Unable to understand the Query Logic
-
Hi
While I was browsing for some interesting puzzles on t-sql I found the below one. but I am unable to understand the logic
in the solution. Could someone here please help out on what exactly happening in this query. I was tried to implement the solution and later I looked for the solution but the logic was bit complicated to understand.
Problem statement:
The challenge is to write a query that works with two input arguments @from and @to holding the start and end dates of a date range, and calculates, for each day, various statistics in respect to the previous day. Specifically, how many visitors visited the site that day, how many new visitors were added compared to the previous day, how many visitors were removed compared to the previous day, and how many remained. For the given sample data, the desired result should look like this:dt numvisits added removed remained
---------- ----------- ----------- ----------- -----------
2011-06-01 3 3 0 0
2011-06-02 2 0 1 2
2011-06-03 2 1 1 1
2011-06-04 0 0 2 0
2011-06-05 0 0 0 0
2011-06-06 0 0 0 0
2011-06-07 2 2 0 0
2011-06-08 3 2 1 1
Below is the Sample tables and test data used.
SET NOCOUNT ON;
USE tempdb;
IF OBJECT_ID('dbo.DailyVisits', 'U') IS NOT NULL
DROP TABLE dbo.DailyVisits;
GO
CREATE TABLE dbo.DailyVisits
(
dt DATE NOT NULL,
visitor VARCHAR(10) NOT NULL,
CONSTRAINT PK_DailyVisits PRIMARY KEY(dt, visitor)
);
INSERT INTO dbo.DailyVisits(dt, visitor) VALUES
('20110601', 'A'),
('20110601', 'B'),
('20110601', 'C'),
--
('20110602', 'A'),
('20110602', 'C'),
--
('20110603', 'A'),
('20110603', 'D'),
--
--
('20110607', 'A'),
('20110607', 'D'),
--
('20110608', 'D'),
('20110608', 'E'),
('20110608', 'F');
SELECT *
FROM dbo.DailyVisits;
Solution:
declare @Start datetime,@End datetime
Select @Start = MIN(dt),@End = MAX(dt) from DailyVisits
;WITH CTE AS
(
SELECT dv.* ,dense_rank() over( order by dt) RN FROM DailyVisits dv
),Cal(dt) as ( select @Start as dt union all select dateadd(DD, 1, dt) as dt from Cal where dt < @End )
SELECT cal.DT
,COUNT(Added) Added
,COUNT(Repeated) Repeated
,COUNT(Removed) removed FROM
Cal Left Join(
SELECT Coalesce(y.dt, x.dt) Dt ,CASE WHEN Y.RN IS NOT NULL AND X.RN IS NULL THEN 1 END Added
,CASE WHEN Y.RN IS NOT NULL AND X.RN IS NOT NULL THEN 1 END Repeated
,CASE WHEN Y.RN IS NULL AND X.RN > 1 AND X.RN < (SELECT MAX(RN) FROM CTE
) THEN 1 END Removed
FROM CTE X FULL JOIN CTE Y ON X.RN = Y.RN - 1 AND X.visitor = Y.visitor) X on cal.dt =x.dt GROUP BY cal.DT -
Could you perhaps format your code so that it's readable please? Having a CASE expression with each part on a separate line with 3 blank lines inbetween makes in completely illegible. Make use of IFCode markup as well, to ensure that formatting/indentation is preserved.
Thom~
Excuse my typos and sometimes awful grammar. My fingers work faster than my brain does.
Larnu.uk -
The query finds the min and max dates, then uses a recursive cte to create a calendar table, adds a rank / grouping to each date, self joins the ranked set on current and previous and then counts new,remaining and removed.
😎 -
Thanks a lot Eirik for the reply.
Thom i have updated the solution part for the clear readability purpose. -
I don't know if the actual solution is even correct. If the comparison is from one day to the next, then it appears that the "Removed" column is not correct in various cases. I'm going to look further at this when I get a chance and see if I can fix it.
Steve (aka sgmunson) 🙂 🙂 🙂
Rent Servers for Income (picks and shovels strategy) -
And for those willing to take a further look, here's a better formatted copy of the query:
USE LOCAL_DB;
GOSET NOCOUNT ON;
IF OBJECT_ID(N'dbo.DailyVisits', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.DailyVisits;
END;GO
CREATE TABLE dbo.DailyVisits (
dt date NOT NULL,
visitor varchar(10) NOT NULL,
CONSTRAINT PK_DailyVisits PRIMARY KEY(dt, visitor)
);INSERT INTO dbo.DailyVisits (dt, visitor)
VALUES ('20110601', 'A'),
('20110601', 'B'),
('20110601', 'C'),
--
('20110602', 'A'),
('20110602', 'C'),
--
('20110603', 'A'),
('20110603', 'D'),
--
--
('20110607', 'A'),
('20110607', 'D'),
--
('20110608', 'D'),
('20110608', 'E'),
('20110608', 'F');SELECT *
FROM dbo.DailyVisits;--Solution:
DECLARE @Start AS datetime, @End AS datetime;
SELECT @Start = MIN(dt), @End = MAX(dt)
FROM dbo.DailyVisits;WITH CTE AS (
SELECT dv.* ,DENSE_RANK() OVER(ORDER BY dt) AS RN
FROM dbo.DailyVisits AS dv
),
Cal(dt) AS (SELECT @Start AS dt
UNION ALL
SELECT DATEADD(DD, 1, dt) AS dt
FROM Cal
WHERE dt < @End
)
SELECT cal.DT
, COUNT(Added) AS Added
, COUNT(Repeated) AS Repeated
, COUNT(Removed) AS removed
FROM Cal
LEFT OUTER JOIN (
SELECT COALESCE(y.dt, x.dt) AS Dt,
CASE WHEN Y.RN IS NOT NULL AND X.RN IS NULL THEN 1 END AS Added,
CASE WHEN Y.RN IS NOT NULL AND X.RN IS NOT NULL THEN 1 END AS Repeated,
CASE WHEN Y.RN IS NULL AND X.RN > 1
AND X.RN < (SELECT MAX(RN) FROM CTE) THEN 1 END AS Removed
FROM CTE AS X
FULL OUTER JOIN CTE AS Y
ON X.RN = Y.RN - 1
AND X.visitor = Y.visitor
) AS X
ON Cal.dt = X.dt
GROUP BY Cal.dt;DROP TABLE dbo.DailyVisits;
Steve (aka sgmunson) 🙂 🙂 🙂
Rent Servers for Income (picks and shovels strategy) -
Okay, now that I've had some time to mess with it, here's a working solution:
USE LOCAL_DB;
GOSET NOCOUNT ON;
IF OBJECT_ID(N'dbo.DailyVisits', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.DailyVisits;
END;GO
CREATE TABLE dbo.DailyVisits (
dt date NOT NULL,
visitor varchar(10) NOT NULL,
CONSTRAINT PK_DailyVisits PRIMARY KEY(dt, visitor)
);
CREATE NONCLUSTERED INDEX IX_DailyVisits_visitor_dt ON dbo.DailyVisits
(
visitor ASC,
dt ASC
);INSERT INTO dbo.DailyVisits (dt, visitor)
VALUES ('20110601', 'A'),
('20110601', 'B'),
('20110601', 'C'),
--
('20110602', 'A'),
('20110602', 'C'),
--
('20110603', 'A'),
('20110603', 'D'),
--
--
('20110607', 'A'),
('20110607', 'D'),
--
('20110608', 'D'),
('20110608', 'E'),
('20110608', 'F');SELECT *
FROM dbo.DailyVisits;--Solution:
DECLARE @Start AS date, @End AS date;
SELECT @Start = MIN(dt), @End = MAX(dt)
FROM dbo.DailyVisits;WITH CALENDAR AS (
SELECT @Start AS dt, CAST(DATEADD(day, -1, @Start) AS date) AS prevday
UNION ALL
SELECT CAST(DATEADD(day, 1, dt) AS date) AS dt, CAST(DATEADD(day, 1, prevday) AS date) AS prevday
FROM CALENDAR
WHERE dt < @End
),
MERGED_DATA AS (SELECT C.dt, C.prevday, DV.visitor
FROM CALENDAR AS C
LEFT OUTER JOIN dbo.DailyVisits AS DV
ON C.dt = DV.dt
)
SELECT MD.dt,
COUNT(DISTINCT MD.visitor) AS NumVisits,
ISNULL(SUM(CASE WHEN MD.visitor IS NOT NULL AND M2.visitor IS NULL THEN 1 ELSE 0 END), 0) AS Added,
--CASE WHEN MD.visitor IS NOT NULL AND M2.visitor IS NULL THEN 1 ELSE 0 END AS Added,
MAX(R.Removed) AS Removed,
--R.Removed,
ISNULL(SUM(CASE WHEN MD.visitor = M2.visitor THEN 1 ELSE 0 END), 0) AS Remained
--CASE WHEN MD.visitor = M2.visitor THEN 1 ELSE 0 END AS Remained
FROM MERGED_DATA AS MD
LEFT OUTER JOIN MERGED_DATA AS M2
ON MD.prevday = M2.dt
AND MD.visitor = M2.visitor
OUTER APPLY (
SELECT COUNT(MD2.visitor) AS Removed
FROM MERGED_DATA AS MD2
WHERE MD2.dt = MD.prevday
AND MD2.visitor NOT IN (
SELECT MD3.visitor
FROM MERGED_DATA AS MD3
WHERE MD3.dt = MD2.dt
AND MD3.visitor <> MD.visitor
)
) AS R
GROUP BY MD.dt
ORDER BY MD.dt;DROP TABLE dbo.DailyVisits;
/* -- RESULTS SHOULD BE
dt #visits #added #removed #remained
2011-06-01 3 3 0 0
2011-06-02 2 0 1 2
2011-06-03 2 1 1 1
2011-06-04 0 0 2 0
2011-06-05 0 0 0 0
2011-06-06 0 0 0 0
2011-06-07 2 2 0 0
2011-06-08 3 2 1 1
*/Steve (aka sgmunson) 🙂 🙂 🙂
Rent Servers for Income (picks and shovels strategy) - sgmunson - Friday, June 23, 2017 10:07 AM
Steve,
Try it with a bit more test data and see where the two Triangular Joins come into play. Here's the test harness. Turn on the Actual Execution Plan and look for the big arrows.
SET NOCOUNT ON;IF OBJECT_ID(N'dbo.DailyVisits', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.DailyVisits;
END;GO
CREATE TABLE dbo.DailyVisits (
dt date NOT NULL,
visitor varchar(10) NOT NULL,
CONSTRAINT PK_DailyVisits PRIMARY KEY(dt, visitor)
);
CREATE NONCLUSTERED INDEX IX_DailyVisits_visitor_dt ON dbo.DailyVisits
(
visitor ASC,
dt ASC
);--===== 10,000 visitors over a 5 year period
INSERT INTO dbo.DailyVisits
(dt, visitor)
SELECT TOP (10000)
dt = DATEADD(dd,ABS(CHECKSUM(NEWID())%DATEDIFF(dd,'2011','2017')),'2011') --2017 is exclusive here
,visitor = RIGHT(NEWID(),7)
FROM sys.all_columns ac1
CROSS JOIN sys.all_columns ac2
;For more information on the devastating effect that Triangular Joins can have even on such small row counts, please see the following article.
http://www.sqlservercentral.com/articles/T-SQL/61539/Also, because you're using an rCTE that counts, you also have to add a MAXRECURSION option if you want to be able to process more than 100 days. I wouldn't use the rCTE for this. Please see the following article on why you should never use one to create a sequence/count.
http://www.sqlservercentral.com/articles/T-SQL/74118/--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Jeff,
Thanks for the test rig. Yes, the triangular join isn't pretty. I chose to take a look at modifying it to have just a single character visitor so that I could at least easily see what the results should be, as the number of different visitors gets so high that repeats are almost non-existent, and in the world of the real web, that's not all that representative of real traffic. Having done that, the solution runs in 1 minute, 9 seconds. Not necessarily a problem in a report, but still a lot more resources than I would prefer to spend. What other technique, however, can deliver the number of removals? It could be that I just haven't put on my thinking cap quite straight enough, but I'm all ears for technique on this.
Steve (aka sgmunson) 🙂 🙂 🙂
Rent Servers for Income (picks and shovels strategy) - sgmunson - Monday, June 26, 2017 12:28 PM
Thanks to the PK on both the DT and Visitor columns in the originally defined problem, it's not actually like real life at all because there's nothing to stop a Customer (or whatever) from visiting more than once a day in real life. 😉
Heh... I do appreciate the code but a report that takes a minute 9 to solve just 10,000 rows would be a real problem for me even if I only had to run it once a month because I know that 10,000 rows will be just the tip of the iceberg in the future.
I'll take a look and see what else can be done. Just as a bit of info, I can tell you that it won't involve an rCTE that increments a date by 1 day. A well written WHILE loop can beat those pretty easily. Again, if you haven't already read it, please see the following article for why you shouldn't use rCTEs that "count by one" even for low row counts.
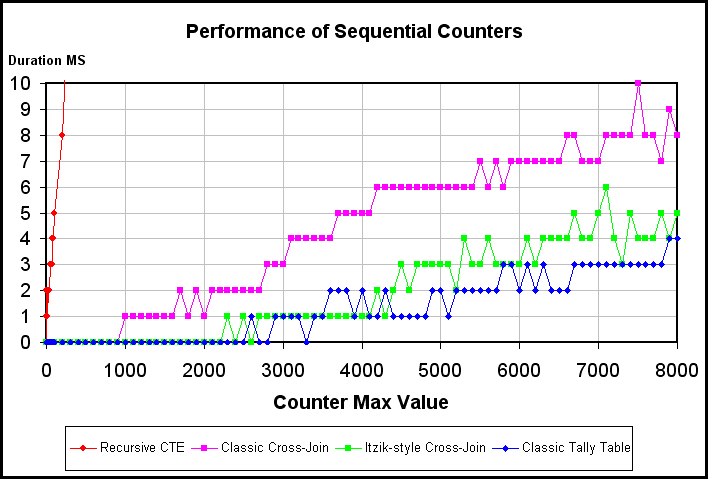
Hidden RBAR: Counting with Recursive CTE'sAs a teaser from that article, here's a performance chart of an rCTE vs. 3 other methods of counting. The rCTE is the Red skyrocket on the left.

--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Ok... first things first. Let's look at the original data provided. I added spaces between the DT groups for clarity.
dt visitor
---------- ----------
2011-06-01 A
2011-06-01 B
2011-06-01 C2011-06-02 A
2011-06-02 C2011-06-03 A
2011-06-03 D2011-06-07 A
2011-06-07 D2011-06-08 D
2011-06-08 E
2011-06-08 FNow, let's look at the results for the code that was provided in the Original Post and put on our Data Scientist hats. See anything wrong?
DT Added Repeated removed
----------------------- ----------- ----------- -----------
2011-06-01 00:00:00.000 3 0 0
2011-06-02 00:00:00.000 0 2 1
2011-06-03 00:00:00.000 1 1 0
2011-06-04 00:00:00.000 0 0 0
2011-06-05 00:00:00.000 0 0 0
2011-06-06 00:00:00.000 0 0 0
2011-06-07 00:00:00.000 0 2 1
2011-06-08 00:00:00.000 2 1 0
Warning: Null value is eliminated by an aggregate or other SET operation.
If you look back at the original data, we have a total of 6 visitors, A thru F. On the final day (2011-06-08), only D, E, and F are present. That means that a total of 3 visitors should have been removed. If you count up the number of Removed in the output above, only 2 have been removed. Combine that error with the rookie mistake of having NULLs be eliminated in the aggregate(s) and I end up not trusting the code at all. Combine that with the fact that there are two Triangular Joins (each the better half of a Cartesian Product), I not only don't trust the code but also know that it won't scale at all. On my box (I5 Laptop running SQL Server 2008 Developer's Edition), it takes more than 40 seconds to process just 10,000 rows. A WHILE loop could beat that. This should take a heartbeat to resolve for 10,000 rows. Not the better part of a minute. That's pretty sickening for performance.Rather than looking at the output of a bad code for our inspiration as to what the problem definition may have actually been, let's annotate the code that builds the test data to see if we can come up with a consistent definition of the problem... like this. And, yes... I modified the code to create a Temp Table instead of a real table in TempDB. I hate cleaning up after myself. I just want to close a window when I'm done and have it all auto-magically clean itself up. 😉
/**********************************************************************************************************************
Problem Definition:
Given the following data, write code to produce the desired result set as explained/outlined in the comments below.
**********************************************************************************************************************/
--===== Suppress the auto-display of rowcounts for appearance sake
SET NOCOUNT ON
;
--===== If the temporary test table exists, drop it to make reruns in SSMS easier.
IF OBJECT_ID('tempdb..#DailyVisits', 'U') IS NOT NULL
DROP TABLE #DailyVisits
;
GO
--===== Create the temporary test table.
CREATE TABLE #DailyVisits
(
dt DATE NOT NULL
,visitor VARCHAR(10) NOT NULL
CONSTRAINT PK_DailyVisits PRIMARY KEY(dt, visitor)
)
;
--===== Populate the temporary test table with simple data so we can check for accuracy.
--======== Expected Results ========
INSERT INTO #DailyVisits(dt, visitor) -- dt Added Repeated Removed
VALUES --========== ===== ======== =======
('20110601', 'A') --First day for A, B, and C, so Added = 3 and Repeats = 0 2011-06-01 3 0 1
,('20110601', 'B') --Is also last day for B so Removed = 1
,('20110601', 'C')
--
,('20110602', 'A') --A and C visited again so Added = 0 and Repeats = 2 2011-06-02 0 2 1
,('20110602', 'C') --Is also last day for C so Removed = 1
--
,('20110603', 'A') --A visited again so Repeats = 1 2011-06-03 1 1 0
,('20110603', 'D') --First day for D so Added = 1 (None removed)--Date Gap here where missing dates need to be zero filled for final result. various 0 0 0
,('20110607', 'A') --Last Day for A so Removed = 1 2011-06-07 0 2 1
,('20110607', 'D') --A and D visited again so Repeated = 2 (None added)
--
,('20110608', 'D') --D visited again so Repeated = 1 2011-06-08 2 1 0
,('20110608', 'E') --First day for E and F so Added = 2
,('20110608', 'F') --This is the last day of data so None shoud be removed.
;
--===== Let's see what we have
SELECT *
FROM #DailyVisits
ORDER BY dt, visitor
;
GOSo, let's summarize the problem...
1. If it's the first appearance of a visitor, it constitutes an ADD.
2. If it's not the first appearance of a visitor, it's constitutes a REPEAT.
3. Whether or not 1 or 2 have occurred, if it's the last time that we see the visitor, it constitutes a REMOVE. The exception to that is the last day of data which, in anticipation of having more data the next day, will have no REMOVEs for the day.That's it. Three simple rules for this problem. Other than the original data, we need 3 simple pieces of data for each Visitor...
1. The first date the visitor appears.
2. The last date the last date the visitor appears.
3. The last date of the data so we can suppress any REMOVEs on the last date.If we look at the output that we surmised previously in the test data build code (without all of the blank lines)...
--======== Expected Results ========
-- dt Added Repeated Removed
--========== ===== ======== =======
2011-06-01 3 0 1
2011-06-02 0 2 1
2011-06-03 1 1 0
various 0 0 0
2011-06-07 0 2 1
2011-06-08 2 1 0
... a couple of things should become apparent.1. We have to use "RBR" or "Row By Row", which should not be mistaken for "RBAR" or "Row By Agonizing Row". What is the "RBR" we need? We need the 3 dates previously mentioned and we need to express them in each row in as simple a form as possible without resorting to Trianglular Joins. In other words, we need to "denormalize" the working set of data without making a big deal about it. If possible, the denormalization will be no worse than 3 GROUP BYs but we're want to do all of that without calling on the physical table more than once, if possible.
2. The other thing is that we need 3 aggregates per DT and they have to be "pivoted" into position as efficiently as possible. That has all the trappings of a good ol' fashioned CROSS TAB.
So, let's get started. Let's solve the first part, the denormalization. I'm not going to explain it all here because this is starting to sound like it might make a pretty good article (if I can find the bloody time to write one). Here's the code. It's "PFM". 😉
--===== Denormalize the 3 critical dates for each row, much like you'd
-- find in a data warehouse.
SELECT dt
,Visitor
,FirstVisitDate = MIN(dt) OVER (PARTITION BY Visitor)
,FinalVisitDate = MAX(dt) OVER (PARTITION BY Visitor)
,FinalDate = MAX(dt) OVER ()
FROM #DailyVisits
ORDER BY dt, visitor
;
If you look at the Actual Execution Plan for that, it'll scare the hell out of you. Not to worry, though... they're all "Lazy Spools" and "Stream Aggregates" meaning that there's no blocking code here and it all happens basically at the same time. More "PFM". 😉 Here's the result set. Again, frightening until you realize that this is no less efficient than a cascading CTE and will execute at "in memory" speeds with just a single scan of the whole table.dt Visitor FirstVisitDate FinalVisitDate FinalDate
---------- ---------- -------------- -------------- ----------
2011-06-01 A 2011-06-01 2011-06-07 2011-06-08
2011-06-01 B 2011-06-01 2011-06-01 2011-06-08
2011-06-01 C 2011-06-01 2011-06-02 2011-06-08
2011-06-02 A 2011-06-01 2011-06-07 2011-06-08
2011-06-02 C 2011-06-01 2011-06-02 2011-06-08
2011-06-03 A 2011-06-01 2011-06-07 2011-06-08
2011-06-03 D 2011-06-03 2011-06-08 2011-06-08
2011-06-07 A 2011-06-01 2011-06-07 2011-06-08
2011-06-07 D 2011-06-03 2011-06-08 2011-06-08
2011-06-08 D 2011-06-03 2011-06-08 2011-06-08
2011-06-08 E 2011-06-08 2011-06-08 2011-06-08
2011-06-08 F 2011-06-08 2011-06-08 2011-06-08
Since each row (RBR) now has all of the data it needs to calculate whether it's an Add, Repeat, or Remove, all we need to do now is aggregate by DT using a CROSS TAB and Bob's your uncle. Like this...--===== Solve the problem as redifined by our analysis.
WITH cteFirstLastDates AS
(--==== Denormalize the 3 critical dates for each row, much like you'd find in a data warehouse.
-- We removed the ORDER BY here because it's not needed here or even wanted here.
SELECT Visitor
,dt
,FirstVisitDate = MIN(dt) OVER (PARTITION BY Visitor)
,FinalVisitDate = MAX(dt) OVER (PARTITION BY Visitor)
,FinalDate = MAX(dt) OVER ()
FROM #DailyVisits
)--==== Aggregate and "pivot" the data by DT using a good ol' CROSS TAB.
-- This is where we now need the ORDER BY.
SELECT DT
,Added = SUM(CASE WHEN dt = FirstVisitDate THEN 1 ELSE 0 END) --Rule 1
,Repeated = SUM(CASE WHEN dt > FirstVisitDate AND dt <= FinalVisitDate THEN 1 ELSE 0 END) --Rule 2
,Removed = SUM(CASE WHEN dt = FinalVisitDate AND dt < FinalDate THEN 1 ELSE 0 END) --Rule 3
FROM cteFirstLastDates
GROUP BY DT
ORDER BY DT
;
Heh... Look Ma! NO Triangular Joins! In fact, no joins at all. Just some nice fast Lazy Spools and Stream Aggregates. Here are the results, so far...DT Added Repeated Removed
---------- ----------- ----------- -----------
2011-06-01 3 0 1
2011-06-02 0 2 1
2011-06-03 1 1 0
2011-06-07 0 2 1
2011-06-08 2 1 0
I say "Results so far" because we haven't filled in the missing dates yet. We obviously need to know the first and last dates so we can generate the missing dates but do we really want to scan the entire table just to get two dates or would it be better to scan our result set so far? Our test table only has 12 rows in it with just a couple of visitors per date. In real life, there could be thousands of visitors per date and the scan of the full table to get the MIN(DT) and MAX(DT) values is an unnecessary use of resources even though our previous scan lodged the whole table in memory. Let's scan the result set, instead.Now, even time you call on a CTE in code, the CTE has to execute all over again, which would mean 1 scan per call of the CTE. This is where Divide'N'Conquer comes into play. We're going to stuff the results, which will be much smaller than the full table, into a temp table and get our dates from that. Here's the modified code to put our results into a temp table. Then and, again, using Divide'n'Conquer, we'll have another query that gets the min and max DT's from the much smaller result set, calculates the number of days in the span of dates, and generates the final output by joining the span dates back to the result set. Like this.
--===== If the temporary results table already exists, drop it to make reruns in SSMS easier.
-- There is no need to include this drop in a production stored procedure but it won't hurt, either.
IF OBJECT_ID('tempdb..#Results','U') IS NOT NULL
DROP TABLE #Results
;
--===== Solve the problem as redifined by our analysis.
WITH cteFirstLastDates AS
(--==== Denormalize the 3 critical dates for each row, much like you'd find in a data warehouse.
-- We removed the ORDER BY here because it's not needed here or even wanted here.
SELECT Visitor
,dt
,FirstVisitDate = MIN(dt) OVER (PARTITION BY Visitor)
,FinalVisitDate = MAX(dt) OVER (PARTITION BY Visitor)
,FinalDate = MAX(dt) OVER ()
FROM #DailyVisits
)--==== Aggregate and "pivot" the data by DT using a good ol' CROSS TAB.
-- This is where we now need the ORDER BY.
SELECT DT
,Added = SUM(CASE WHEN dt = FirstVisitDate THEN 1 ELSE 0 END) --Rule 1
,Repeated = SUM(CASE WHEN dt > FirstVisitDate AND dt <= FinalVisitDate THEN 1 ELSE 0 END) --Rule 2
,Removed = SUM(CASE WHEN dt = FinalVisitDate AND dt < FinalDate THEN 1 ELSE 0 END) --Rule 3
INTO #Results --Added this...
FROM cteFirstLastDates
GROUP BY DT
--ORDER BY DT --Don't need this for now.
;WITH
cteDateSpan AS
(--==== Get the Min DT and the number of days we need to span
SELECT MinDT = DATEADD(dd,-1,MIN(DT))
,Days = DATEDIFF(dd,MIN(DT),MAX(DT))+1
FROM #Results
)
,cteDates AS
(--==== Create all the dates we need
SELECT TheDate = DATEADD(dd,t.N,ds.MinDT)
FROM cteDateSpan ds
CROSS APPLY dbo.fnTally(1,Days) t
)--==== Do a join between the dates we spawned and the previous results for to produce the final results.
SELECT DT = d.TheDate
,Added = ISNULL(r.Added,0)
,Repeated = ISNULL(r.Repeated,0)
,Removed = ISNULL(r.Removed,0)
FROM cteDates d
LEFT JOIN #Results r
ON d.TheDate = r.DT
ORDER BY DT --Ah... finally. An ORDER BY that should be there! ONLY in the final output! ;)
;
Here's the final result from this small bit of data.DT Added Repeated Removed
---------- ----------- ----------- -----------
2011-06-01 3 0 1
2011-06-02 0 2 1
2011-06-03 1 1 0
2011-06-04 0 0 0
2011-06-05 0 0 0
2011-06-06 0 0 0
2011-06-07 0 2 1
2011-06-08 2 1 0Remember... "Set Based" does NOT mean "all in one query" and that "all in one query" does NOT mean "Fast". Even against the previous "worst case with no repeats" 10,000 row table I previously built, it runs in only 197 MILLI seconds instead of more than 40 seconds and, because we've separated the calculations from the display, we've also followed the "Best Practice" of keeping the data layer separate from the presentation layer, which don't actually have to be in separate programs or on separate boxes.
It's also why I say "Whut!?... Oh hell NO! We don' need no stinkin' data warehouse!" 😉
BTW, here's my current dbo.fnTally() function. I'm working on some performance and flexibility improvements on it but this will do for this example.
CREATE FUNCTION [dbo].[fnTally]
/**********************************************************************************************************************
Purpose:
Return a column of BIGINTs from @ZeroOrOne up to and including @MaxN with a max value of 1 Trillion.As a performance note, it takes about 00:02:10 (hh:mm:ss) to generate 1 Billion numbers to a throw-away variable.
Usage:
--===== Syntax example (Returns BIGINT)
SELECT t.N
FROM dbo.fnTally(@ZeroOrOne,@MaxN) t
;Notes:
1. Based on Itzik Ben-Gan's cascading CTE (cCTE) method for creating a "readless" Tally Table source of BIGINTs.
Refer to the following URLs for how it works and introduction for how it replaces certain loops.
http://www.sqlservercentral.com/articles/T-SQL/62867/
http://sqlmag.com/sql-server/virtual-auxiliary-table-numbers
2. To start a sequence at 0, @ZeroOrOne must be 0 or NULL. Any other value that's convertable to the BIT data-type
will cause the sequence to start at 1.
3. If @ZeroOrOne = 1 and @MaxN = 0, no rows will be returned.
5. If @MaxN is negative or NULL, a "TOP" error will be returned.
6. @MaxN must be a positive number from >= the value of @ZeroOrOne up to and including 1 Billion. If a larger
number is used, the function will silently truncate after 1 Billion. If you actually need a sequence with
that many values, you should consider using a different tool. ;-)
7. There will be a substantial reduction in performance if "N" is sorted in descending order. If a descending
sort is required, use code similar to the following. Performance will decrease by about 27% but it's still
very fast especially compared with just doing a simple descending sort on "N", which is about 20 times slower.
If @ZeroOrOne is a 0, in this case, remove the "+1" from the code.DECLARE @MaxN BIGINT;
SELECT @MaxN = 1000;
SELECT DescendingN = @MaxN-N+1
FROM dbo.fnTally(1,@MaxN);8. There is no performance penalty for sorting "N" in ascending order because the output is explicity sorted by
ROW_NUMBER() OVER (ORDER BY (SELECT NULL))Revision History:
Rev 00 - Unknown - Jeff Moden
- Initial creation with error handling for @MaxN.
Rev 01 - 09 Feb 2013 - Jeff Moden
- Modified to start at 0 or 1.
Rev 02 - 16 May 2013 - Jeff Moden
- Removed error handling for @MaxN because of exceptional cases.
Rev 03 - 22 Apr 2015 - Jeff Moden
- Modify to handle 1 Trillion rows for experimental purposes.
**********************************************************************************************************************/
(@ZeroOrOne BIT, @MaxN BIGINT)
RETURNS TABLE WITH SCHEMABINDING AS
RETURN WITH
E1(N) AS (SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1) --10E1 or 10 rows
, E4(N) AS (SELECT 1 FROM E1 a, E1 b, E1 c, E1 d) --10E4 or 10 Thousand rows
,E12(N) AS (SELECT 1 FROM E4 a, E4 b, E4 c) --10E12 or 1 Trillion rows
SELECT N = 0 WHERE ISNULL(@ZeroOrOne,0)= 0 --Conditionally start at 0.
UNION ALL
SELECT TOP(@MaxN) N = ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E12 -- Values from 1 to @MaxN
;--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
P.S. If you think I got the problem definition incorrect, that's certainly a possibility. If you think that, then provide a different problem definition and we'll take a crack at that, as well. 😉
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - I think that this is the origin of the question, along with the some of the solutions
by Itzik Ben-Gan
http://sqlmag.com/blog/tsql-challenge-reoccurring-visits
http://sqlmag.com/blog/solutions-tsql-challenge-reoccurring-visits________________________________________________________________
you can lead a user to data....but you cannot make them think
and remember....every day is a school day -
I've been working on an alternate solution to this one for a while. I have one, but it's somewhat ugly, and while it reads the base table only once, it's not always any faster than a triangular join because it has to sort the result set in a few different ways along the path of execution.
Your solution is nifty, but it is a solution to a different problem than the original, I fear.
The calculation for each day is not against the entire data set, but against the previous day only, e.g., "Added" does not mean it's your first visit ever in the data set, but that you visited today and didn't visit yesterday.
Peso's solution is very clever. Not sure I'm going to beat that one, but I'll definitely keep trying 🙂
- Jeff Moden - Tuesday, June 27, 2017 12:29 AM
I'm quite certain we're not looking at quite the same problem, at least from a REMOVED point of view. My understanding is that Removal is only going to be counted on the day when a given visitor visited the previous day, but not "today", as the statement of the problem in the original post appears to clearly indicate. Each day's statistics is predicated entirely on what took place the day before. Without at least SQL 2012 where LAG could come into play, this particular statistic is rather harder to generate.
As to the "reality" of this kind of data, it's more real than you might imagine. There's a huge interest by e-commerce teams in looking at "distinct visitors", and the fact that someone re-visits the same site in the same day is usually tracked separately, while distinct visitor data is separately analyzed, so having just one occurrence of a particular visitor on a given day would indeed be "normal" for this kind of data analysis. Tracking visitation patterns is extremely useful when tying it to sales data, but "distinct visitor" is an analysis category all its own these days.
I'm going to have to see if I can't perhaps take the mapping of the data to the calendar kind of "outside the box" from the point of view of the solution and see where that gets me. If I can take the CTE that I've used named MERGED_DATA and have that be an actual table, with indexes, and then start the solution from that point forward and see what I can come up with. Just not sure when I'll get time. Thanks as always for taking a good close look at this, and I think I have some ideas on what I might do with it that I can credit to having read your posts on this.
Steve (aka sgmunson) 🙂 🙂 🙂
Rent Servers for Income (picks and shovels strategy)
Viewing 15 posts - 1 through 15 (of 26 total)
You must be logged in to reply to this topic. Login to reply