

Introduction
This is an old subject but, because of the number of posts that still appear every month about the subject here on SSC, another article seems appropriate as a reminder.
The posts where someone wants to use a variable for an IN type qualifier in a query are quite common. They want to use a comma delimited string for an IN. The string would typically be something passed in from a user interface. Something on the order of:
CREATE PROCEDURE SomeProc ( @StartDate DATETIME , @EndDate DATETIME , @String VARCHAR(50) ) AS SELECT SomeColumns FROM SomeTable WHERE SomeDate BETWEEN @StartDate And @EndDate AND SomeColumn IN (@String)
Of course, this is something SQL Server can't do (yet). We've all wished for something like this (don't lie - I know we have ALL wished for it! 😉
So how do we do this? We could use Dynamic SQL, which can be messy to maintain, can be a source of "SQL Injection" and really isn't necessary for this type of thing.
Wait a minute! An array is a SET of like data! SQL Server deals with sets! What do we call these SET things.... Hmm, let's see... Oh yeah - they're called tables. What we want to do is split up the array into a table of individual elements and use that for our qualifying condition. Let's see how we can do that.
References and Sources
There have been many good articles here on SSC on arrays and splitting up strings into tables. The most definitive, probably, is one by Jeff Moden:
Passing Parameters as (almost) 1, 2, and 3 Dimensional Arrays
Another excellent article by Alex Grinberg:
This one goes into how to do it with XML. XML has its uses, but really isn't necessary for this very simple operation. It also puts puts a load on network traffic and SQL Server itself.
Then the latest and greatest from Jeff Moden on splitting a string into a table. A very good read - dust bunnies and all:
Tally OH! An Improved SQL 8K "CSV Splitter" Function
I will be using the DelimitedSplit8K from this article in my examples below.
Test Data
For the purpose of this article I'm using a 2005 version of Adventureworks, since most people have it and can test the queries.
How a Hard-Coded "WHERE IN" Works
Let's say there is an application that passes 2 dates, a start and end date, and a list of sales people and wants the total sales and number of orders for each sales person in the date range. The following code will emulate a such a stored procedure:
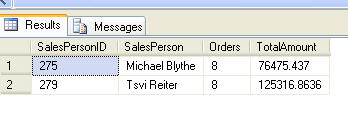
DECLARE @StartDate DATETIME , @EndDate DATETIME , @SalesPeople VARCHAR(255) SET @StartDate = '2001-07-01' SET @EndDate = '2001-07-31' SET @SalesPeople = '275,279' SELECT SO.SalesPersonID, C.FirstName + ' ' + C.LastName AS SalesPerson , COUNT(*) AS Orders , SUM(SO.SubTotal) AS TotalAmount FROM Sales.SalesOrderHeader SO INNER JOIN HumanResources.Employee E ON SO.SalesPersonID = E.EmployeeID INNER JOIN Person.Contact C ON E.ContactID = C.ContactID WHERE SO.OrderDate BETWEEN @StartDate And @EndDate AND SO.SalesPersonID IN (275, 279) -- The IN condition GROUP BY SO.SalesPersonID, C.FirstName, C.LastName
It produces a result set like:
Here is the meat part of the query plan:
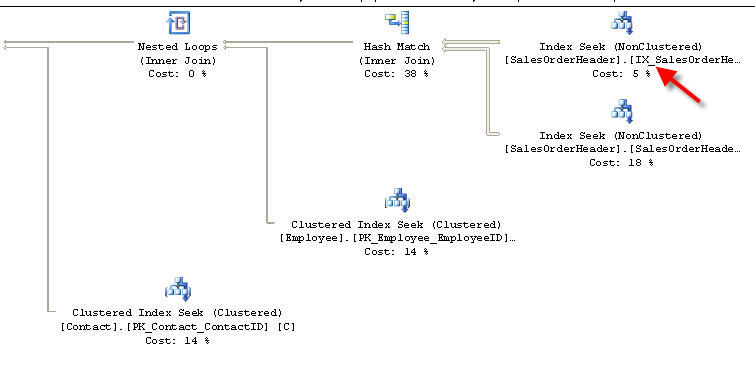
There is an index seek in SalesOrderHeader on SalesPersonID. Here are the details of that seek:
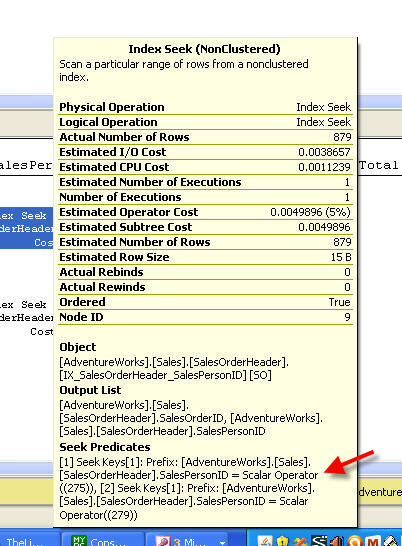
The IN part of the WHERE predicate generates an OR condition in the query plan. You would see exactly the same plan if the WHERE clause were:
WHERE SO.OrderDate BETWEEN @StartDate And @EndDate AND (SO.SalesPersonID = 275 OR SO.SalesPersonID = 279)
The only reason I bring this up is that once the parameter array has been split up into a table, the query plan will change. It will no longer generate an OR type condition.
Splitting and Using the "Array" Parameter as a Table
So how do we split our array into a table and use it? Here is a procedure that will do just that:
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[SalesPersonSumByDates]') AND type in (N'P', N'PC')) DROP PROCEDURE [dbo].[SalesPersonSumByDates] GO CREATE PROCEDURE SalesPersonSumByDates ( @StartDate DATETIME , @EndDate DATETIME , @SalesPeople VARCHAR(50) ) AS -- Create a temp table of Sales Persons. -- See Jeff Moden's Tally OH article for DelimitedSplit8K -- It returns VARCHAR so we convert it to INT to match SalesPersonID. SELECT CONVERT(INT, Item) AS SalesPersonID INTO #Sls FROM dbo.DelimitedSplit8K(@SalesPeople, ',') -- The query for the report. SELECT SO.SalesPersonID, C.FirstName + ' ' + C.LastName AS SalesPerson , COUNT(*) AS Orders , SUM(SO.SubTotal) AS TotalAmount FROM Sales.SalesOrderHeader SO INNER JOIN HumanResources.Employee E ON SO.SalesPersonID = E.EmployeeID INNER JOIN Person.Contact C ON E.ContactID = C.ContactID WHERE SO.OrderDate BETWEEN @StartDate And @EndDate -- The dynamic IN predicate. AND SO.SalesPersonID IN (SELECT SalesPersonID FROM #Sls) GROUP BY SO.SalesPersonID, C.FirstName, C.LastName RETURN
Notice that I'm still using an IN - it's just a SELECT statement rather than a hard coded IN condition.
Now run the procedure with this code:
EXEC SalesPersonSumByDates @StartDate = '2001-07-01' , @EndDate = '2001-07-31' , @SalesPeople = '275,279'
Notice that it produces exactly the same results as before. The query plan will look a little different since there are no hard coded scalar values for an OR. It really produces a JOIN.
I used a temp table rather than a table variable. Why? I've found that table variables used in a JOIN can be slow since the optimizer considers that there is only 1 row and the table has no statistics. This can make for a bad query plan, especially if there are a large number of elements in the "array" parameter. Here is the meat part of this plan:
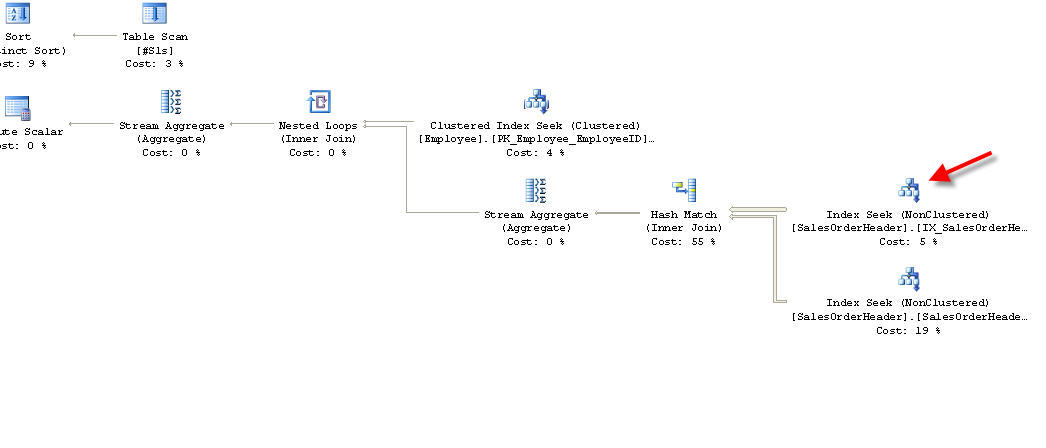
And the Seek predicate used:

There is only 1 Seek Key and it's based on the temp table #Sls.
Here is another version using EXISTS that produces the exact same query plan on my SQL Server:
SELECT SO.SalesPersonID, C.FirstName + ' ' + C.LastName AS SalesPerson , COUNT(*) AS Orders , SUM(SO.SubTotal) AS TotalAmount FROM Sales.SalesOrderHeader SO INNER JOIN HumanResources.Employee E ON SO.SalesPersonID = E.EmployeeID INNER JOIN Person.Contact C ON E.ContactID = C.ContactID WHERE SO.OrderDate BETWEEN @StartDate And @EndDate AND EXISTS -- Uses EXISTS instead of IN. (SELECT 1 FROM #Sls S WHERE S.SalesPersonID = SO.SalesPersonID) GROUP BY SO.SalesPersonID, C.FirstName, C.LastName
This can also be done with a direct JOIN of the temp table to the other tables. In this case you have to be careful that the user didn't enter the same parameter twice or the results will be doubled for that parameter - e.g. @SalesPeople = '275,279,275,279,279'. The user interface isn't likely to do this, but I've found it's better to assume that you can be passed some garbage.
Get around this by putting DISTINCT in the temp table creation part:
SELECT DISTINCT CONVERT(INT, Item) AS SalesPersonID -- Only 1 of each INTO #Sls FROM dbo.DelimitedSplit8K(@SalesPeople, ',') SELECT SO.SalesPersonID, C.FirstName + ' ' + C.LastName AS SalesPerson , COUNT(*) AS Orders , SUM(SO.SubTotal) AS TotalAmount FROM Sales.SalesOrderHeader SO INNER JOIN #Sls S ON -- INNER JOIN S.SalesPersonID = SO.SalesPersonID INNER JOIN HumanResources.Employee E ON SO.SalesPersonID = E.EmployeeID INNER JOIN Person.Contact C ON E.ContactID = C.ContactID WHERE SO.OrderDate BETWEEN @StartDate And @EndDate GROUP BY SO.SalesPersonID, C.FirstName, C.LastName
The INNER JOIN produces a slightly different plan on my SQL 2008, but runs in about the same amount of time as IN and EXISTS. Here is the plan for the JOIN version:
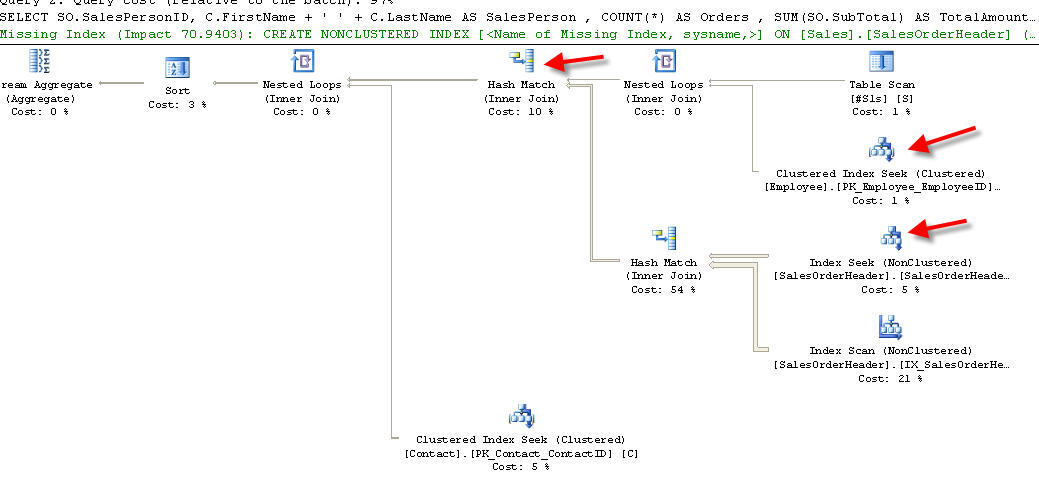
The plan is a little more involved in that the first JOIN is from #Sls to Employee and from there to SalesOrderHeader. It then gets resolved in the Hash Match:
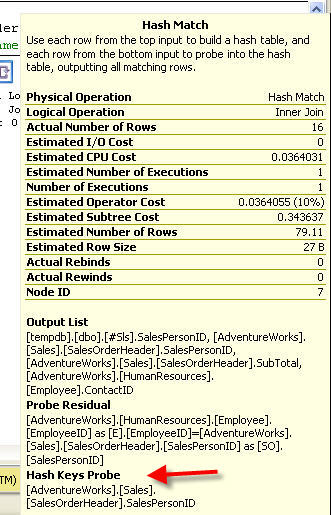
It's not as simple and straightforward as the other two plans and it takes on the average 10 ms. longer to run. You would have to try each one for any particular application to see what works best.
This could also probably be done with a CROSS APPLY, but I've never done it for this type of application.
Splitting and Using the "Array" Parameter as a CTE
If you have SQL 2005 or later, you can skip the creation of a temp table and simply use a CTE. Here is the IN version using a CTE instead of a temp table:
-- Use CTE instead of table. ; WITH CTESplit AS ( SELECT CONVERT(INT, Item) AS SalesPersonID FROM dbo.DelimitedSplit8K(@SalesPeople, ',') ) SELECT SO.SalesPersonID, C.FirstName + ' ' + C.LastName AS SalesPerson , COUNT(*) AS Orders , SUM(SO.SubTotal) AS TotalAmount FROM Sales.SalesOrderHeader SO INNER JOIN HumanResources.Employee E ON SO.SalesPersonID = E.EmployeeID INNER JOIN Person.Contact C ON E.ContactID = C.ContactID WHERE SO.OrderDate BETWEEN @StartDate And @EndDate AND SO.SalesPersonID IN (SELECT SalesPersonID FROM CTESplit) GROUP BY SO.SalesPersonID, C.FirstName, C.LastName
The CTE actually shaved 20 ms. off of my execution time. It may scale upwards better than the temp table, but you should try both and see for yourself.
I specifically didn't go into using the new table-value parameters for 2008. I'm a little embarrassed because I haven't had the chance to actually use one yet in a production environment so I'm far from an expert on them.
In short, a dynamic IN predicate is fairly easy to handle in SQL Server. Just convert it to what SQL handles best - a table.
Todd Fifield
