

Snapshots are an integral part of replication and for the most part works
well with a default configuration. Over the next couple articles I'm going to
take you on a deeper tour of snapshots so that you'll understand how the default
configuration works and some ideas for when you need to tweak the configuration.
At the end it should look a lot less mysterious and hopefully that will
encourage you to try to replication when it's appropriate. To start at the beginning, what is a snapshot? A good but over simplified
definition might be:
It's the process of quickly copying the initial set of data from the
publisher to a subscriber so that we can proceed with the next steps in
replication
Snapshots are common across all the different publication types. In snapshot
replication - the simplest - we just create the snapshot, apply it to the
subscriber, and then we're done. For transactional and merge replication
snapshots are the first step to do the heavy work of creating the initial copy
of the data on the subscriber and then we maintain it using our other
replication agents.
So let's assume that you've previously created a publication called
SnapshotTest1 on Adventureworks that contains the Person.Address table. The most
interesting thing that happens as far as snapshot behavior is that a job is
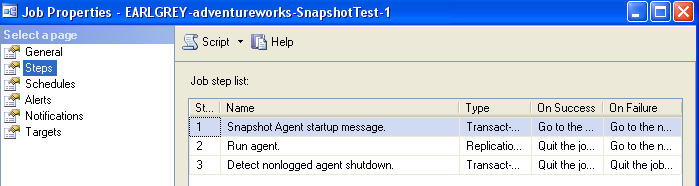
created that will execute snapshot.exe. In the image below you can see that
steps one and three are just logging, it's step two that does all the work.
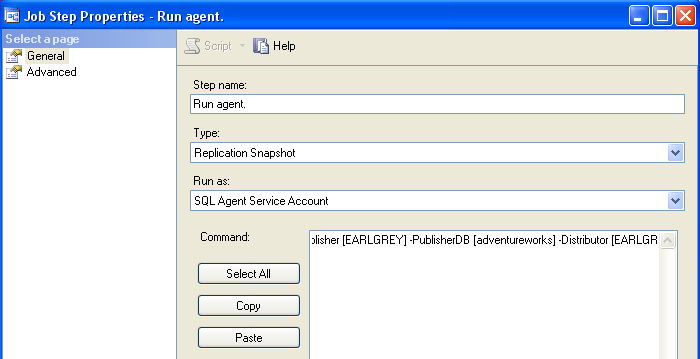
But what work? The next image shows the details of the job step, and the full
command text is:
-Publisher [EARLGREY] -PublisherDB [adventureworks] -Distributor [EARLGREY] -Publication [SnapshotTest1] -DistributorSecurityMode 1
We're sending all of that as command line parameters to Snapshot.exe telling it that my laptop is configured as the publisher and
distributor, that we're publishing from Adventureworks a publication called
SnapshotTest1, and that we're using Windows security. You can find the details
about all the switches in Books Online at
ms-help://MS.SQLCC.v9/MS.SQLSVR.v9.en/repref9/html/2028ba45-4436-47ed-bf79-7c957766ea04.htm.
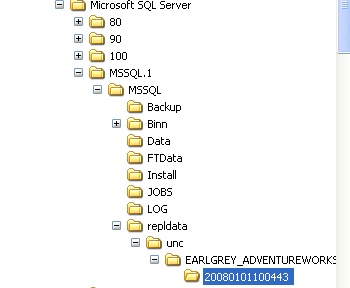
I'll add a subscriber on the same server so we have a destination, then run
the job so we can see what happens. Replication will create the repldata, unc,
and database folder (SERVERNAME_DATABASENAME format), and then create a folder
for the snapshot that is about to be created (folder name is just the
date/time). This folder can be put anywhere, just make sure that the snapshot
and distribution agents have access to the folder and that there is enough room
on the drive.
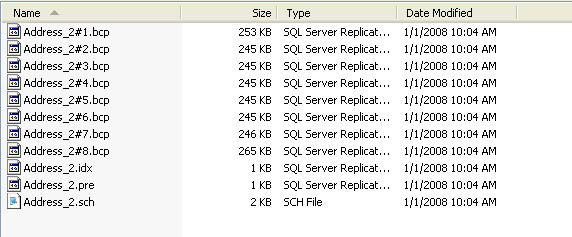
Here are the files created by the job:
So what do they mean?
- The *.BCP files contain the data from the Address table. In SQL 2000
there would only be one file created, the rules changed a little in SQL
SQL Server 2005 BCP Partitioning by Paul Ibison for a great explanation
of the change.
- The address_2.idx file contains a script to create the indexes on the
subscriber
- The address_2.sch file contains the script to create the table and the
replication specific stored procedures on the subscriber
- The address_2.pre file is a pre-snapshot script (though not the same as
the one you can configure manually) that by default drops the table on the
subscriber if it exists
At this point the work of the snapshot agent is done. In the next article
we'll look at what the distribution agent does with the files and how/when the
files get cleaned up.
