


Nobody wants duplicate data. It’s messy, wastes space, and looks really bad on a report – I get that. What I don’t get is why so many people (developers, I’m lookin’ at you) think DISTINCT is the only way to avoid it. I’ve even run into folks who use DISTINCT on every query, you know, just in case. I realize it’s not all your fault, T-SQL makes it too easy to do things the wrong way. I’m writing this to show you the right way. You can avoid duplicate data without using DISTINCT, and in almost every case, you’ll find that your queries run faster and more efficiently.
Let’s look at an example. You’ll need the AdventureWorks2012 database. If you don’t have it running somewhere, first, what’s wrong with you, and second, you can download it by clicking here.
Imagine this typical, real-world scenario – your boss says “Build me a report that shows me which salespeople have sold red helmets, I want to take them all out on my yacht. And make it run as fast as possible, my time is valuable and I don’t like to wait.” You start coding, and in a matter of minutes, you’ve come up with this query:
-- Return list of salespersons who have sold red helmets<br>SELECT Person.LastName, Person.FirstName<br>FROM Production.Product<br>INNER JOIN Sales.SalesOrderDetail<br> ON Product.ProductID = SalesOrderDetail.ProductID<br>INNER JOIN Sales.SalesOrderHeader<br> ON SalesOrderDetail.SalesOrderID = SalesOrderHeader.SalesOrderID<br>INNER JOIN Person.Person<br> ON SalesOrderHeader.SalesPersonID = Person.BusinessEntityID<br>WHERE Product.Name = 'Sport-100 Helmet, Red';<br>

-- Return same list without duplicates.<br>SELECT DISTINCT Person.LastName, Person.FirstName<br>FROM Production.Product<br>INNER JOIN Sales.SalesOrderDetail<br> ON Product.ProductID = SalesOrderDetail.ProductID<br>INNER JOIN Sales.SalesOrderHeader<br> ON SalesOrderDetail.SalesOrderID = SalesOrderHeader.SalesOrderID<br>INNER JOIN Person.Person<br> ON SalesOrderHeader.SalesPersonID = Person.BusinessEntityID<br>WHERE Product.Name = 'Sport-100 Helmet, Red';<br>

SET STATISTICS TIME ON<br>SET STATISTICS IO ON<br><br>-- Return list of salespersons who have sold red helmets<br>SELECT Person.LastName, Person.FirstName<br>FROM Production.Product<br>INNER JOIN Sales.SalesOrderDetail<br> ON Product.ProductID = SalesOrderDetail.ProductID<br>INNER JOIN Sales.SalesOrderHeader<br> ON SalesOrderDetail.SalesOrderID = SalesOrderHeader.SalesOrderID<br>INNER JOIN Person.Person<br> ON SalesOrderHeader.SalesPersonID = Person.BusinessEntityID<br>WHERE Product.Name = 'Sport-100 Helmet, Red';<br>
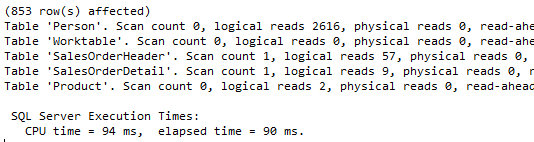
SET STATISTICS TIME ON<br>SET STATISTICS IO ON<br><br>-- Return same list without duplicates.<br>SELECT DISTINCT Person.LastName, Person.FirstName<br>FROM Production.Product<br>INNER JOIN Sales.SalesOrderDetail<br> ON Product.ProductID = SalesOrderDetail.ProductID<br>INNER JOIN Sales.SalesOrderHeader<br> ON SalesOrderDetail.SalesOrderID = SalesOrderHeader.SalesOrderID<br>INNER JOIN Person.Person<br> ON SalesOrderHeader.SalesPersonID = Person.BusinessEntityID<br>WHERE Product.Name = 'Sport-100 Helmet, Red';<br>

It’s tempting to give up at this point, convinced that you’ve done all that you can do, this query is as fast as it’s going to get. Sadly, giving up means risking the scorn and ridicule of your resident DBA, not the mention the guilt of knowing that you didn’t give your boss the fastest report possible. What to do?
SET STATISTICS TIME ON<br>SET STATISTICS IO ON<br><br>SELECT Person.LastName, Person.FirstName<br>FROM Person.Person<br>WHERE Person.BusinessEntityID IN<br> (<br> SELECT SalesOrderHeader.SalesPersonID<br> FROM Sales.SalesOrderHeader<br> INNER JOIN Sales.SalesOrderDetail<br> ON SalesOrderHeader.SalesOrderID = SalesOrderDetail.SalesOrderID<br> INNER JOIN Production.Product<br> ON SalesOrderDetail.ProductID = Product.ProductID<br> WHERE Product.Name = 'Sport-100 Helmet, Red'<br> );<br>
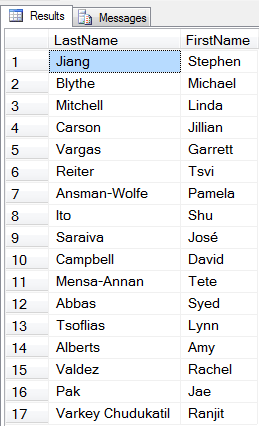
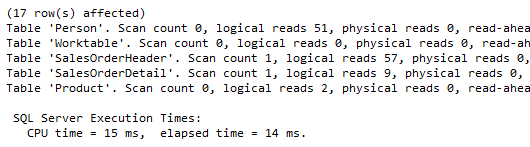
Just over 100 reads (less than 4% of the first two queries). Execution time of 14ms, let’s call it 18% of the time required for the first two queries to run. A significant improvement in efficiency.
The post Using A Non-correlated Subquery To Avoid DISTINCT appeared first on RealSQLGuy.
