

In this article I will show you how to implement a stack. In programming, stacks are a great way to manage data or work. Everyone pulls from the same pool and there is no duplication (once a unit is pulled off the stack, it is no longer available to any other process). This can be accomplished in SQL Server using stored procedures. We don't need semaphores, we have ACID transactions, which will come in handy. If you will be attending my Virtual Presentation 'SSIS Workload Thread Balancing', this article will be a good foundation.
First thing we need to do is split the the workload into smaller units. This will be specific to each process. Second thing we need to do is provide a way to randomize the work we need to do and then distribute this work across as many threads as possible. Since each unit of work can take a different amount of time, you want to minimize the chance of a single thread getting a majority or possibly all of the work that take a long time. What's the point of having multiple threads if you have to wait for a single process to finish it's workload? You want to spread the workload across as many threads as possible to reduce the total time to finish the overall task.
In my real world example I need to calculate sales information for reps per company. I first create a table that I will later use to randomize the work. I will use the HashBytes function of SQL Server to do this for me as a calculated field in a column. This is a cryptographically secure function which will be excellent for randomizing the order of the rows (see Cryptographic Hash Functions).

The Rep/Company combination is needed by other processes so we have to create an additional temporary table to extract and finalize the data. I simply tacked on the Hash column as I developed the stack concept. The temporary table looks like this:

We then load this table with the data from the first table (T002_RepAssignment), add an order by based upon the hash and voila, we have our stack.

The first part of implementing a stack is complete, we built our stack. Now we need to build the process to emulate a 'pop'. As a refresher, you 'pop' things off a stack, the opposite of a 'push', which is how you normally create a stack. We can do this with a single stored procedure. Let's dissect this procedure and see how it works.
The procedure returns two pieces of information, @rcount (which will actually be a 0 or 1) and the unit of work to be done, @query (which is a fully qualified sql statement). What I do is send sql statements to the SSIS process to run. This procedure builds those SQL statements, while using the SSIS framework to manage the threads. The heart of the procedure is the blue highlighted section:A combination of Delete top(1) and output into a temporary table. In one fell swoop I grab the first row in the table, push it into a temporary table, then delete it. No need for a begin/commit tran with a select followed by a delete. Having multiple procedures running at the same time, they would only block for the delete and then continue on simultaneously.
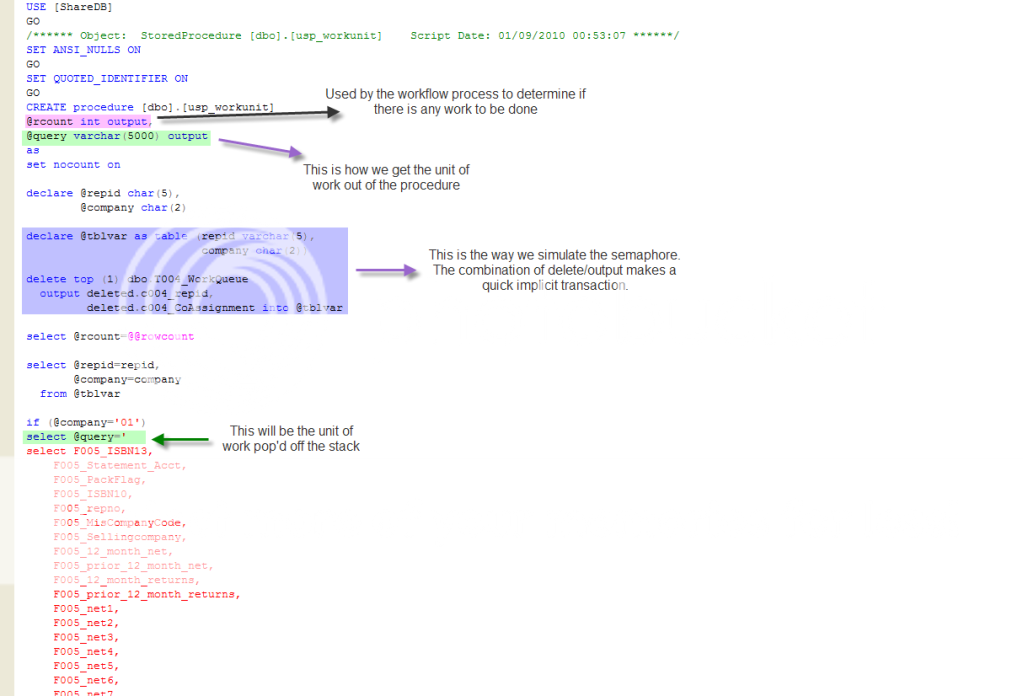
There you have it. The combination of using a cryptographic hash to randomize the data in the table (creating the stack), then using the Delete Top(1)/Output to pop the data off the stack in a quick and controlled manner.
