']; INSERT INTO #RowCountTablePrelim SELECT ''[' + @dbName + N']'' + ''.'' + ''['' + SCHEMA_NAME(schema_id) + '']'' + ''.'' + ''['' + t.name + '']'' AS TableName, SUM(ps.row_count) AS [RowCount] FROM sys.tables AS t INNER JOIN sys.dm_db_partition_stats AS ps ON t.object_id = ps.object_id AND ps.index_id < 2 GROUP BY t.schema_id, t.name, ps.row_count;'; PRINT @dbSQL; EXECUTE sys.sp_executesql @dbSQL; FETCH NEXT FROM @dbCursor INTO @dbName; END; CLOSE @dbCursor; DEALLOCATE @dbCursor;
Let's clean up the counts by adding all the partition counts for each table into one final number
/* Script 3 - clean up the data and insert into tables */INSERT INTO #RowCountTableFinal ( TableName, [RowCount] ) SELECT TableName, SUM([RowCount]) FROM #RowCountTablePrelim GROUP BY ROLLUP(TableName); SELECT TableName, [RowCount] FROM #RowCountTablePrelim WHERE [RowCount] > 5000 ORDER BY [RowCount] DESC; DROP TABLE #RowCountTableFinal; DROP TABLE #RowCountTablePrelim;
Plugging the output of the STATS IO into Richie Rump’s Statistics Parser, we get the following:
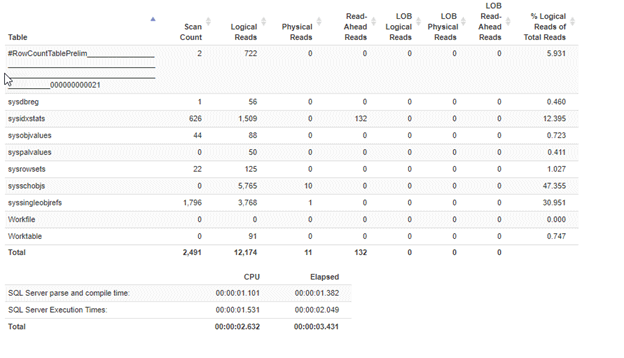
Now, what if we had filtered early? Let's do that.
/* Script 4 - reload the data differently */IF OBJECT_ID('tempdb..#RowCountTablePrelim') IS NOT NULL
DROP TABLE #RowCountTablePrelim;
IF OBJECT_ID('tempdb..#RowCountTableFinal') IS NOT NULL
DROP TABLE #RowCountTableFinal;
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
CREATE TABLE #RowCountTablePrelim
(
TableName sysname NULL,
[RowCount] BIGINT NULL
);
CREATE TABLE #RowCountTableFinal
(
TableName sysname NULL,
[RowCount] BIGINT NULL
);
DECLARE @db2Name sysname;
DECLARE @db2Cursor CURSOR;
DECLARE @db2SQL NVARCHAR(MAX);
SET @db2Cursor = CURSOR FAST_FORWARD LOCAL FOR
SELECT name
FROM sys.databases
WHERE source_database_id IS NULL
AND database_id > 4
AND is_read_only = 0
AND state_desc = 'ONLINE'
ORDER BY name;
OPEN @db2Cursor;
FETCH NEXT FROM @db2Cursor
INTO @db2Name;
WHILE (@@FETCH_STATUS = 0)
BEGIN
SET @db2SQL
= N'USE [' + @db2Name + N'];
INSERT INTO #RowCountTablePrelim
SELECT ''[' + @db2Name
+ N']'' + ''.'' + ''['' + SCHEMA_NAME(schema_id) + '']'' + ''.'' + ''['' + t.name + '']'' AS TableName,
SUM(ps.row_count) AS [RowCount]
FROM sys.tables AS t
INNER JOIN sys.dm_db_partition_stats AS ps
ON t.object_id = ps.object_id
AND ps.index_id < 2
WHERE ps.row_count > 5000
GROUP BY t.schema_id, t.name, ps.row_count;';
PRINT @db2SQL;
EXECUTE sys.sp_executesql @db2SQL;
FETCH NEXT FROM @db2Cursor
INTO @db2Name;
END;
CLOSE @db2Cursor;
DEALLOCATE @db2Cursor;
INSERT INTO #RowCountTableFinal
(
TableName,
[RowCount]
)
SELECT TableName,
SUM([RowCount])
FROM #RowCountTablePrelim
GROUP BY ROLLUP(TableName);
SELECT TableName,
[RowCount]
FROM #RowCountTablePrelim
--WHERE [RowCount] > 5000 _Filtered early instead of late
ORDER BY [RowCount] DESC;
DROP TABLE #RowCountTableFinal;
DROP TABLE #RowCountTablePrelim;
Now look:
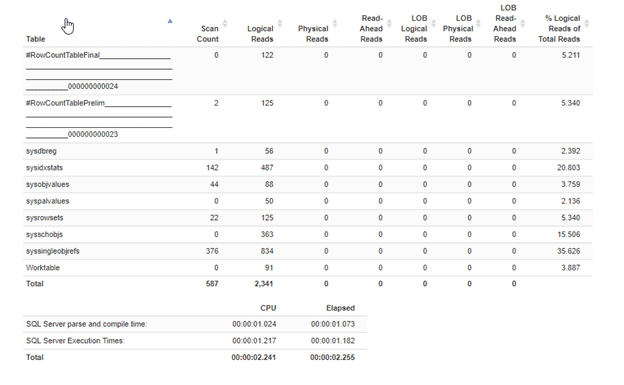
Only 23% of the scans, and 19% of the logical reads! I call that progress.
Why table variables can work against you
Let's try another look where we show why an actual execution plan is the best choice to understand what is happening.
SET STATISTICS TIME, IO OFF; DECLARE @NotAGreatIdea TABLE ( RID INT IDENTITY(1, 1), Col1 UNIQUEIDENTIFIER ); DECLARE @i INT = 1; WHILE @i < 100 BEGIN INSERT INTO @NotAGreatIdea ( Col1 ) VALUES (NEWID()); SET @i = @i + 1; END; SELECT RID, Col1 FROM @NotAGreatIdea WHERE RID < 40;
Here’s what you’ll get in the execution plan:
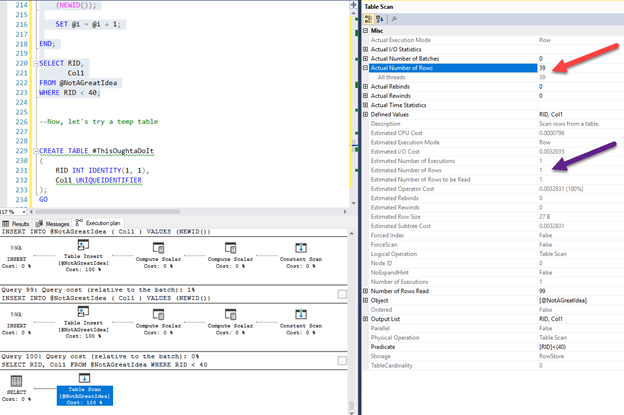
Not a really good guess. Imagine if you had a million rows…
Now, let's try a temp table
CREATE TABLE #ThisOughtaDoIt ( RID INT IDENTITY(1, 1), Col1 UNIQUEIDENTIFIER ); GO DECLARE @i INT = 1 WHILE @i < 100 BEGIN INSERT INTO #ThisOughtaDoIt ( Col1 ) VALUES (NEWID()); SET @i = @i + 1 END CREATE CLUSTERED INDEX cix_rid ON #ThisOughtaDoIt (RID ASC, Col1); GO SELECT RID, Col1 FROM #ThisOughtaDoIt WHERE RID < 40; DROP TABLE #ThisOughtaDoIt;
Much better!
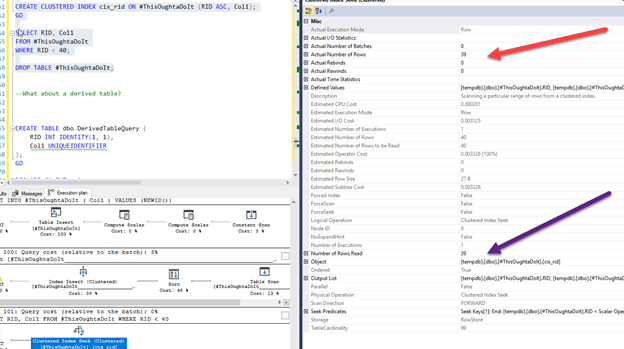
What about a derived table?
CREATE TABLE dbo.DerivedTableQuery ( RID INT IDENTITY(1, 1), Col1 UNIQUEIDENTIFIER ); GO DECLARE @i INT = 1 WHILE @i < 100 BEGIN INSERT INTO dbo.DerivedTableQuery ( Col1 ) VALUES (NEWID()); SET @i = @i + 1 END CREATE CLUSTERED INDEX cix_rid ON dbo.DerivedTableQuery (RID ASC, Col1); GO SELECT RID, Col1 FROM (SELECT RID, Col1 FROM dbo.DerivedTableQuery) AS dtq WHERE RID < 40; GO DROP TABLE dbo.DerivedTableQuery;
And the results…
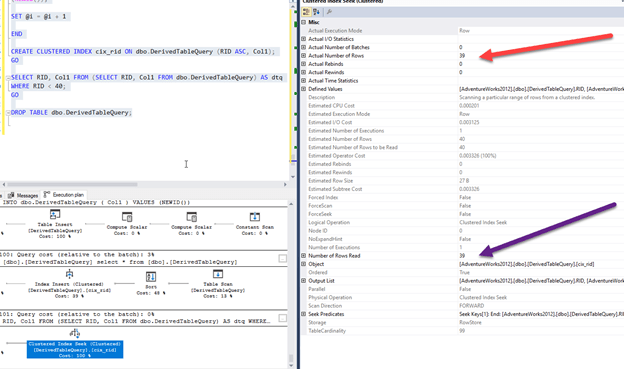
The only way you are really going to know which temporary structure to use is to test it out. There is a time and place for all your options (and at least you have more than one option!). Don’t be afraid to test them all, and find the best one before you deploy.
