

PolyBase is a new technology that integrates Microsoft’s MPP product, SQL Server Parallel Data Warehouse (PDW), with Hadoop. It is designed to enable queries across relational data stored in PDW and in non-relational Hadoop data that is stored in the Hadoop Distributed File System (HDFS), bypassing Hadoop’s MapReduce distributed computing engine that is typically used to read data from HDFS. You can create an external table in PDW that references Hadoop data (kinda like a linked server) and you can then query it with SQL, in essence adding structure to un-structured data. So you can: 1) retrieve data from HDFS with a PDW query that will even allow that data to be joined to native PDW relational tables so that Hadoop and SQL PDW can be queried in tandem, with result sets that integrate data from each source (seamlessly joining structured and semi-structured data); 2) you can import data from HDFS to PDW; and 3) you can export data from PDW to HDFS (for example, as a backup strategy).
The biggest benefit with PolyBase is you don’t need to understand HDFS or MapReduce (typically written in Java) to access Hadoop, and there is no ETL needed. And you can quickly and easily use a tool such as Power Pivot to connect to PDW and pull in data from PDW tables and external Hadoop tables.
Microsoft Technical Fellow David Dewitt is one of the principals behind PolyBase. Some things to note:
- When selecting data in Hadoop, the data is not stored in PDW – it uses a ShuffleMove/BroadcastMove/Round Robin to temporarily bring the data into PDW into temporary tables
- PolyBase only works within PDW for now, but later it might be added to SQL Server (but there are no plans for that). PolyBase relies on the Data Movement Service (DMS) in PDW, and DMS does not exist in SQL Server
- It does not support DML operations
- It may in the future be able to access other storage systems besides Hadoop
- It only works for delimited text files
- It requires Java RunTime environment (Oracle JRE)
- It can connect to Hortonworks Data Platform (HDP) on Windows Server, HDP on Linux, Cloudera (CHD) on Linux
- Soon PDW will have the ability to add a Hadoop scale-unit (compute nodes and storage) right into the PDW rack
In a future version of PolyBase the query optimizer will be able make a cost-based decision, when referencing data in an HDFS, to determine whether it should transform the query into a MapReduce job to be performed on the Hadoop cluster or if it should just process using the SQL server instances on the PDW. Also, the optimizer will have the ability to move the workload of a query involving only PDW data to the Hadoop cluster. This intelligence within the optimizer will allow it to split the workload between the two platforms and thus leverage the true capabilities of the Hadoop cluster.
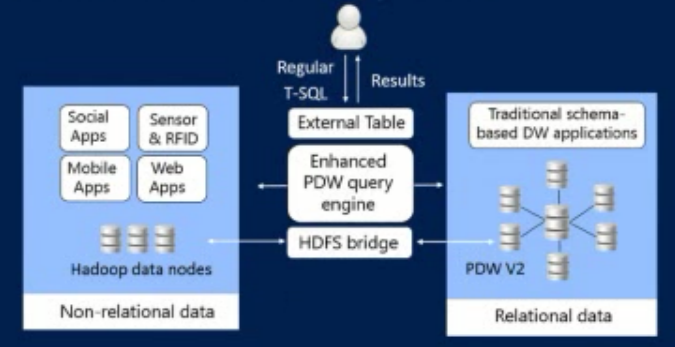
So in summary, the main features of PolyBase are:
- Simplicity: You can query data in Hadoop via regular SQL
- Performance: Parallelized data reading and writing into Hadoop
- Openness: Supports various Hadoop distributions
- Integration: Works with Microsoft BI tools such as Power Pivot, Power View, SSRS, SSAS
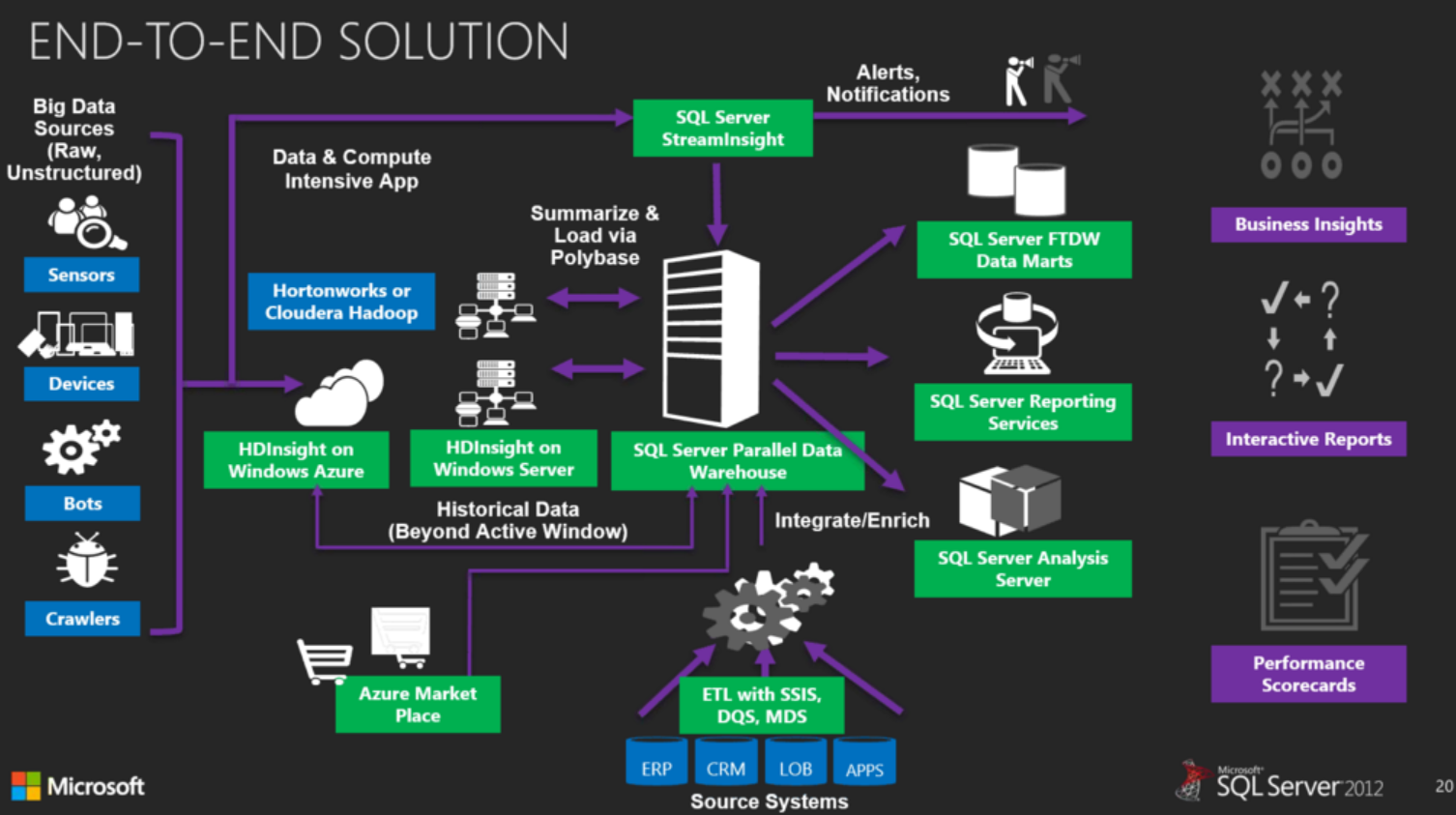
More info:
Seamless insights on structured and unstructured data with SQL Server 2012 Parallel Data Warehouse
Polybase: Hadoop Integration in SQL Server PDW V2
Microsoft’s PolyBase mashes up SQL Server and Hadoop
Insight through Integration: SQL Server 2012 Parallel Data Warehouse
PASS talk: Polybase: What, Why, How

![]()
