SQL Server 2008 R2 CPU Blunted Spikes
-
Hi there,
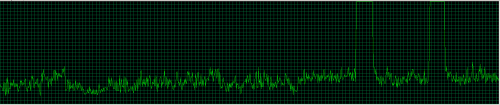
I'm looking for suggestions for statistics I could monitor to discover what could be causing the cpu "blunted spikes" (seen the visual attached CPUSpikes.png).
Some known information:
- sqlserver.exe is confirmed as the process consuming the CPU (2008 R2 Standard edition SP3).
- It's very intermittent in nature. Can't pin it down to a particular query. Profiler traces don't seem to show any correlation. In fact, it looks as though all queries are being made to wait during the spike, but interestingly there seems to be a correlation with there being a service broker queue with a backlog of messages currently being processed.
- Service broker is being used purely for asynchronous intra-database stored procedure execution, with heavy use of CLR functions.
- The SQL Server is housed in Amazon (using an EC2 instance)
I'm suspecting some sort of background thread or process that is "catching up", but I haven't been able to pin it down yet.Attempted Solutions- I have attempted to capture SQL Counters for compilations and re-compilations per second - any advice for other stats I should collect here would be great.
- I have attempted running SQLDiag (to collect stats), and then SQL Nexus to collate the results (but could not get this to work) - I am currently trying out pssdiag and sql nexus to collect further results (as sqldiag was unsuccessful for me).
Many thanks,
Laurence
-
Have you checked for simple but lengthy blocking and deadlocks?
I'd also be concerned about the nearly flat 30% CPU usage you're seeing.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Hey Jeff,
Thank you very kindly for your reply.
We have some monitoring software that alerts us to deadlocks and long running queries (that are being blocked) and their blocker as soon as they occur. Additionally, before this spike occurs, there are just about never any deadlocks or blocking.What's worse, a really simple query like select top 1 * from Table with(nolock) (enum table with only 20 records) will appear to hang (or wait) until the spike has subsided. Also, you cannot connect to the server during this spike.
I have done the following:
- Reduced recompilations - reduction in CPU usage in the transactional part of the system
- Optimised all queries that request large memory grants, as I saw that 3 or more of these resulted in a CPU spike (as well as the obvious memory issue).
- Improved numerous queries that resulted in heavy scans when joined with other tables caused heavy CPU usage
Other improvements have also been made, like ensuring there is no fragmentation in the log file etc...
Many thanks,
Laurence -
Sounds like you're taking all the right steps. There are a couple of things that may be an issue. The first is whatever monitoring software you're using. I've seen such things have this effect before although not as sporadically as what you say. Also, I've seen virus checkers that will do this if you haven't told them to exclude MDF/NDF/LDF and other files associated with SQL Server.
About the only other thing that I can suggest without personally watching your system is to get a copy of Adam Machanics WhoIsActive stored procedure and run it when you see one of the spikes occur.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Hi Jeff,
Thank you for your reply and help again.I will check for anti-virus software tomorrow. There might be something automatic that Amazon do, that we don't know about.
We have configured sp_whoisactive on the server too. The thing is, when the spikes occur, you can't run sp_whoisactive; even the profiler seems to hang, and no queries that incurred a long wait time (low CPU time, but with a long duration) seem problematic.
Again, thanks for taking the time to assist me,
Laurence -
I'm not sure what the interval represented in the graph is, but I've seen something similar when our DR backup software kicks in. Our spikes aren't anywhere near 100% CPU usage, but they give the same appearance, and database applications appear to "hang" for a few seconds.
Like yours, our service disruption is intermittent (and thankfully growing rarer). I'd ask Amazon about it, maybe it's something on their end?
Our server is local, not cloud, but the behavior is remarkably similar to what you're describing.
- laurence.proctor - Monday, April 3, 2017 1:54 AM
Yowch! That's just crazy. Roger (above) may be on to something.
Shifting gears, once you figure out the blunted spikes, I'd start looking into the nearly flat line 30% cpu usage. That seems pretty high even on a busy system.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Hey Roger,
Thanks for the reply.
We currently don't have any specific backup software - we simply use Ola Hallengren's backup code. Also, we only carry out 15-minute interval transaction log backups (which range from 10 MB to 2 GB - we saw spikes yesterday, and our log files were on average 80 MB in size - the spikes did not correlate to the backup times). To add to this, we do carry out daily full backups, which are subsequently uploaded to S3.Hey Jeff,
I have checked, and we don't have anti-virus software on our server.What I am doing today is collecting Wait statistics (using Paul Randal's scripts) to see if there is a correlation between the spikes and any waiting we might incur.
I am also going to try and use PSDiag to try and get as much info as possible.Again, thank you to all who have commented, replied, and assisted.
Regards,
Laurence -
Hey Jeff,
I forgot to add; the monitoring software is simply an SQL product I developed that only runs queries against the database (that I have checked to ensure are not carrying out large scans, or incurring expensive operations). In all of my tests, this software is less than 1% of the overall consumption on a daily basis.
And by the way, I really appreciate your assistance.Hey all,
I just wanted to report my findings this morning.I started collecting Wait Stats (using Paul's great scripts), and found the following:

This was no different when we faced the spikes / not.
Additionally, we saw spikes at the 8:42.20, and our backups had not even been triggered yet. The difference below is that the Spikes are not blunt, but rather peaking and staying at max CPU. I have been seeing this a lot lately (as well as the blunt spikes). Additionally, the spikes mainly seem to occur when we are processing large loads of data (through the SQL Broker).
Any further ideas?
Regards,
Laurence -
Does anybody have any further ideas?
Thank you to all who have assisted - It is much appreciated.

Viewing 10 posts - 1 through 10 (of 10 total)
You must be logged in to reply to this topic. Login to reply