Hash index on memory-optimized table
-
I have a memory optimized table where I currently have a hash index on two columns. Most of my queries have in the join or where clause the two columns and only the two columns. I have a few queries where there's a third column in the join clause.
Will SQL Server traverse the entire table because of the third column, or will it traverse only on the rows that matched the hash index columns? If it traverses the entire table, will it be more beneficial to create a nonclustered index that includes the three columns or another nonclustered hash index with the three columns?
Thanks in advance for the advice.
-
Have you looked at the execution plan?
Gail Shaw
Microsoft Certified Master: SQL Server, MVP, M.Sc (Comp Sci)
SQL In The Wild: Discussions on DB performance with occasional diversions into recoverabilityWe walk in the dark places no others will enter
We stand on the bridge and no one may pass - GilaMonster - Thursday, September 28, 2017 1:41 AM
That was too obvious and too easy. Of course I didn't. Duh on me 🙂
- N_Muller - Thursday, September 28, 2017 7:33 AM
I ran a test with the execution plan. I created several similar tables with changes to indexes only. There are a few conditions where the execution plan did not present itself as I expected. Here's an example:
create table test2_mo
(
qid int not null,
id1 int not null,
id2 int not null,
id3 int,
index ixh_test2_mo_qid hash ( qid ) with (bucket_count = 4),
index ixh_test2_mo_id12 nonclustered ( qid, id1, id2 )
) with (memory_optimized = on, durability=schema_only)create table test3_mo
(
qid int not null,
id1 int not null,
id2 int not null,
id3 int,
index ixh_test3_mo_qid hash ( qid ) with (bucket_count = 4),
index ixh_test3_mo_id1 hash ( qid, id1 ) with ( bucket_count = 1024),
index ixh_test3_mo_id12 hash ( qid, id1, id2 ) with (bucket_count = 524288)
) with (memory_optimized = on, durability=schema_only)I purposely don't have the bucket sizes optimal. The data is identical in the two tables. I added about 4 million records to each table with the following characteristics:
* 4 distinct qid
* ~400,000 distinct [qid, id1] pairs
* ~4 million distinct [qid, id1, id2]My first two queries were:
select * from test2_mo with (snapshot) where qid = 3
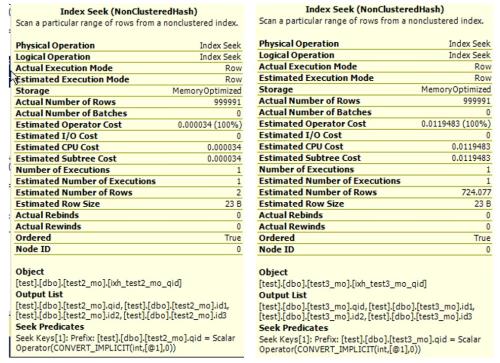
select * from test3_mo with (snapshot) where qid = 3While both queries executed in the same amount of clock-time and had the same execution plan (index seek on the nonclustered hash index on [qid], SQL Server estimated the query cost on test2_mo to be 0% of batch and on test3_mo to be 100% of batch. The details of the index seek is below. I don't understand how the two could be so different.

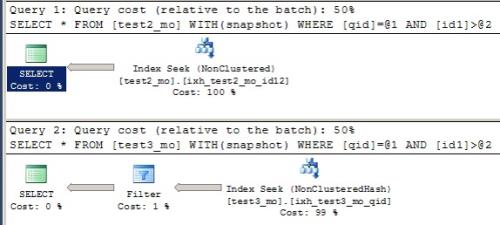
In a second test I added an equality filter to the where clause on id1. Query on test2_mo took 96% of the batch and on test3_mo took 4% of the batch. That was expected based on the selection of indexes. For test2_mo, SQL Server chose the non-clustered non-hashed index ixh_test2_mo_id12 on [qid, id1 and id2], and for test3_mo, SQL Server chose the hash index ixh_test3_mo_id1 on [qid, id1].
In a third test, I changed the equality filter on id1 to an inequality filter:
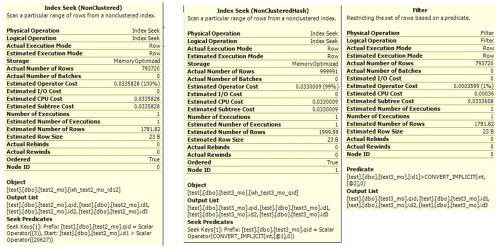
select * from test2_mo with (snapshot) where qid = 3 and id1 > 20627
select * from test3_mo with (snapshot) where qid = 3 and id1 > 20627Each query cost was 50% of the batch.
I don't quite understand the execution plans. Any help is appreciated. -
I'm not sure either, there are some funnies with in-memory and execution plans.
Let me consult an expert.Gail Shaw
Microsoft Certified Master: SQL Server, MVP, M.Sc (Comp Sci)
SQL In The Wild: Discussions on DB performance with occasional diversions into recoverabilityWe walk in the dark places no others will enter
We stand on the bridge and no one may pass - N_Muller - Wednesday, September 27, 2017 3:27 PM
Ths internal storage structure for memory-optimized tables and indexes is very different from that for disk-based tables. So different, in fact, that it's hard to determine whether clustered or nonclustered would have been the better term (I'd say that it's bets to use neither, but nobody asked me)
Memory-optimized data is stored in memory. Every row takes up an amount of memory equal to its data, plus some overhead. Part of that overhead is room reserved for pointers to other rows. Each additional index on the table adds one pointer to each row. For each index, the corresponding pointer in each row points to the "next" row in that index. In the case of a hash index, the result of a hash function determines which bucket (i.e. which "subset" of the data) is the start of the pointer chain, and each "subset" has its own pointer chain. (A non-hash memory-optimized nonclustered index uses a slightly more complex way to determine which row points to which other row).
When you read a memory-optimized index, you simply find the start of the chain, then follow the pointers to read rows until the end of the chain. (And keep checking the key values to make sure you skip false positives that are in the same bucket due to hash collissions). Because each pointer points to a full row, you immediately have all the data. You will never see a lookup on a memory-optimized table. (For that reason, I would personally have preferred clustered over nonclustered as the official designation of memory-optimized indexes - but then there would have been multiple clustered indexes on the same table and that would certainly have confused a lot of people).
Hugo Kornelis, SQL Server/Data Platform MVP (2006-2016)
Visit my SQL Server blog: https://sqlserverfast.com/blog/
SQL Server Execution Plan Reference: https://sqlserverfast.com/epr/ - N_Muller - Thursday, September 28, 2017 9:19 AM
The answer to this is actually quite simple. You must have used different methods to build and populate the two tables, and this has resulted in different statistics on the two,.And that, in turn, caused the query optimizer (or rather, the cardinality estimator, a subsystem of the optimizer) to estimate the Index Seek of the first query to return 2 rows, versus 724.077 for the second. Thhis has a direct impact on the estimated cost of the operator: 0.000034 for the first one and 0.0119483 for the second. I don't expect much else in the execution plans, so the costs for the plans as a whole should be about the same. The percentages you see are simply a mathematical simplification of the estimated costs: (0.000034 / (0.000034 + 0.0119483)) = 0.0028; and (0.0119483 / (0.000034 + 0.0119483)) = 0.9972.
If you rebuild the statistics on both tables, with the fullscan option, then I expect that both queries will have the same estimated number of rows. And then the costs will probably also be estimated the same.
Hugo Kornelis, SQL Server/Data Platform MVP (2006-2016)
Visit my SQL Server blog: https://sqlserverfast.com/blog/
SQL Server Execution Plan Reference: https://sqlserverfast.com/epr/ - N_Muller - Thursday, September 28, 2017 9:19 AM
I must object to your choice of words: "(...) took 96% of the batch and (...) took 4% of the batch". No, that is not true. Do not ever look at those percentages again.
As follows from my previous post, the percentages shown are derived off the estimated cost of each plan. But the estimated number of rows was, probably, wrong in this case as well, so these numbers have nothing to do with the actual cost of these plans.
I have not played enough with memory-optimized tables to be able to predict which of the two will have the lower estimated (or actual) cost when the statistics are equal.
(Note that in order to measure the actual cost you'll have to eliminate the overhead of sending the data to the client and rendering it in SSMS. One way is to use the UI option to discard the query results; another option would be to replace SELECT * with SELECT MIN(qid), MAX(id1), AVG(id2), COUNT(id3) or something similar - global aggregates that still force SQL Server to read all columns)
Hugo Kornelis, SQL Server/Data Platform MVP (2006-2016)
Visit my SQL Server blog: https://sqlserverfast.com/blog/
SQL Server Execution Plan Reference: https://sqlserverfast.com/epr/ - N_Muller - Thursday, September 28, 2017 9:19 AM
Final reply, to your last question.
A "normal" (non-hash) index allows a seek to traverse only a range. Similar to a phone book that is sorted by city, within city by last name, and withint (city, lastname) by first name.. You cannot easily find every "Muller" in the entire country by using that book, but you can quickly find every "Muller" in the cuty "Redmond". Similarly, you can use that index to find everyone with lastname > 'Y' in Redmond, but not everyone with lastname > 'Z' in the country.
In this case you have an equality predicate on qid and an inequality on id1; because the non-hashed nonclustered memory-optimized index on test_mo is on qid, id1, id2 (in that order), index ixh_test2_mo_id12 can be used to quickly find only qualifying rows.A hash index only supports equality searches, and they need to be on all columns in the index key. Your predicate has equaltiy on qid and inequality on id1, so for the hash indexes only the equality predicate on qid can be used. That limits the index choice to only ixh_test3_mo_qid.
If this had bean a traditional disk-based index, then the index structure could be used to find rows matching "gid = 3", and a pushed-down additional predicate on "id1 > 20627" would be used to eliminate non-qualifying rows before even returning them to the seek operator (they would still have to be fetched from disk and inspected by the storage engine, but the overhead of returning the data to the operator and filtering it out somewhere else in the plan would be avoided).
However, index seeks on memory-optimized nonclustered hash indexes do not support additional predicate pushdown (yet?). So that's why the index seek only has a seek predicates property for qid = 4, making it return all the rows that match this, which are then passed to the Filter operator to remove roww with non-qualifying id1 values.In this case, I expect the actual run time and resource usage of the first query to be lower. The non-hash index is specifically intended for query patterns that use inequality to define ranges within the entire set. The hash index is not optimal for that; this index shines when you have an equality predicate on all its key columns (and then especially when it matches just a very few rows) - because that is the type of workload that was specifically targeted for the performance benefits of memory-optimized tables and indexes.
Hugo Kornelis, SQL Server/Data Platform MVP (2006-2016)
Visit my SQL Server blog: https://sqlserverfast.com/blog/
SQL Server Execution Plan Reference: https://sqlserverfast.com/epr/ - Hugo Kornelis - Thursday, September 28, 2017 4:23 PM
Thanks for the replies.
On your first comment... I inserted data in the two tables identically. I had an original test_mo table where I entered data using recursive cte. Then I used that base table to copy data into children tables (test1_mo, test2_mo and test3_mo) so I could perform my tests. I only provided here the results that were questionable. All my memory optimized tables are schema_only durability in order to manage memory accordingly. The tables are used in stored procedures only and are cleaned up based on the qid we generated at the beginning of each procedure. I would have preferred using memory-optimized table types and table variables on the types, however the performance is nowhere near "permanent" memory-optimized tables. Given that, recreating statistics is not really much of an option, however I expect similar performance regardless of the method used for inserting the same data into a table.
I understand the difference between b-trees and hash indexes that move along linked lists. The point I was making is that I can have multiple columns on the table but I can't and shouldn't create indexes on all columns. I need to find the sweet spot where adding more indexes no longer pays off or whether I have different nonclustered indexes for different purposes. SQL Server 2014 limits 8 indexes per table. Generally that is plenty for me, but there are a few cases where I could have more indexes, or do some vertical table partition. Ideally, there should be a way to create a mixed of hash/b-tree columns on the same index.
- N_Muller - Thursday, September 28, 2017 5:44 PM
On the data insertion. Based on your reply, I must admit that I don't understand WHY the two queries have a different estimated number of rows, However, they do; that's very clear from the property lists you posted. And as I said, the different percentages you see are based on the estimated cost, which is very directly related to estimated number of rows. When the cardinality estimates are wrong, then those percentages mean nothing at all.
On table variables: Not surprised that these are slower.. Because memory-optimized objects are compiled, you take a performance penalty at create-time (which you earn back during the lifetime of the object). The first CTP version I played with took, if I remember correctly, up to a few seonds to create a memory-optimized table. 😉
On statistics: For improving the actual performance, creating statistics is, in this case, probably not needed. I only suggested that to get rid of the confusing query cost indications (which you as a general rule should never look at, but I know that 99% of all readers here will probably still continue to do just that), and because I thought you were working ina playground test environment to get an understanding of how things work.
On the limited index options for memory-optimized: Do not forget that this feature is specifically targeted towards high-volumne OLTP work. The type of workload where 99% of all queries are single-row lookups based on the key, and that need to be optimized for the fastest possible performance of inserts and lookups, with hopefullly also a good enough performance for updates and deletes - the performance of reporting quueries is secundary to all these. In tha type of workload, 8 indexes is usually already at least 5 too many. And even range seeks are rare. (The first CTP iterations of the memory-optimized features didn't even have the non-hash B-tree version; they were added later in the project, probably as a result of user feedback).
Of course, if your project is not a 100% fit for this intended workload, you can still reap the benefits of the feature. But you can expect that you'll have to solve at least some round-peg-square-hole issues, and that you might not always find an ideal answer.
You can of course open a request on Connect to support more than 8 indexes, or to get add an option for the hybrid hash / b-tree index structure you suggest. But I personally doubt that it will happen.However, to wrap back to your original question: There is no need to create additional indexes with extra columns in an effort to "cover a query" and avoid a lookup. Memory-optimized indexes are, just like row-based clustered indexes, covering by definition. And adding extra columns to a hash index would actually render the index worthless, because a hash index can only be used when the query has equality on ALL its columns.
Hugo Kornelis, SQL Server/Data Platform MVP (2006-2016)
Visit my SQL Server blog: https://sqlserverfast.com/blog/
SQL Server Execution Plan Reference: https://sqlserverfast.com/epr/
Viewing 11 posts - 1 through 11 (of 11 total)
You must be logged in to reply to this topic. Login to reply