

I know I'm getting old, but I had thought that all programmers knew what a carriage return was, in decimal, hex, and binary! But with new tools abstracting us away so much from the need to understand low level structures, perhaps this isn't something that is necessary as a base part of your computer programming knowledge. I don't agree with that, but I'm just one old CS guy.
I saw a post recently about someone asking about how to find a carriage return and split out a string, so I decided I ought to expand on this and let a few others know how do to this. This is probably fairly simple out there for many of you, but I've learned if one person posts a question there are probably 100 others that need a similar solution.
Complex Strings
These days a data feed can come from just about anywhere and despite standardization with things like web services and RSS, there is still the likelihood that you'll be working with all different kinds of formatted strings that you need to fit into your table. Let's take a simple feed:
We need to be sure that this purchase order is processed:
34030
Please check on the status
Not too bad and it's possible with all the advancements in SQL Server that someone will ask you, the DBA, to parse this out and grab the PO number. And they won't want to hear anything about needing a developer to help out. Actually, this might be one of those things that might get you laughed out of a developer's office if you ask for help.
This is actually a fairly simple problem to solve, but I've seen it posted a few times, so I thought I'd make use of a couple techniques I've used in the past to parse out strings in T-SQL. I've written a couple articles on substring and charindex, and techniques from those articles will be used here.
A Sample
Let's take a look at a fairly simple example. Imagine that you have read in a text file in DTS, SSIS, or whatever and you find yourself with a series of strings that look like the listing below. I've included row numbers so you can see which lines go to which records, but please, nobody tell Mr. Celko. I know there aren't really row numbers and databases don't worry about numbering rows. They are strictly there so you can see there are 5 rows in this table.
1 We need to be sure that this purchase order is processed:
34030
Please check on the status
2 We need to be sure that this purchase order is processed:
34031
Please check on the status
3 We need to be sure that this purchase order is processed:
34032
Please check on the status
4 We need to be sure that this purchase order is processed:
35932
Please check on the status
5 We need to be sure that this purchase order is processed:
35939
Please check on the status
Now we'll assume that we've stored these rows after our import in some table named OrderStatusCheck. Someone wants us to spit out a report of which purchase orders need to have someone check the status. If we give them query analyzer, they might be thrilled with a select output like this:

or even if we show them how to expand the output field like this:

And if we had some application read the table and spit out the msg field, it still might look funny. What we really want to do is grab the PO number. We can see a few things, like we know the colon (:) is character 57 (if you count out the string. But how much space is after the colon to the PO number? We could experiment here, but what if our input file isn't consistent? What if we have sometimes 3 spaces before the PO number on the second line and sometimes 5? What we really want to do is find out what's between the colon and the "Please".
We can identify the colon and the "Please" as markers. They give us an easy way to find the ends of our PO number. We can use a query such as this one to identify the positions of those markers.
select
charindex(':', msg)
, charindex('Please', msg)
, substring( msg, charindex(':', msg) + 1
, charindex('Please', msg) - charindex(':', msg) - 1)
from OrderStatusCheck
If you run this, you'll get something like this, depending on the whitespace in the source. I deliberately made a few different white space counts since as much as I rely on computers to be consistent, who knows what source data someone get into the PO field. I used the substring to start at the colon and continue on just before the "Please". That's the arithmetic in the substring parameters.
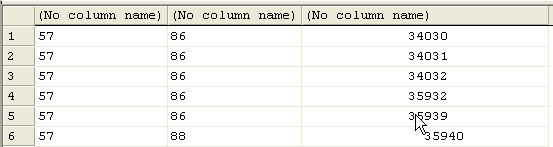
From here, it looks like we have solved the problem. All we need to do is add some trimming to remove the whitespace and we're done. Let's add this:
select
charindex(':', msg)
, charindex('Please', msg)
, substring( msg, charindex(':', msg) + 1
, charindex('Please', msg) - charindex(':', msg) - 1)
from OrderStatusCheck
which gives us this:
While many programs may deal just fine with the whitespace, what we really want is the PO just by itself. So let's just add a CAST since we're dealing with whitespace and get the PO.
select
cast(
substring( msg, charindex(':', msg) + 1
, charindex('Please', msg) - charindex(':', msg) - 1)
as int
) 'PO'
from OrderStatusCheck
It doesn't work. We get the wonderful message:
Server: Msg 245, Level 16, State 1, Line 1
Syntax error converting the varchar value '
34030
' to a column of data type int.
Can we trim things? Something like this?
select
ltrim(
rtrim(
substring( msg, charindex(':', msg) + 1
, charindex('Please', msg) - charindex(':', msg) - 1)
)
) 'PO'
from OrderStatusCheck
It doesn't work. That gives us a result like this:
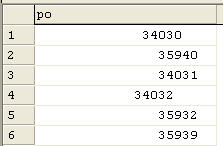
The issue is that the carriage returns are still there. A trim doesn't remove them or go around them. We can remove them with REPLACE, however, but we need to understand what we're removing. In Query Analyzer, we can actually just enter a carriage return in the code like this:
select
replace(
substring( msg, charindex(':', msg) + 1
, charindex('Please', msg) - charindex(':', msg) - 1
)
, '
', ' ')
'po'
from OrderStatusCheck
However in many languages this might cause issues, not to mention that the next gal or guy that comes along may wonder what exactly you're trying to replace here. A better solution is to use the actual ASCII codes to do the replace.
In the Windows world when you hit the "Enter" key there are actually two codes that are entered in the file. There's a carriage return, ASCII 13, and a line feed, ASCII 10. They are actually entered in that order. We can use the CHAR function to insert these values into our REPLACE function like this:
select
replace(
substring( msg, charindex(':', msg) + 1
, charindex('Please', msg) - charindex(':', msg) - 1
)
, char(13) + char(10), ' ')
'po'
from OrderStatusCheck
which returns the same thing, but if we wrap this in a CAST statement, we get what we want.
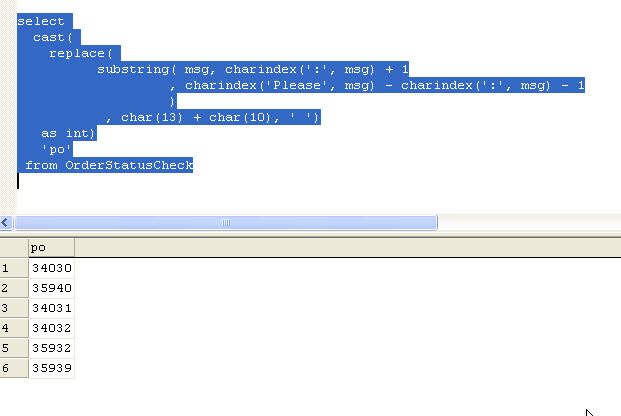
Conclusion
There's nothing magical here and I'm sure many of you know how to do this. The key, however, is having the information. It's in knowing how files are structured, something that I think is lost as we move further and further away from the hardware by programming abstractions.
Hopefully this is a little brush up in ASCII codes and a chance to reminisce back to the days of PEEKing and POKEing at memory, building text files code by code, and those early days of batch programming 🙂
©2007 dkranch.net - Steve Jones