

This article will look deeper at the Azure SQL Database - Hyperscale edition, which was moved into General Availability (GA) in May 2019. This followed a bit of a preview time, when I first learned about how it worked in detail. I was impressed with the work being done, some of which will make it to SQL Server in the box, but most of it is designed to push the limits of very large systems.
I have been surprised at how many people were interested, as I know very few people with 100TB range requirements, but apparently there are people in this situation and more of them every day. Even if you don't need 100TB, just running a 5TB system is expensive and difficult. Hyperscale would allow you to remove most of the operational cost of running a large system, if you can work in the Azure SQL Database model.
I'm sure there are a few of you that might have the need for this scale of system, but might not have heard of the technology. It's rather interesting, so let's see how it works.
Hyperscale Capabilities
The big thing with Hyperscale is that the data size is essentially unlimited. Right now they have set this to be 100TB in the documentation and literature, but there is no size limit when you scale up. The minimum size is 10GB, if you want to start playing with this.
Here's one of my Azure SQL Database (ASD) databases, and note that it's got a way to configure vCores at the top and a size at the bottom.
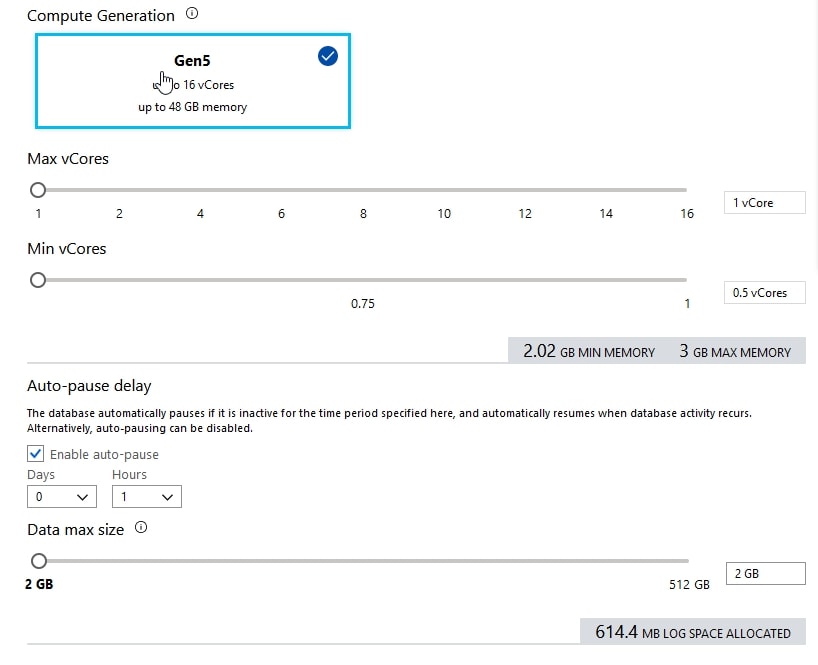
If I want to try out Hyperscale, I can. At the top of this blade, I see the various tiers (General Purpose, Hyperscale, Business Critical) and I can select the middle one. Notice that below, there is no database size. I pick the cores and replicas, but no size. Theoretically, there is no size.
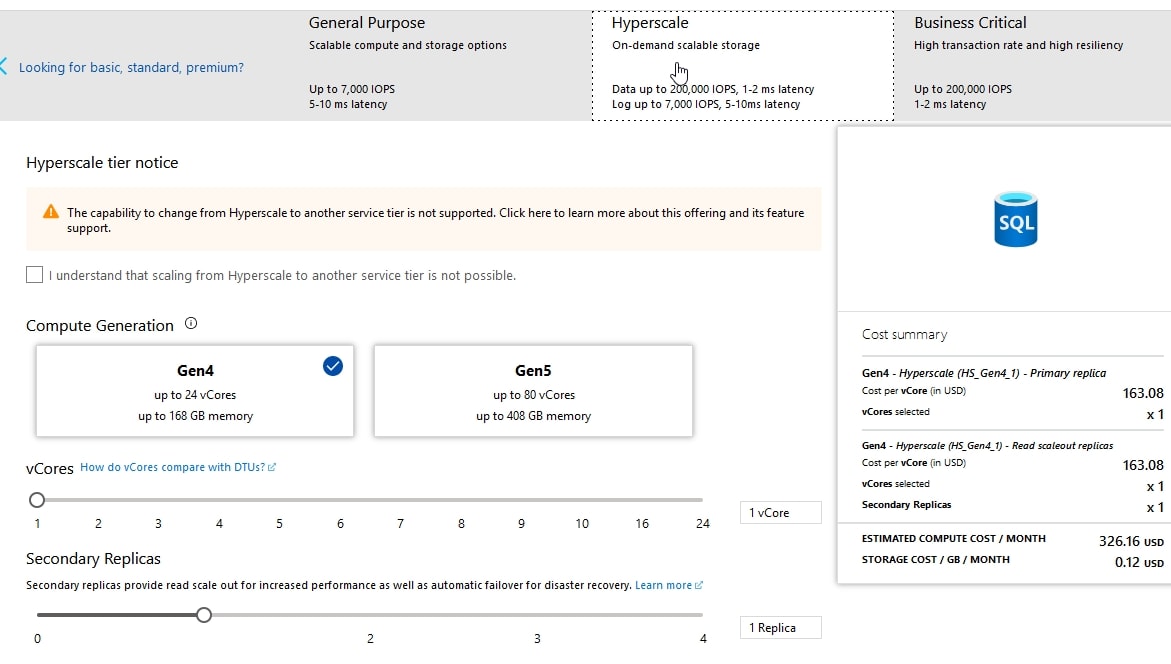
Note the highlight in the center of the screen. If you change to Hyperscale, you can't change back.
This layer also allows scaling out to a number of secondary nodes that are read only. At this point, I can have up to 4 replicas. I assume that will grow over time, but this allows me to move read only workloads if I change the connection string. This is the same way that I do this with Availability Groups. Note there is 1 secondary replica created automatically with Hyperscale.
The other feature I have is that I can choose either Gen4 or Gen5 hardware, which alters the number of cores I have on each instance, along with memory. The scale up of cores and memory is governed by Microsoft and not alterable.
One of the other features of Hyperscale is a high volume log structure that allows lots of data changes, as well as very quick recovery. In a 50TB demo, shown in the video below from Microsoft, the restore of this to a point in time in a separate Hyperscale database takes place in 14 minutes. Not instantaneous, but impressive for 50TB.
In addition to quick restores, backups are made with file snapshots, so the overhead of backup pages being read and passed through the SQL Server engine is eliminated. In addition, the log stream means that log backups aren't an impact on performance either.
The goal here is to really eliminate some of the size of data operation issues.
Architecture
Hyperscale is a version of Azure SQL Database. This means that the database service that we see is exactly the same as we use for Azure SQL database. No new syntax, and no new changes for the way your application works. What is different is the scale that is allowed, essentially unlimited database size.
SQL Server achieves this by tiering the architecture to multiple layers, each of which can have multiple machines. Let's walk through how this works for your Hyperscale database. We'll start with the top layer, where clients connect.
There is one writable and up to 4 read-only replicas that clients can connect to at the top layer. I assume the number of replicas will grow over time, and likely Microsoft is waiting for demand to give us options for 8, 16, or more replicas. Note that you need to set the ApplicationIntent = Read in your connection string to access the replicas.
This is the compute layer, where queries are run. Each of the replicas at this layer is a SQL Server. These are built according to the hardware you specify in your configuration. The local SSD storage scales with the cores and memory you have. Each compute node uses this high speed SSD storage as local cached with the RBPEX (Resilient Buffer Pool Extension) enabled to let SQL Server read data in about 0.5ms. This is the Buffer Pool Extension feature that has been available for a few versions, enhanced to improve performance. The goal is that most of your queries are satisfied from this local cache. The amount of cache on compute nodes is not specified, but Microsoft does say this is proportional to the number of vCores you've provisioned. More cores, more cache.
Microsoft has a diagram in their docs, but here's my simplified version.
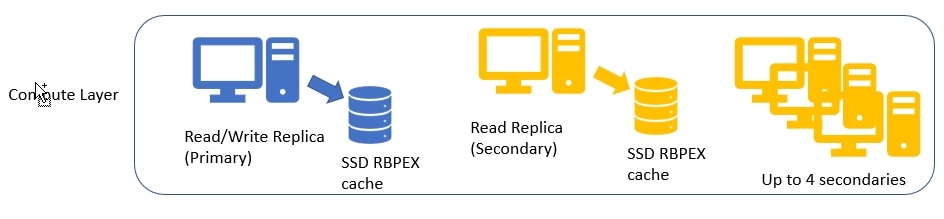
If pages aren't in cache, which is certainly possible in a 100TB database, there is another layer of servers as well. This is the Page Server layer, or really another caching layer. These are SQL Servers, but specialized to just hold cache, somewhat like an expanded buffer pool on another servers. These servers each manage a portion of the data, and serve it to the compute layer as needed. All of the data for each Page Server is in cache backed by SSDs, and the access time for data here is supposed to be in the 2ms range.
As your database grows, more page servers are added to support the load. The docs note that Page Servers can be between 128GB and 1TB, but the video noted in the references says each is 128GB. If 128GB is the number, then a 1TB-ish database needs 8 Page Servers. No data is kept by more than one Page Server, so enough need to be allocated to support the size of the database. A 100TB database would then need 800 Page Servers. Actually, the number can be higher since each Page Server has a secondary server allocated for resiliency. If Page Servers store 1TB, this number goes long, but it is still a lot of servers.
In adding to my diagram, we can see the Page Server layer here. Any node in the compute layer can communicate with any Page Server, and may need to communicate with multiple ones for a query. How this works is a mystery, but I assume this is similar to what will happen with the nodes in Big Data Clusters, allowing SQL Server to scale out to multiple nodes that can help process queries faster. The number of compute nodes is something you decide, while the number of Page Servers is based on your database.
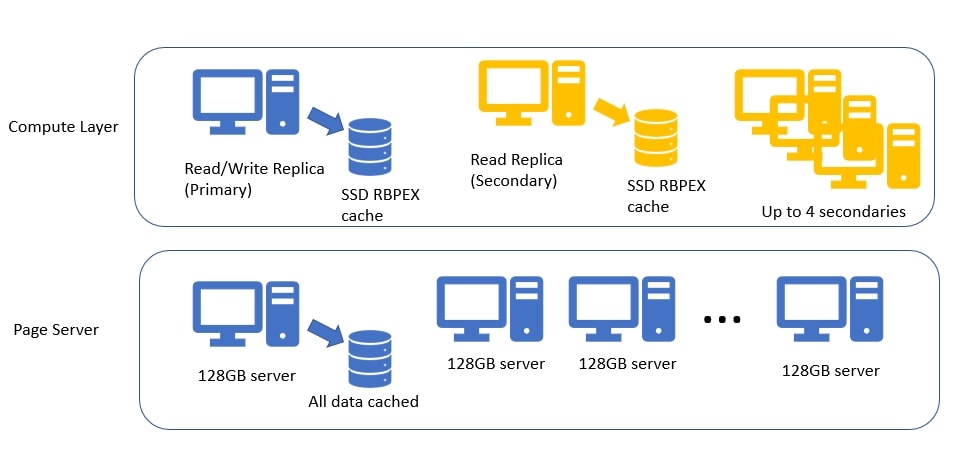
At the bottom layer, there is Azure Standard Storage, the blob storage where the actual data lives in flies. Each Page Server communicates with the data files in Azure Blob storage, updating them as changes are made, or reading from them as a new Page Server needs to fill its cache. The files have periodic snapshots taken to capture changes. These snapshots are used for restore and recovery operations if needed and reduce the need to replay lots of log records. I won't add that to my diagram for now, but will reproduce the doc diagram after talking about the logs.
Log records can be a problem in large systems. The volume of records, and the impact of the write ahead architecture can cause problems. As a result, Microsoft has worked on ways to speed things up. Some of these changes will be in SQL Server 2019, some might be pushed to later versions.
Since there is only one write node, this machine needs to send all changes to the log. In this case, the target is the log Landing Zone, a service that accepts the records and stores them in a durable cache. These records are stored in Azure Premium Storage to ensure high performance of the service. As records are received, a Log Service will forward them to two places: the compute replicas and the Page Servers. This ensures that these nodes are aware of changes being made to data. Once the records are pushed out, they are also moved to long term storage, in Azure Standard Storage. Once written out, the space used by the records in the Landing Zone can be rewritten with new log records, removing the need to truncate the log.
Here's the diagram from the docs.microsoft.com site. As you can see, there are the multiple layers. The colored arrows show how data moves between the layers. One interesting thing is that changes to records aren't written back to the Page Servers from the replicas, as one might expect. Instead, the changes are log records, which are then forwarded to secondary replicas and Page Servers for replay.
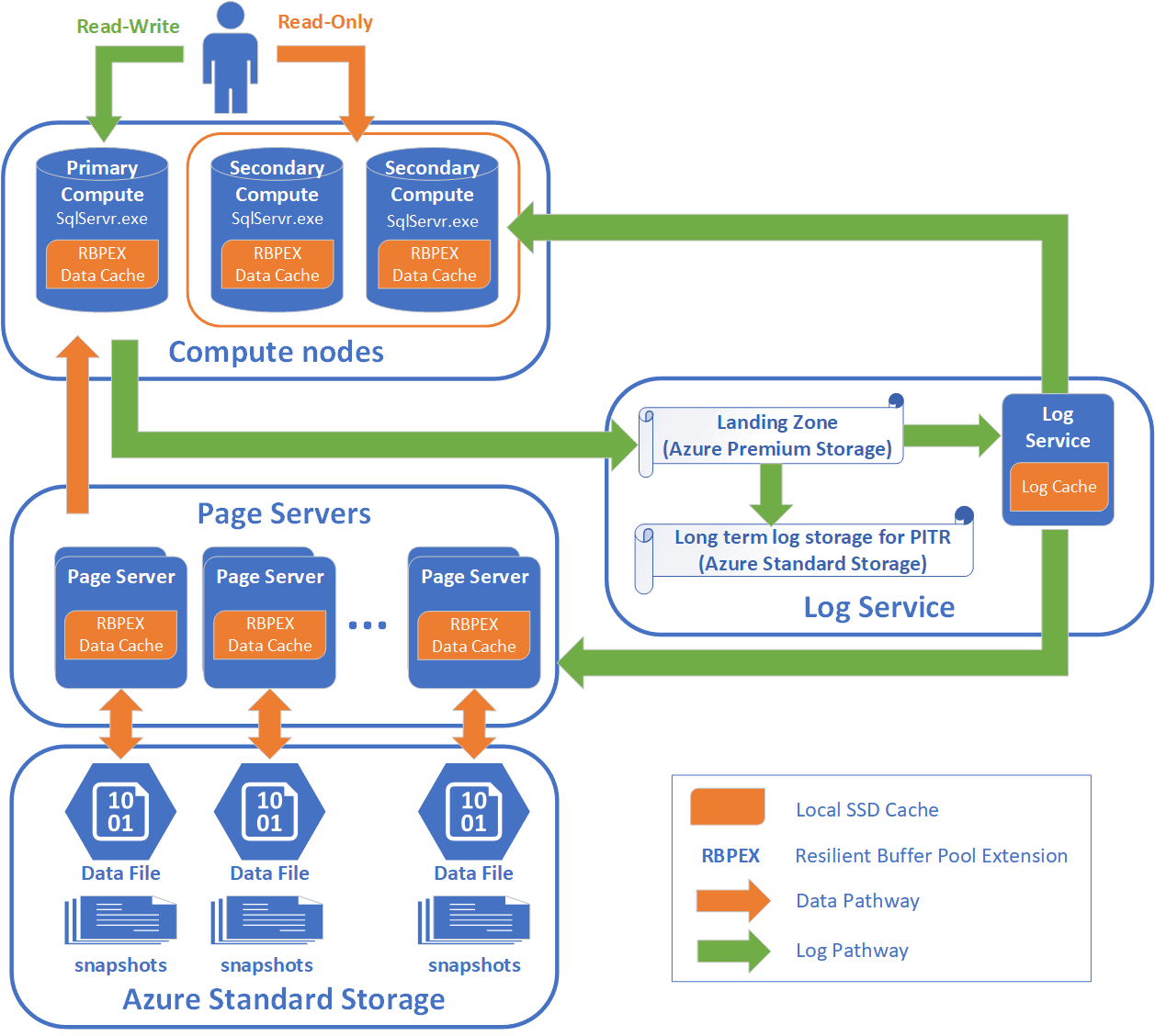
It's an interesting architecture, and one that uses a lot of hardware. You'll pay for this, but for now this is hard to build on premise at scale. At small volumes, you might get better performance from a highly specialized set of hardware in a WSFC/AG set of nodes, but you would still have size of data operational impact.
Backup and Restore
Backups are no longer a thing here. You don't think about them, or manage them at all. Log records are maintained separately, with no need for log backups any longer. Long term storage keeps them for 7 days, and they are replayed on secondaries and Page Servers very quickly. Data backups are file system snapshots made by Azure storage, so you won't run any sort of backup command ever. One thing to note is the file snapshots aren't synchronized, but the capture and storage of log records means this isn't a problem.
The way a restore works is that file snapshots are made at different times. The video in the resources shows this well, but you will have multiple snapshots. However, each file might be at a slightly different time. When a restore is requested, the closest snapshot for each file that is before the restore point is noted for each file. This might be seconds for some files, minutes for others. The oldest snapshot determines where the log records need to be gathered from, as all log records from this point in time need to be replayed.
New storage is allocated and the file snapshots are restored, each independently of the others. Once the file is restored, the log records can be replayed on that file. Since these are multiple files, these occur in parallel, as the Page Servers are responsible for their own file. This speeds up the process, and means all replays should occur within a rough known point of time. This should be a roughly constant amount of time, which means a restore is no longer a size of data operation.
At this point, Page Servers fill their caches. New primary and secondary replicas are allocated during this time as well and they should be ready when the Page Servers are done.
The goal listed in the FAQ is that a restore should take 10 minutes, regardless of size of data. The video shows about 14 minutes, which is still amazing.
Pricing
Brent Ozar has a nice comparison of Hyperscale with AWS Aurora. It's a good look at some differences between the platforms, and this might help you decide if this is useful.
The billing for Hyperscale edition is based on the cores you need (across all replicas) and the storage. Those are billed separately, and grow as you increase the resources you need. This should be less expensive than a Business Critical level server of similar sized server, though adding in replicas increases the size.
A few observations. If I set up a 10GB non-Hyperscale server, I can get 2 vCores on Gen5 for $273.59/month. Let's put a few scenarios in a table:
| Tier | Cores | DB size | Cost/Mo |
| General | 1 (Gen4) | 10GB | $137.69 |
| Hyperscale | 1 (Gen4) | 10GB | $326.16 |
| Business Critical | 1 (Gen4) | 10GB | $275.70 |
If I change this and go with a larger Gen 4, I see this:
| Tier | Cores | DB size | Cost/Mo |
| General | 24 (Gen4) | 1 TB | $3,445.28 |
| Hyperscale (1 replica) | 24 (Gen4) | 1 TB | $7,827.78 |
| Business Critical | 24 (Gen4) | 1 TB | $6,922.55 |
If I go to a mid Gen 5, this time scaling out a bit, we see this:
| Tier | Replicas | Cores | DB size | Cost/Mo |
| General | N/A | 40 (Gen5) | 4 TB | $6142.52 |
| Hyperscale | 2 | 40 (Gen5) | 4 TB | $19,569.46 |
| Business Critical | 1 Read enabled | 40 (Gen5) | 4 TB | $23,407.98 |
This shows that the Hyperscale is cheaper in some cases than Business Critical, especially as you scale. You should experiment with the sliders for your situation, but most importantly, you might want to test some sort of workload against each for a day or two and see how well they scale.
Summary
Hyperscale is a neat architecture that should allow very large databases to operate in the OLTP space in a way that would be hard to duplicate on premises with existing SQL Server technology. The multi-layer architecture should provide good performance, though certainly at a cost, and this will not prevent issues if you have people issuing SELECT * on tables occupying any significant portion of a multi-terabyte database.
If you want to get out of the business of managing very large systems, Hyperscale is an option you ought to investigate as a possible way to handle your load with a minimum of hassles.
References
A few references I used to put together this summary

{kind=link}