

There are many manual tasks and prerequisites required to add a database in an Availability Group (AG). Among these tasks, there may be challenges related to completing them, such as:
- We need to take a backup of a database from a primary replica and distribute it across all other replicas in an AG. This is basically a manual task because you need to restore the database on the secondary replica from the primary database backup.
- Sometimes we cannot transfer database backup files between replicas i.e. network firewall restrictions. In this case we have an additional prerequisite - we need to make sure that SMB ports are open in order to transfer backup files between nodes.
- Often, we don’t have enough space to copy a database backup files across all the replicas. That is another prerequisite.
- Additional database backups can break a backup/restore chain especially when we use 3rd party backup solutions. But that is depend on your database backup strategy.
- Distributing and restoring databases is a time consuming and non-transparent process.
Working as a DBA I would prefer not to deal with these challenges. When I create a database on the primary node, I want that database to be created on all replicas automatically. But that wasn’t possible before SQL Server 2016. In order to help DBA with this task, Microsoft introduced automatic seeding of availability groups in SQL Server 2016.
How Does This Work?
When you create a database on the primary replica and add that database into the AG, Automatic Seeding communicates over the database mirroring endpoint and copies the database to all the secondary replicas. Imagine you have an AG that consists of N replicas - Replica1, Replica2, ... ReplicaN. Currently your primary replica is Replica2 and you have created a brand new database on the primary replica. Your target is add that database to the AG with least possible effort and as fast as possible. That situation is shown on the blueprint below:
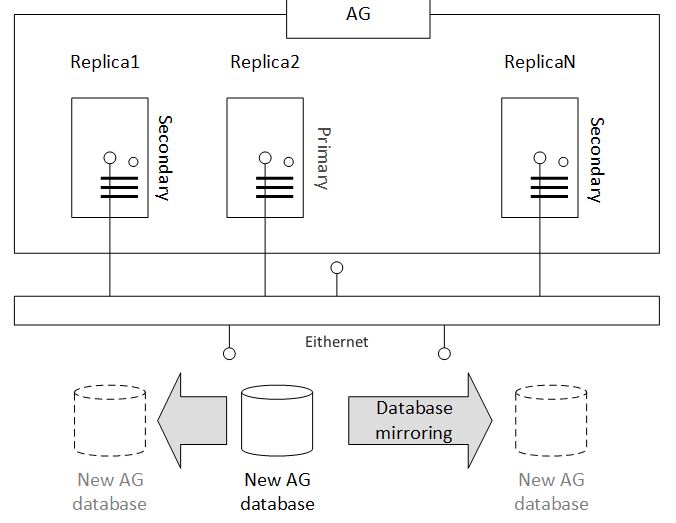
Automatic seeding doesn’t have any specific requirements and limitations apart from that it requires that the data and log file path is the same on every SQL Server instance participating in the Availability Group. The AG has to be configured for automatic seeding. Databases in an availability group must be in the full recovery model and need to have a current full backup and transaction log backup. The same requirements apply if you add a database in an AG using manual synchronization.
Enabling Automatic Seeding
On each replica where automatic seeding is required, you have allow the AG to create databases. The following script can be used, but make sure you connected to the master database and execute the script against all the replicas you have in that AG:
ALTER AVAILABILITY GROUP [{your_AG_name}]
GRANT CREATE ANY DATABASE;
GOThe AG have to be switched into the automatic seeding mode. That can be achieved by executing the T-SQL code below on your primary replica for each replicas in the AG (or each replicas where you want to enable the automatic seeding mode):
ALTER AVAILABILITY GROUP [{your_AG_name}]
MODIFY REPLICA ON '{your_replica_name}'
WITH (SEEDING_MODE = AUTOMATIC);
GOAdditionally, compression of the data stream for Always On Availability Groups during automatic seeding can be enabled using trace flag 9567. You can read about that here: https://docs.microsoft.com/en-us/sql/t-sql/database-console-commands/dbcc-traceon-trace-flags-transact-sql
Adding a Database with Automatic Seeding
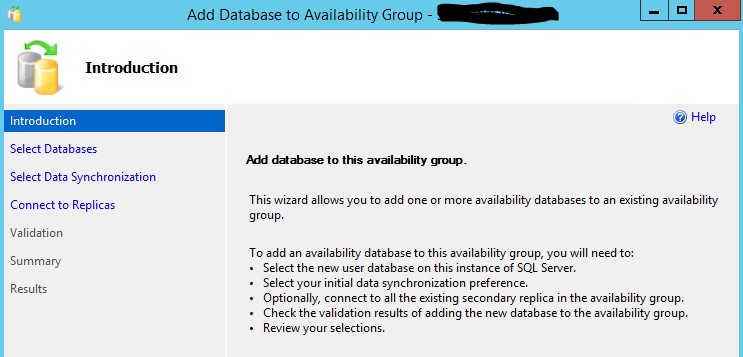
Open the "SQL Server Management Studio" and connect to the primary AG node. Navigate to "AlwaysOn High Availability" folder and unfold it. Unfold "Availability Groups" and find the AG where you want to add a new database. After unfolding this AG you will see "Availability Databases" folder. Right click on the "Availability Databases" folder and invoke right click menu "Add databases..", the menu option will invoke the wizard shown below:
Select the database(s) you want to add to an AG:
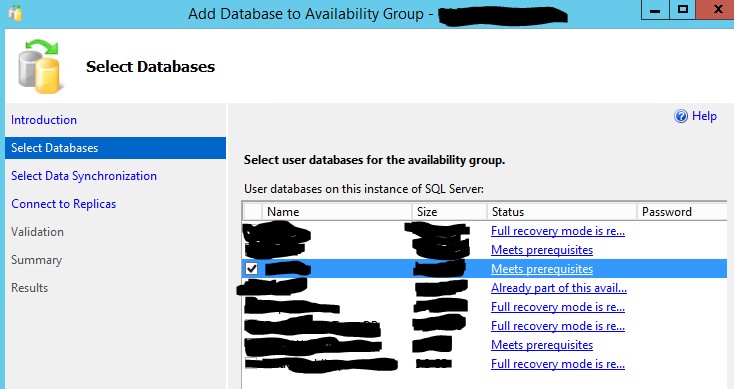
Note. The database(s) must meet prerequisites.
Choose the option “Skip initial data synchronization”:
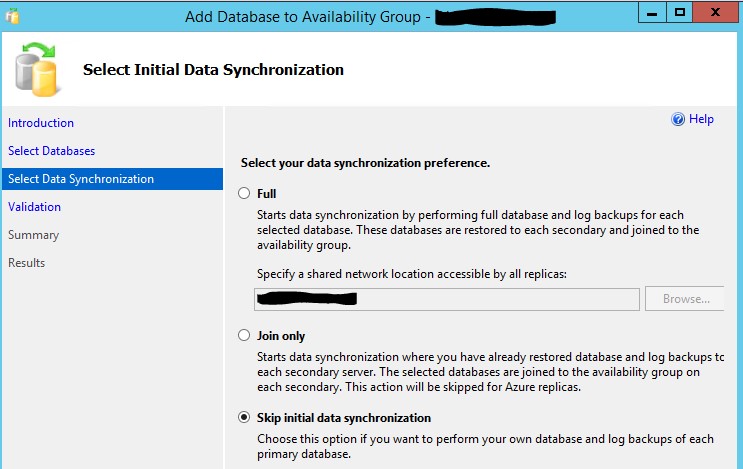
On the secondary node(s) you will see messages that the database(s) has(have) been restored:
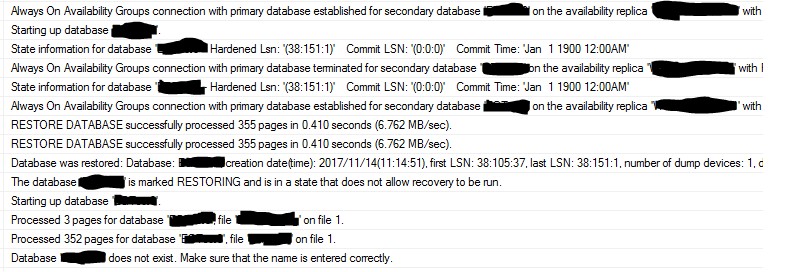
Also you will see a record in the ‘msdb.dbo.restorehistory’ table per each added database. On the primary server you will see a record in the table ‘msdb.dbo.backupmediafamily’ per each database with device_type=7.
A database can be added using T-SQL command:
ALTER AVAILABILITY GROUP {your_AG_name} ADD DATABASE {your_database_name}; 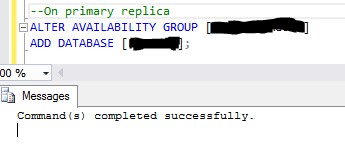
This script has to be applied to each database you want to add in an AG.
Pros and cons
I used the Automatic Database Seeding for several AG and found it particularly useful feature. For example Microsoft Sharepoint support team has rights to create new databases on the primary AG replica, but they can't add these databases into the AG and that can breach our SLA by affecting high availability of databases. For example, the SLA could be breached because of the communication issue in between DBA and Sharepoint teams. When we use Automatic Database Seeding on that particular AG we can automate adding new Sharepoint databases in the AG using a script which adds all recently created Sharepoint databases into the AG. Without that feature the process was manual.
In order to sum up, the benefits of using automatic seeding on an AG are:
- Simplicity of the process.
- Save disk space, which otherwise would be used by backup files.
- Save times required to backup and restores because SQL Server copies databases on the fly using the network.
- With trace flag 9567, this can significantly reduce time required to synchronize replicas.
The drawbacks of using automatic seeding on an AG:
- Significant network flow between replicas during the synchronization process (which could be reduced using the trace flag 9567).
- The process does contain some manual steps.
