

The enhanced OVER clause support and the new Analytic functions in SQL Server® 2012, better known as the Window functions, brought some interesting capabilities to the platform. Having used the Window functions quite extensively on various platforms I have learned to appreciate them for the performance benefits and how some previously complex solutions can be simplified. Now I want to share my thoughts on using the Window functions and hopefully this article will encourage other readers to do the same.
This article has two parts, the first part explains how the new cross row referencing functions LAG() and LEAD() can help improve the performance when splitting text in T-SQL. The second part demonstrates how simple windowed aggregation can be used to extend the functionality of the previous exercise.
Part 1, a LEAD for improved performance.
There are few performance-related challenges to overcome when splitting delimited strings in T-SQL. Fortunately some good work is already out there and quite few articles are available on the subject. To establish what can be improved by using the Window functions, one must first look at the actual work involved and then explore the alternatives.
Looking at the “work” part of Jeff Moden's DelimitedSplit8K function we see that the first part scans the string to find the position of every delimiting character. The second half uses the delimiters position as a starting point for both the SUBSTRING() function and the CHARINDEX(), the former for retrieving the substring and the latter finds the next delimiter position to calculate the length of the substring.
CREATE FUNCTION [dbo].[DelimitedSplit8K]
--===== Define I/O parameters
(@pString VARCHAR(8000), @pDelimiter CHAR(1))
RETURNS TABLE WITH SCHEMABINDING AS
RETURN
--===== "Inline" CTE Driven "Tally Table” produces values from 0 up to 10,000...
-- enough to cover VARCHAR(8000)
WITH E1(N) AS (
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), --10E+1 or 10 rows
E2(N) AS (SELECT 1 FROM E1 a, E1 b), --10E+2 or 100 rows
E4(N) AS (SELECT 1 FROM E2 a, E2 b), --10E+4 or 10,000 rows max
cteTally(N) AS (--==== This provides the "zero base" and limits the number of rows right up front
-- for both a performance gain and prevention of accidental "overruns"
SELECT 0 UNION ALL
SELECT TOP (DATALENGTH(ISNULL(@pString,1))) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E4
),
cteStart(N1) AS (--==== This returns N+1 (starting position of each "element" just once for each delimiter)
SELECT t.N+1
FROM cteTally t
WHERE (SUBSTRING(@pString,t.N,1) = @pDelimiter OR t.N = 0)
)
--===== Do the actual split. The ISNULL/NULLIF combo handles the length for the final element when no delimiter is found.
SELECT ItemNumber = ROW_NUMBER() OVER(ORDER BY s.N1),
Item = SUBSTRING(@pString,s.N1,ISNULL(NULLIF(CHARINDEX(@pDelimiter,@pString,s.N1),0)-s.N1,8000))
FROM cteStart s
;
GO
In a procedural pseudo code the DelimitedSplit8K algorithm with the CHARINDEX function expanded (in bold).
while not EndOfString ; loop through the string to
if string[pos] == delimiter ; find a delimiter, then
previous_pos = pos ; record the position and
next_pos = previous_pos + 1 ; pass it to the charindex function
while not EndOfString ; scan the string from the position
if string[next_pos] == delimiter ; find the next delimiter
output substring ( character_string, ; and return the part of the
previous_pos, ; string between the two.
next_pos – previous_pos )
exit loop
iterate next_pos
loop
iterate pos
loopwhich translates to a Set based pseudo-code;
select substring
(
pos
,(select TOP(1) pos ; select characters where position is
from string ; greater than pos
where string[next_pos] == delimiter ; find the next delimiter
and pos < next_pos ; shown here as a subquery
) - pos
)
from string
where char[pos] == delimiter
It doesn't matter how we dress it, the algorithm is doing an extra scan of the string! But since we are working with a set and the set already has the positions of the all the delimiters, we should be able to retrieve the next delimiter position from the set instead of (re)scanning the string to find it.
For those who caught the contradiction in the previous statement, we are forcing the order of the retrieval of values from the set in the clause;
ROW_NUMBER() OVER(ORDER BY s.N1).
Four of the Window functions introduced in SQL Server® 2012 are cross-row referencing functions, FIRST_VALUE(), LAST_VALUE(), LAG() and LEAD(). In this case we are interested in the latter two. On the label it says (contracted):
LAG / LEAD (scalar_expression [ ,offset ] , [ default ] ) OVER ( [ partition_by_clause ] order_by_clause)
Accesses data from a previous /subsequent row in the same result set without the use of a self-join in SQL Server 2012. LAG/LEAD provides access to a row at a given physical offset that comes before/follows the current row. Use this analytic function in a SELECT statement to compare values in the current row with values in a previous/following row.
In other words, retrieve a value from another row by a given offset and if not found pass the default. This means that the CHARINDEX() can be replaced with the LEAD() function, nearly halving the amount of work needed:
Item = SUBSTRING(@pString,s.N1,ISNULL(NULLIF((LEAD(s.N1,1,1) OVER (ORDER BY s.N1) – 1),0)-s.N1,8000))
In the same procedural pseudo-code as before the DelimitedSplit8K with the LEAD() now looks better with only a single scan of the string;
while not EndOfString ; loop through the string to find all
if string[pos] == delimiter ; delimiters and retrieve the strings
output substring ( character_string, ; between the delimiters
pos,
next_pos – pos )
iterate pos
loop
and in a set based pseudo-code;
select substring(pos,next_pos - pos) from string where char[pos] == delimiter
Putting the changes to a test using Jeff Moden's excellent Splitter test script produces the expected results, the LEAD() versions outperforming the CHARINDEX() ones by up to 50%.
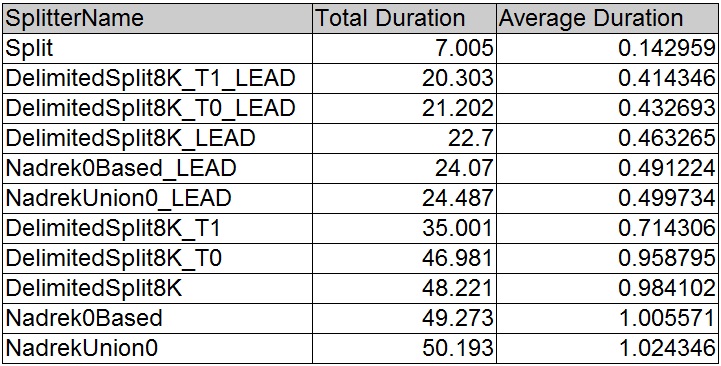
A noticeable improvement and a good example of how performance can be improved by using the Window functions. In this particular problem the only code modification was the replacement of CHARINDEX() function with the LEAD() function.
Before:
CHARINDEX(@pDelimiter,@pString,s.N1)
After:
LEAD(s.N1,1,1) OVER (ORDER BY s.N1) – 1
How does it work?
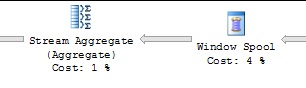
Looking into the details of the query execution using the “Include Actual Execution Plan” we see the new Window Spool and a Stream Aggregate operator.
STATISTICS IO output shows a Worktable with zero IO:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Itzik Ben-Gan explains this as "the Window Spool iterator uses a highly optimized, in-memory work table, without all of the usual overhead that exists with work tables in tempdb, such as I/ O, locks, latches, and so forth." (Ben-Gan,I.,2012,Kindle Locations 3499-3501).
In this case the Window Spool operator in conjunction with the Stream Aggregate operator provide the cross-row reference with almost no overhead.
Part 2 - Parsing a CSV
When it comes to real world problems, the simple delimiter splitting functions do leave few things to be desired. In many ways one could argue that so far it has been more of “coding for the optimal problem” than “optimally coding for the problem” as a large portion of the delimiter separated data one has to deal with on a daily basis is slightly more complex. The biggest shortcomings would propably be the handling of text qualifiers according to RFC-4180.
For the sake of argument we introduce a typical “Artist” record
100123,"Blues","West Point, Mississippi","Burnett,""Howlin' Wolf"" Arthur Chester",1910-06-10.
Using our previous splitter functions to parse the Artist record certainly does not produce the desired results:
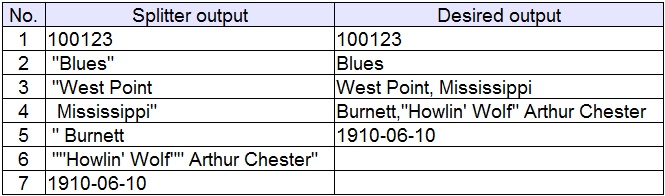
Or as this visual presentation of the CSV logic reveals, there is some level of the complexity;
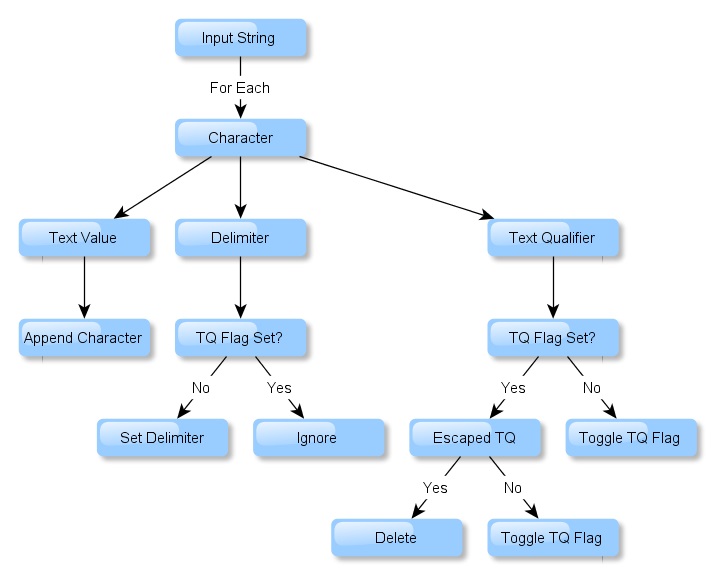
Here's the CSV Splitter logic translated into the procedural pseudo-code;
while not EndOfString
if string[pos] == [text qualifier]
if string[previous_pos] != [text qualifier]
set InTextQualifier = !InTextQualifier
else
delete previous_pos
end if
end if
if string[pos] == [delimiter] [AND NOT] InTextQualifier
output substring ( character_string, pos, next_pos – pos )
end if
iterate pos
loopAt first glance this looks like a contorted and complex code in T-SQL. Even the C(ursor) word comes to mind! Interestingly enough the problem is somewhat simpler when looked at as a set based rather than procedural based task. Again, using the set based pseudo-code to describe the problem:
select
unescape_text_qualifier(substring(string, pos, next_pos - pos))
where (pos and next_pos) not between text_qualifier
This may only look like a simplification of the problem but in fact it is very accurate. Starting with the filtering of the sets, “where pos / next_pos not between text_qualifier”, how can the range of active text qualifiers be defined? The answer is by counting the text qualifiers and when the count is an odd number, then the text qualifiers are “active”. A running total by the order of the character position will then provide the means of identifying the active and inactive parts of the character set.
/*********************************************************************
Using Jeff Moden's DelimitedSplit8K as a base with the addition
of a Text Qualifier parameter, @pTxtQualifier CHAR(1) = '"'
*********************************************************************/
DECLARE @pString VARCHAR(8000) = ''
DECLARE @pDelimiter CHAR(1) = ',';
DECLARE @pTxtQualifier CHAR(1) = '"';
-- A typical Artist record
SELECT @pString = '100123,"Blues","West Point, Mississippi","Burnett,'
+ '""Howlin'' Wolf"" Arthur Chester",1910-06-10,';
/*********************************************************************
cteTally, inline Tally table returning a number sequence equivalent
to the length of the input string. The Cast of the Len() to a
Bigint prevents an implicit cast.
*********************************************************************/;WITH E1(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
cteTally(N) AS
(
SELECT
ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM E4
ORDER BY 1 OFFSET 0 ROWS
FETCH FIRST CAST(LEN(@pString) AS BIGINT) ROWS ONLY
)
/********************************************************************
Retrieve the position (N) and the character code (chrCode)
for all delimiters (@pDelimiter) and text qualifiers
(@pTxtQualifier)
********************************************************************/,ctePrimer(N,chrCode) AS
(
SELECT
t.N
,UNICODE(SUBSTRING(@pString,t.N,1)) AS chrCode
FROM cteTally t
WHERE SUBSTRING(@pString,t.N,1) COLLATE Latin1_General_BIN
= @pDelimiter COLLATE Latin1_General_BIN
OR SUBSTRING(@pString,t.N,1) COLLATE Latin1_General_BIN
= @pTxtQualifier COLLATE Latin1_General_BIN
)
/********************************************************************
The cteStart encloses the string in virtual delimiters using
Union All at the beginning and the end. The main body sets the
IsDelim and IsTxQf flags.
********************************************************************/,cteStart(N,IsDelim,IsTQA) AS
(
SELECT
0 AS N
,1 AS IsDelim
,0 AS IsTxQf
UNION ALL
SELECT
t.N
,(1 - SIGN(ABS(t.chrCode - UNICODE(@pDelimiter)))) AS IsDelim
,(1 - SIGN(ABS(t.chrCode - UNICODE(@pTxtQualifier)))) AS IsTxQf
FROM ctePrimer t
UNION ALL
SELECT
LEN(@pString) + 1 AS N
,1 AS IsDelim
,0 AS IsTxQf
)
/********************************************************************
Position (N), Delimiter flag (IsDelim), Text Qualifier flag
(IsTQA) and the running total of the number of appearance of
Text Qualifiers
********************************************************************/SELECT
cST.N
,cST.IsDelim
,cST.IsTQA
,SUM(cST.IsTQA)
OVER (ORDER BY cST.N
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS TQRT
,CASE
WHEN SUM(cST.IsTQA)
OVER (ORDER BY cST.N
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) % 2 = 1 THEN 'X'
ELSE ''
END AS Active
FROM cteStart cSTAs before, the query starts with an inline Tally table in place of an iterative structure. The ctePrimer then selects all positions (N) where the character is either a delimiter or a text qualifier. The next part, cteStart then assigns either 0 or 1 to the two flags. IsDelim is set to 1 when the character is a delimiter and IsTxQf is set to 1 when the character is a text qualifier.
The output of the query correctly identifies the active and inactive delimiters;
| N | IsDelim | IsTQA | TQRT | Active |
| 0 | 1 | 0 | 0 | |
| 7 | 1 | 0 | 0 | |
| 8 | 0 | 1 | 1 | X |
| 14 | 0 | 1 | 2 | |
| 15 | 1 | 0 | 2 | |
| 16 | 0 | 1 | 3 | X |
| 27 | 1 | 0 | 3 | X |
| 40 | 0 | 1 | 4 | |
| 41 | 1 | 0 | 4 | |
| 42 | 0 | 1 | 5 | X |
| 50 | 1 | 0 | 5 | X |
| 51 | 0 | 1 | 6 | |
| 52 | 0 | 1 | 7 | X |
| 65 | 0 | 1 | 8 | |
| 66 | 0 | 1 | 9 | X |
| 82 | 0 | 1 | 10 | |
| 83 | 1 | 0 | 10 | |
| 94 | 1 | 0 | 10 | |
| 95 | 1 | 0 | 10 |
Encapsulating the logic in a CTE cteWorkSet, replacing the previous select statement, now effectively cancels out all delimiters which are not between text_qualifier;
/********************************************************************
cteWorkSet:
Position (N), Delimiter flag (IsDelim), Text Qualifier flag
(IsTQA) and the running total of the number of appearances of
Text Qualifiers. The delimiters which are inside Text Qualifiers
are cancelled out by multiplying the IsDelim flag with the result
of ( 1 + the running total of IsTQA ) mod 2.
********************************************************************/,cteWorkSet(N,IsDelim,IsTQA) AS
(
SELECT
cST.N
,cST.IsDelim * ((1+ SUM(cST.IsTQA) OVER
(PARTITION BY (SELECT NULL) ORDER BY cST.N
ROWS UNBOUNDED PRECEDING)) % 2) AS IsDelim
,((SUM(cST.IsTQA) OVER (PARTITION BY (SELECT NULL)
ORDER BY cST.N ROWS UNBOUNDED PRECEDING)) % 2) AS IsTQA
FROM cteStart cST
)
SELECT
N
,IsDelim
,IsTQA
FROM cteWorkSet
WHERE IsDelim = 1 OR IsTQA = 1| N | IsDelim | IsTQA |
| 0 | 1 | 0 |
| 7 | 1 | 0 |
| 8 | 0 | 1 |
| 15 | 1 | 0 |
| 16 | 0 | 1 |
| 27 | 0 | 1 |
| 41 | 1 | 0 |
| 42 | 0 | 1 |
| 50 | 0 | 1 |
| 52 | 0 | 1 |
| 66 | 0 | 1 |
| 83 | 1 | 0 |
| 94 | 1 | 0 |
| 95 | 1 | 0 |
The positions of the active delimiters, identified by the IsDelim flag equals 1.
Preparing the output in a CTE by adding both LAG() and LEAD() for the Start and Length calculation;
cteWSTQ(P_START,IsDelim,NEXT_IsTQA,LAG_IsTQA) AS
(
SELECT
cWS.N AS P_START
,cWS.IsDelim AS IsDelim
,LEAD(cWS.IsTQA,1,0) OVER (ORDER BY cWS.N) AS NEXT_IsTQA
,LAG(cWS.IsTQA,1,0) OVER (ORDER BY cWS.N) AS LAG_IsTQA
FROM cteWorkSet cWS
WHERE cWS.IsDelim = 1
OR cWS.IsTQA = 1
)The formula for calculating the starting point is then
P_START + NEXT_IsTQA + SIGN(P_START)
where P_START is the actual position of the delimiter, NEXT_IsTQA indicates whether the field has Text Qualifiers and finally the SIGN(P_START) shifts all but the first field by 1 position to exclude the actual delimiter character.
Calculating the length of the field is then done by subtracting the start position from the end position and adding the offset correction to the start position.
LEAD(X.P_START,1,0) OVER (ORDER BY X.P_START) - ((X.P_START + X.NEXT_IsTQA) + SIGN(X.P_START) + LEAD(X.LAG_IsTQA,1,0) OVER (ORDER BY X.P_START))
As the outputs of the Window functions are needed to filter the set in order to exclude the last record where the length is a negative value, another CTE is added to the mix;
cteWSLEN(P_START,P_LEN) AS
(
SELECT
(X.P_START + X.NEXT_IsTQA + SIGN(X.P_START)) AS P_START
,(LEAD(X.P_START,1,0) OVER (ORDER BY X.P_START) -
((X.P_START + X.NEXT_IsTQA) + SIGN(X.P_START) +
LEAD(X.LAG_IsTQA,1,0) OVER (ORDER BY X.P_START))) AS P_LEN
FROM cteWSTQ X WHERE X.IsDelim = 1
)
All that is left to do now is to pass the output of the cteWSLEN to the SUBSTRING() function and add a ROW_NUMBER() for the ItemNumber. It is very important that the ORDER BY clause of the ROW_NUMBER() function is set to (SELECT NULL). Otherwise the optimizer will introduce a rather expensive SORT operator.
/******************************************************************** Splitting the string using the output of the cteWSLEN, filtering it by the length being non-negative value. The NULLIF returns NULL if the field is empty. ********************************************************************/ SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS ItemNumber ,NULLIF(REPLACE(SUBSTRING(@pString,cWL.P_START,cWL.P_LEN),@pTxtQualifier+@pTxtQualifier,@pTxtQualifier),'') AS Item FROM cteWSLEN cWL WHERE cWL.P_LEN > -1
Here are the results:
ItemNumber Item -------------------- -------------------------------------- 1 100123 2 Blues 3 West Point, Mississippi 4 Burnett,"Howlin' Wolf" Arthur Chester 5 1910-06-10 6 NULL
Performance vs Functionality
The added functionality does come at a price. When compared to the simple split functions it is more than three times slower. But then again like someone once said, "it doesn't matter how fast your code is if it doesn't work".
The single most expensive part is the replacement of the escaped text qualifiers. Without it the function code is still faster than most splitting functions which use the CHARINDEX() function.
,NULLIF(REPLACE(SUBSTRING( @pString,cWL.P_START,cWL.P_LEN) ,@pTxtQualifier+@pTxtQualifier,@pTxtQualifier),'') AS Item
It is rather obvious that this string manipulation is slow so improving it could be a future challenge.
Moving on to more complex parsing
Recently I was asked if I knew of a way to normalize parameterized dynamic SQL strings being captured by a monitoring system. The problem was that the values passed to the parameters would also be captured, creating a number of entries for each individual query statement. The problem is best described by a “before” and “after” example;
Before:
EXEC sp_executesql N'USE AdventureWorks2012; SELECT PROD.ProductID,PROD.Name FROM Production.Product PROD WHERE PROD.ProductNumber = @PARAM_1',N'@PARAM_1 NVARCHAR(25)',@PARAM_1=N'BA-8327'
After:
EXEC sp_executesql N'USE AdventureWorks2012; SELECT PROD.ProductID,PROD.Name FROM Production.Product PROD WHERE PROD.ProductNumber = @PARAM_1',N'@PARAM_1 NVARCHAR(25)',@PARAM_1=#
This is slightly more complex than the previous CSV parsing but still could be achieved using a variation of the same technique, even if neither the name nor the number of parameters are known. Any suggestions?
References
Ben-Gan, Itzik (2012-04-19). Microsoft® SQL Server® 2012 High-Performance T-SQL Using Window Functions. OReilly Media - A. Kindle Edition.
Jeff Moden, Tally OH! An Improved SQL 8K “CSV Splitter” Function, http://www.sqlservercentral.com/articles/Tally+Table/72993/ , accessed 2013-12-29
Code for the DelimitedSplit8K_LEAD and CSVSplitter is in the resource section.
