Very bad performance issue joining 3 tables
-
Hi all,
I have serious performance issue when I execute a SQL statements which involves 3 tables as following:TableA<----TableB---->TableC
In particular, these tables are in a data warehouse and the table in the middle is a dimension table while the others are fact tables. TableA has about 9 millions of record, while TableC about 3 million. The dimension table (TableB) only 74 records.
The syntax of the query is very simple, as you can see, where TableA is called _PG, TableB is equal to _MDT and Table C is called _FM:
SELECT _MDT.codiceMandato as Customer,
SUM(_FM.Totale) AS Revenue,
SUM(_PG.ErogatoTotale) AS Paid
FROM _PG INNER JOIN _MDT
ON _PG.idMandato = _MDT.idMandato
INNER JOIN _FM
ON _FM.idMandato = _MDT.idMandato
GROUP BY _MDT.codiceMandato
Actually, I never has seen the end of this query 🙁
_PG has a non clustered index on idMandato and the same _FM table
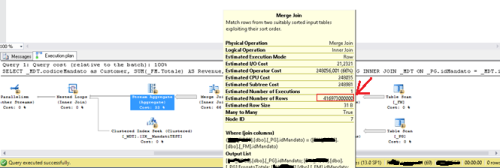
_MDT table has a clustered index on idMandatoand the execution plan is the following

As you can see the bottleneck is due to Stream Aggregate (33% of cost) and Merge Join (66% of cost). In particular, the stream aggregate underlines about 400 billions of estimated rows!!
I don’t know the reasons and I don’t know how to proceed in order to solve this bad issue.
I use SQL Server 2016 SP1 installed of a virtual server with Windows Server 2012 Standard with 4 Cpu core and 32 GB of RAM , 1,5TB on a dedicated volume made up SAS disks with SSD cache.
I hope anybody can help me to understand.Thanks in advance
-
You might have some unintended cross joins. Try to pre-aggregate your values.
SELECT _MDT.codiceMandato as Customer,
SUM(FM.Revenue) AS Revenue,
SUM(PG.Paid) AS Paid
FROM (SELECT _PG.idMandato, SUM(_PG.ErogatoTotale) AS Paid FROM _PG GROUP BY _PG.idMandato) PG
INNER JOIN _MDT ON PG.idMandato = _MDT.idMandato
INNER JOIN (SELECT _FM.idMandato, SUM(_FM.Totale) AS Revenue FROM _FM GROUP BY _FM.idMandato) FM ON FM.idMandato = _MDT.idMandato
GROUP BY _MDT.codiceMandato -
Luis-
I understand what a Cross Join is, and I understand what your solution is doing, but I'm a bit unclear on what you mean by "unintended cross joins". Can you elaborate? Thanks!
"If I had been drinking out of that toilet, I might have been killed." -Ace Ventura - autoexcrement - Monday, June 26, 2017 9:49 AM
Basically, you have TableB which has few unique rows. Then you have TableA and TableC which have repeated values of the TableB key. Since these tables have no relationship between them, they return all possible combinations for each row on TableB, basically the rows on TableA times the rows on TableC. In your example, you mention 9million and 3 million. That would result in approximately 27 quadrillion (27,000,000,000,000) rows.
If you pre-aggregate, this problem dissappears as you have one row on each table for every row on your dimension.
Here's an example using code. Be careful when running it as it drops the tables used.
CREATE TABLE Customers(
CustomerID int,
CustomerName varchar(100)
);
INSERT INTO Customers
VALUES(1, 'Customer A');CREATE TABLE Invoices(
InvoiceID int,
CustomerID int,
InvoiceTotal numeric(18,4)
);
INSERT INTO Invoices
VALUES(1,1,150),(2,1,200);CREATE TABLE Payments(
PaymentID int,
CustomerID int,
PaymentTotal numeric(18,4)
);
INSERT INTO Payments
VALUES(1,1,12),(2,1,25),(3,1,5);--Wrong result caused by an implicit cross join
SELECT c.CustomerName as Customer,
SUM( i.InvoiceTotal) AS Revenue,
SUM( p.PaymentTotal) AS Paid
FROM Invoices i
INNER JOIN Customers c ON i.CustomerID = c.CustomerID
INNER JOIN Payments p ON c.CustomerID = p.CustomerID
GROUP BY c.CustomerName;--Detail of the implicit cross join
SELECT c.CustomerName as Customer,
i.InvoiceID,
i.InvoiceTotal,
p.PaymentID,
p.PaymentTotal
FROM Invoices i
INNER JOIN Customers c ON i.CustomerID = c.CustomerID
INNER JOIN Payments p ON c.CustomerID = p.CustomerID;--Correct results
SELECT c.CustomerName as Customer,
SUM( i.Revenue) AS Revenue,
SUM( p.Paid) AS Paid
FROM (SELECT i.CustomerID, SUM( i.InvoiceTotal) AS Revenue FROM Invoices i GROUP BY i.CustomerID) i
INNER JOIN Customers c ON i.CustomerID = c.CustomerID
INNER JOIN (SELECT p.CustomerID, SUM( p.PaymentTotal) AS Paid FROM Payments p GROUP BY p.CustomerID) p ON c.CustomerID = p.CustomerID
GROUP BY c.CustomerName;GO
DROP TABLE Invoices, Customers, Payments; -
To add to what Luis stated, sometime the pre-aggregation must be done separately in a Temp Table. I've seen many a report that would cripple the server with 50GB log files, cause TempDB to explode, and take 45 minutes to run and they have, many times, been fixed by such a "Divide'n'Conquer" method so that those same reports now take only 1 to 3 seconds and hardly show up for resource usage at all.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Gotcha, thanks Luis and Jeff as usual for sharing!
"If I had been drinking out of that toilet, I might have been killed." -Ace Ventura
Viewing 6 posts - 1 through 6 (of 6 total)
You must be logged in to reply to this topic. Login to reply