

Problem
Your CTO has decided to migrate the entire 7*24 OLTP SQL Server production environment to a private cloud. Your database system consists of seventeen standalone physical SQL Servers ranging from SQL 2000 to 2008. You are to migrate to two 2-node clusters and 1 standalone server with minimal business impact. The CTO has mandated three months of testing leading up to the migration with current schema and data. Besides getting a new CTO, how do you plan to migrate with minimal business impact? How do you make the new environment available for testing? What features of SQL Server and Red Gate software tools can you leverage to ensure a smooth migration?
Solution
This article reviews an actual SQL Server migration from a self-managed production environment to a new hosted environment. I describe how 138 databases, 2,516 tables, and thousands of stored procedures were kept synchronized and available for months right up to the migration. Critical to this solution was to allow programming to test against the new environment while keeping schema and data synchronized. I’ve included the needed T-SQL and Red Gate scripts
Minimal outage data center migration is essential to a business’s success, so DBAs need to leverage the data migration features of SQL Server to provide a seamless migration. Different versions of SQL Server support different features, so how do you choose between backup/restore, log shipping, mirroring, replication, or third party utilities? One approach is to review how the data will be used during the time leading up to migration.
Methodologies
As SQL Server DBAs, we have log shipping, replication, mirroring and backup/restore to aid database migration. Unfortunately, in my case the new environment’s tables were required for on-going update testing and constant synchronizing with production. That ruled out log shipping and mirroring as the tables had to be available all the time with their current names. It is worth noting that mirroring requires both primary and secondary servers to be the same SQL SERVER edition. In my case, and perhaps yours, I have both Enterprise and Standard editions, so mirrorring wasn’t even possible. (Come on, Microsoft, tear down that wall). Standard replication doesn’t allow subscriber updates and bi-directional replication could jeopardize production. That left backup/restore.
However, it would be impossible to restore 138 databases at cutover quick enough to keep the CTO happy. In order to allow programming to test in the new environment over the months leading up to the cutover I needed a process that restored all the data then synchronized data and schema no matter how many rows or stored procedures were changed during testing.
Strategy
I needed a strategy, and I found one. Three months before the cutover I had all 138 databases backed up from production to removable disks, which were then driven to, and restored at, our new site. This allowed the migration of our largest databases while avoiding any network issues. The programmers could then test away. It took about 1 month to resolve security, linked server, batch job and online issues. We knew two months out from migration our new environment was functioning. The remaining task was to keep the new databases synchronized with production. For that task, I chose Red Gate Software's SQL Compare and Data Compare jobs. These Red Gate utilities allow batch scripts to run as Windows tasks to compare and synchronize schema and data. Whether the synchronizing jobs were hourly, daily or weekly was based upon the velocity of data change.
Identifying Velocity of Change
The critical step in database migration is to measure the velocity of change for each table in each database on each server. You must determine table change rate in order to set how often to synchronize. I accomplished this by running the T-SQL below for three consecutive months. This SQL relies on indexes so if your table is a heap you must issue a ‘count(*)’ instead.
-- Quick table row size for tables with indexes
USE Events
SELECT convert(varchar(40),object_name(id)) AS [Table Name]
, Rows
FROM sysindexes
WHERE object_name(id) NOT LIKE 'sys%'
AND indid = 1
ORDER BY 1 ASCI exported this every month into a spreadsheet resulting in the following row counts for my Events database just prior to the cutover in mid-October. The actual spreadsheet had 2516 tables grouped by database.
SQL TABLE ROW COUNTS | |||||
SQLSrv1 EventDatabase | April | May | June | ||
Table Name | Rows | Rows | Rows | (June-Apr) | Avg (June-Apr) |
Burning Man | 2,947,213 | 3,573,201 | 4,376,842 | 1,429,629 | 1,5710 |
Concerts | 51,864,829 | 63,542,179 | 81,083,754 | 29,218,925 | 321,087 |
LandsEnd | 123,876 | 276,549 | 303,789 | 179,913 | 1,977 |
Napa Valley Summer | 21,789 | 81,090 | 121,980 | 100,191 | 1,101 |
Stagecoach | 216,532 | 313,987 | 517,890 | 301,358 | 3,312 |
WoodStock | 31,965,376 | 31,965,376 | 31,965,376 | 0 | 0 |
Tables with no data change rate, as in Woodstock, did not require synchronization. Tables with a low data change rate, like Napa Valley Summer, would be synchronized via RedGate Data Compare weekly scripts. Tables with moderate data change rates, such as Burning Man, would be synchronized with daily scripts, and tables with high data change rates, such as Concerts, would be synchronized hourly.
The sheer amount of data in my production center, 8TB in total, made cutover day restores impossible for more than a handful of databases. I needed to get as much of the data synchronized on the new environment as possible, so the cutover restores would be brief.
For schema changes I chose Redgate SQL Compare and opted to synchronize high velocity tables/databases every week. All other databases were schema synchronized monthly. I highly recommend a code freeze at least two weeks prior to the migration so you do not have to deal with schema changes at cutover.
A greatly simplified data migration plan looked like this:
Event | April | May | June | Cutover |
Backup/Restore All DBs | Y | — | — | — |
Tables not changing | Done | — | — | — |
Low change rate | Weekly | Weekly | Weekly | Final |
Moderate change rate | Daily | Daily | Daily | Final |
High change rate | Hourly | Hourly | Hourly | Restore |
The Migration
Data velocity analysis showed that 31% of the tables had little or no change, and the initial restore in April was sufficient. I was a third of the way done after April’s database restores. The same analysis showed that 38% of the data changed at a low rate, so a final weekly synch was sufficient. At this point I was 69% done. 18 percent of data changed, a moderate rate, so the final daily synch was sufficient. Now I was 87% done. The last 13% of data changed so fast that only a backup and TLOG restore would work.
I called for a testing and production code freeze two weeks out from cutover. Two weeks prior to cutover I stopped the schema synch jobs they were no longer needed. One week prior to cutover I backed up the 13% of the data that changed fast and restored it in recovering status. Differentials or TLOGs backups were applied as they became available. Since the database were recovering no more testing was allowed. On cutover day I was only as far behind as the last TLOG backup. I needed to draft deputy DBAs to run the TLOG restores in parallel.
If the migration had been delayed, there would be no problems as we could just keep restoring the differential and tlog backups.
At midnight on cutover day, we paused the web front-ends to stop any data changes on our production site, waited 15 minutes, and then copied the last TLOG backups over the network to our new environment. These were restored with recovery. Since these were TLOGS from late at night, they were small and quick to transmit. Most of the databases were up within minutes, but of course, there were unexpected issues and some of the TLOGS didn’t apply as planned. However, within a few hours we were completely up and running.
Post migration we had to restore some missing data, broken security and batch jobs that failed with the new environment, but all-in-all the business was only down a few hours late at night.
Schema Compare Scripts
Here is how the Schema Compare scripts were coded. I used Red Gate Software's SQL Compare and found it required some experimenting to be efficient for our environment. I will save you some time and describe the technique that worked. Compare starts with a main panel where you fill in server and database names. I found the IP addresses worked consistently, so I used them instead of creating hostnames.
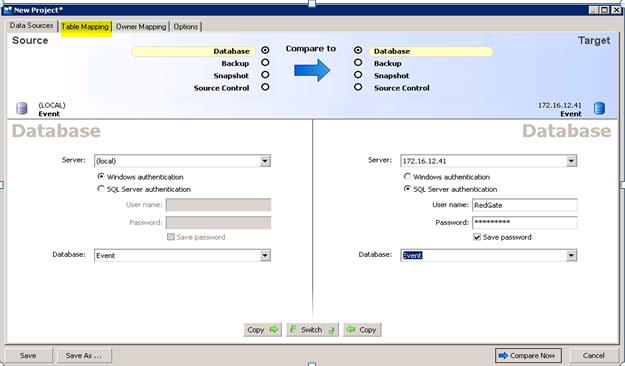
Next click the Table Mapping tab.
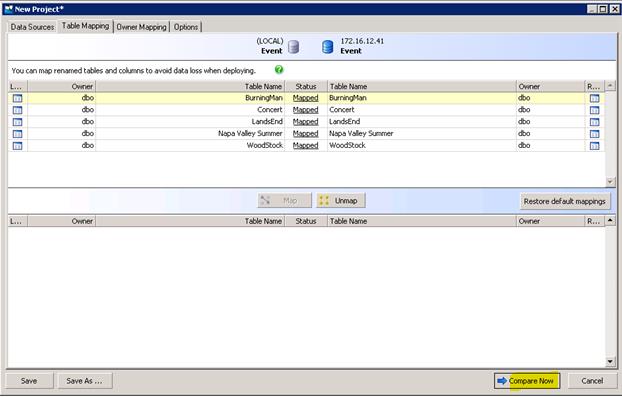
Check out the Option tab there are worthwhile features there. When this is set the way you need it, click Compare Now.
Click OK and you get a report.
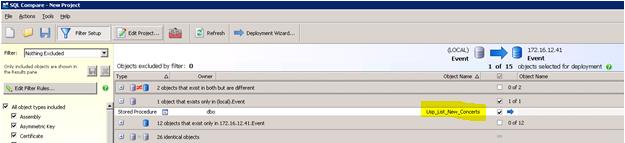
Notice the object that exists only in the (local) Event database. This is a new Stored Procedure we want synchronized. Click the check box to include it, leaving all other check boxes empty. Next click Deployment Wizard.
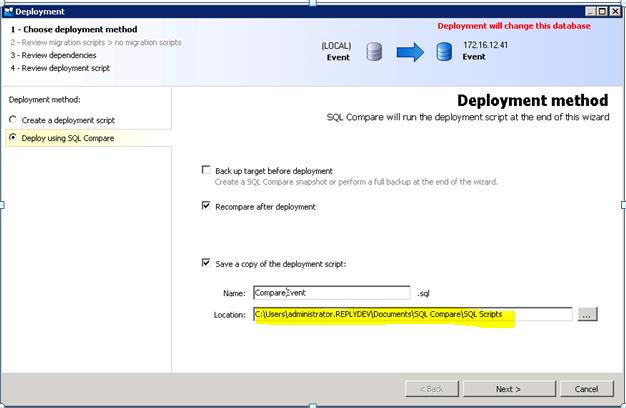
I found it best to rename to Compare<DatabaseName> so compare scripts are easily identified. Be sure to remove embedded spaces. Remember the location above it is needed in the Windows task scheduling setup. Click Deploy using SQL Compare unless you have an issue and need to debug. Click Next.
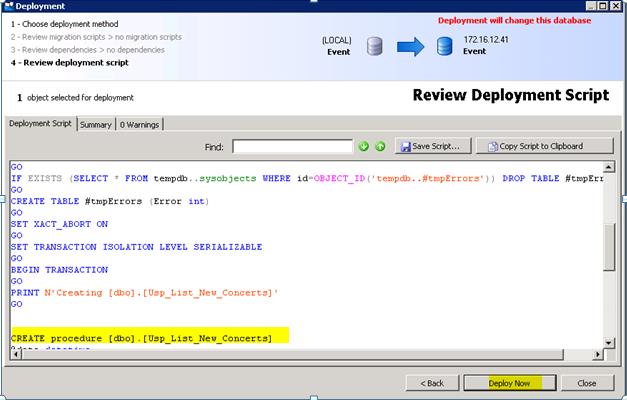
You won’t be reviewing these scripts once the synchronizing job is running unless you have an issue, notice the new stored procedure. Click Deploy Now
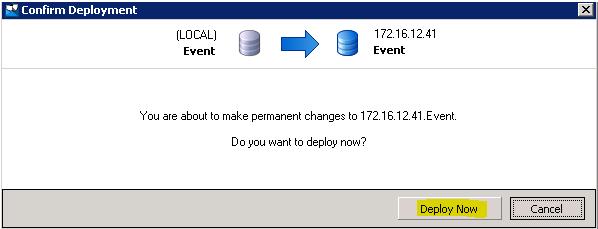
Click Deploy Now. A successful panel will appear (hopefully) then File Save As.
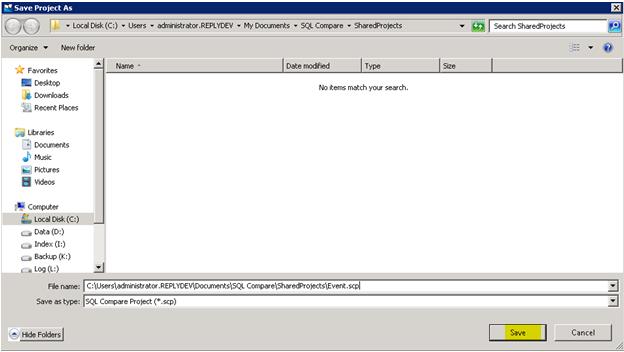
Rename the script to <databasename> to avoid a default name with spaces as it can cause issues in the job scheduling. Click save. Congratulations you’ve synchronized one database. Now, no matter what the testers do to the new environment, this script will synchronize to production. We only need to schema synchronize those database with changes that will not be restored at migration, as restore brings all the stored procedures anyways.
This script is now placed into a Windows schedule task to be run on a weekly, monthly or on demand basis as needed. I step thru Windows task creation in a separate part II article. On to Data Compare.
Data Compare Scripts
No surprise, the Data Compare script creation process is similar. Data Compare starts in the usual way, and once on the main panel, fill in server and database name. I found the IP addresses worked consistently, so I used them instead of creating hostnames.
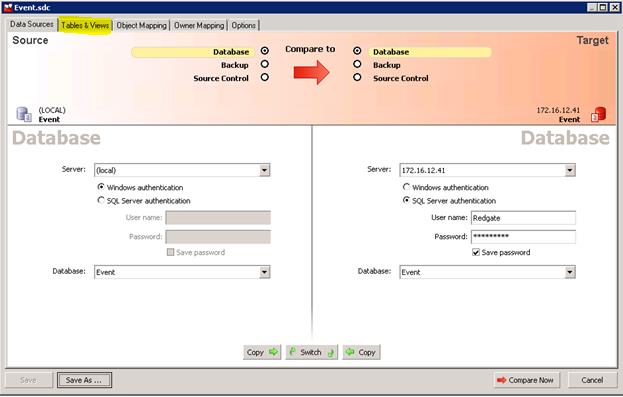
Save this project as <databasename> to avoid issues on the Windows batch job execution and to better group the scripts. Click Table & Views.
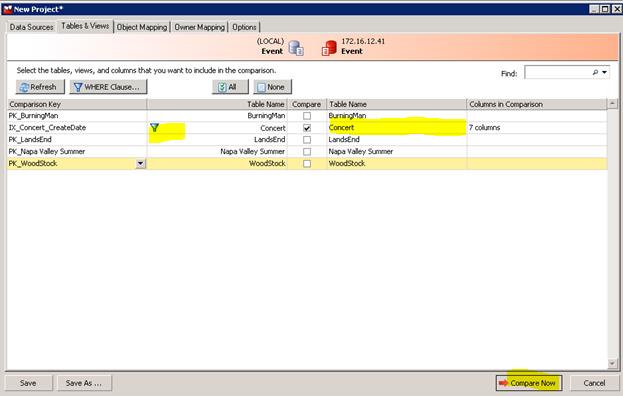
Since we are only interested is synchronizing busy tables with this script, select only the Concert table. The Comparison key by default is the primary index, and there is a drop down that lets you compare by index or column. Any table more than 1 million rows should use a unique index. If there isn’t a unique index this is a good time to create one.
To greatly improve script performance, right click the table name and select "where clause". Then enter the column expression. I find that date columns works great if they are indexed, highly recommend creating any needed indexes. For daily jobs, I used createdate > getdate()-1 (24 hours) as this really speeds the compare along. For one hour I used createdate > getdate()–0.042 (1 hour).
Always right click the table name to set the where clause, otherwise you’ll get the last where clause entered, which is quite annoying. For example, if the last where clause entered on any table was ‘createdate > getdate()-1’ and you previously entered ‘createdate > getdate()-0.42’ on the current table, Redgate shows ‘createdate > getdate()-1’. You enter a value and Redgate resets it. After a while you learn to right click the table name to see its where clause. Column names are show in Columns in Comparison which is quite handy.
Click Compare Now. Hopefully you’ll get a successful compare and the result will look like this.

Only the 1 table is compared and indeed it found 1 row needing to be synchronized. Select Deployment Wizard. Uncheck Recompare after deployment if you want to avoid a post compare.
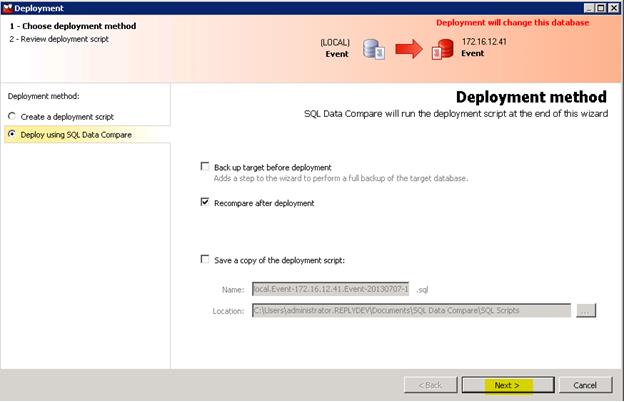
Click Next then Deploy Now twice. Hopefully a successful prompt shows.
Save as <databasename> and remove the spaces in the name. Remember this filename for the Windows task job.
In a like manner you can keep any table in synch with production until the migration moment. In my case I only had to synchronize 19 of 138 databases with Data Compare. All the other databases either didn’t require synchronization or were backed up and restored during migration.
In part II I’ll explain how to embed these Redgate scripts into Windows Scheduled Tasks based upon the above velocity of data change.
Reviewed by Reply.com’s IT manager Paul Bush.
