How many logical pages?
-
I'm using the StackOverflow 2010 database Posts table for this query. Why would it require 6 logical reads?
I understand why it takes 2 scans, but can someone explain the technical reason it requires 6 logical reads instead of just 2?
The ix_postid index is a unique index on the Id field. The Id field is an Identity type field so it's already sorted ascending.
select min(Id) min_id
, max(id) max_id
from Posts with(index=ix_postid) -
Thanks for posting your issue and hopefully someone will answer soon.
This is an automated bump to increase visibility of your question.
-
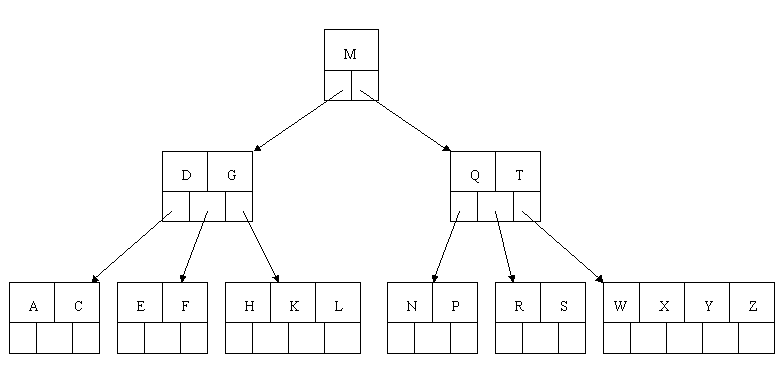
Maybe to navigate through the B-tree?
For example, if the b-tree looked like this you would need to read 6 pages with 2 scans to get the min and max values (A, Z):

-
Take a look at what the execution plan is doing. That query hint may be resulting in a scan instead of a seek. That would explain an increase in the number of reads.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
Here is the exec plan. I just figured that since a page is 8K, a single integer would easily fit on one page and since the plan is a seek from each end of the index it would only end up pulling 2 pages.
- Jackie Lowery wrote:
Here is the exec plan. I just figured that since a page is 8K, a single integer would easily fit on one page and since the plan is a seek from each end of the index it would only end up pulling 2 pages.
But the index is organised as a B-tree, so it needs to search the nodes to get to the min and max values. So depending on the depth of the tree it might need to read more pages to get to the min/max values.
-
It's a good question. My guess with the SO database, that like Jonathan referenced, there are intermediate pages that need to be read to find the leaf pages.
-
The file is coming down as a binary, so I can't look at it. Sorry. However, it's likely that it's what everyone else says. Also, you may see more reads if it's stored on mixed extents, if there's been page splits, etc.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning - Jonathan AC Roberts wrote:
But the index is organised as a B-tree, so it needs to search the nodes to get to the min and max values. So depending on the depth of the tree it might need to read more pages to get to the min/max values.
I think you've hit the nail on the head here. I was looking through the index properties fragmentation info and noticed the depth of the index is 3, so the 3 reads per scan is to get to the first leaf level to get the data.
Viewing 9 posts - 1 through 9 (of 9 total)
You must be logged in to reply to this topic. Login to reply