

Series Overview
This series of articles looks at how the optimizer builds up an executable query plan using rules. To illustrate the process performed by the optimizer, we'll configure it to produce incrementally better plans by progressively applying its internal exploration rules. You can read Part 1 and Part 2 of this series to understand how a plan is constructed.
Part Three - Identifying the Rules
In order to fully explore the way the query optimizer uses its rules to construct plan alternatives, we will need a way to identify the rules used in optimizing a particular query.
SQL Server 2005 (later builds only) and SQL Server 2008 include an undocumented Dynamic Management View (DMV) that shows information about the internal rules used by the optimizer. By taking a snapshot of that information before running a test query, and comparing it with the post-query DMV data, we can deduce the rules invoked by the optimizer for that query.
Before we get to the DMV itself, we need to nail down a few more things about the internals of the SQL Server query optimiser. The next section builds on the 'trees and rules' information given in Part 1 of this series.
The Optimization Process
Query optimization is a recursive process that starts at the root of the logical operator tree, and ends with a physical representation suitable for execution. The space of possible plans is explored by applying rules which result in a logical transformation of some part of the current plan, or a conversion to a physical implementation.
The optimizer does not try to match every available rule to every part of every query, in every possible combination. That sort of exhaustive approach would guarantee the best plan possible, but you would not like the compilation times, or the memory usage!
To find a good plan quickly, the optimizer uses a number of techniques, two of which are immediately relevant to the DMV:
- Every operator in the logical tree contains code to describe all the rules that are capable of matching with it. This saves the optimizer from trying rules which have no chance of producing a lower-cost plan.
- Every rule contains code to compute a value to indicate how promising the rule is (in context). A rule has a higher promise value if it has a high potential to reduce the cost of the overall plan. In general, commonly-used optimisations (like pushing a predicate) have a high promise value. More specialised rules, like those that match indexed views have a lower promise value.
When faced with several possible rule choices, the optimizer uses promise values as part of a pruning strategy. This helps reduce compilation time, while still pursuing the most promising transformations.
The sys.dm_exec_query_transformation_stats DMV
This DMV contains one row for each rule, with the following columns:
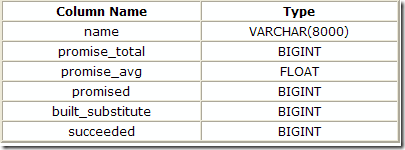
The name column contains the internal name for the rule. An example is 'JNtoSM' - an implementation rule to transform a logical inner join to a physical sort-merge join operator.
The promised column shows how many times the rule has been asked to provide a promise value to the optimizer.
The promise_total column is a simple sum of all the promise values returned.
The promise_avg column is just promise_total divided by promise.
The built_substitute column tracks how many times the rule has produced an alternative implementation.
The succeeded column tracks the number of times that a rule generated an transformation that was successfully added to the space of valid alternative strategies. Not all transformations that result in an alternative will match the specific requirements of the current query plan (for example, the alternative may not preserve a required sort order, or some other necessary property).
Using the DMV
The scripts included here were tested on SQL Server x86 Developer Edition, versions 10.0.2775 (2008 SP1 CU8) and 9.0.4294 (2005 SP3 CU9). This DMV may not be available on all builds of SQL Server 2005.
Since the DMV contains instance-scoped optimizer information, for correct results you will need to ensure that no other concurrent optimisation activity is occurring on the test server. Working on a personal test SQL Server and ensuring yours is the only active connection is a good place to start with that.
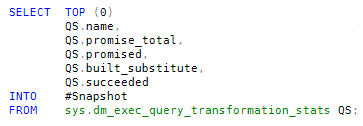
First, we need to create the structure of a temporary table to hold our snapshot of the DMV contents prior to running our test query:
Now we can write a batch to capture a DMV snapshot, run our test query, and show the DMV differences afterward:
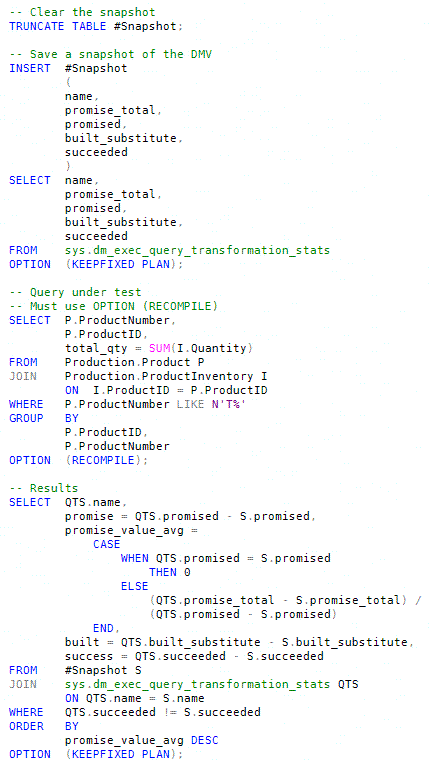
The query to test must have the OPTION (RECOMPILE) query hint added to ensure that a fresh optimization occurs. Other queries in the batch have OPTION (KEEPFIXED PLAN) to help avoid compilations that would skew the results.
The example above uses the AdventureWorks query we have been using in this series so far. It produces the familiar, fully-optimised, plan:
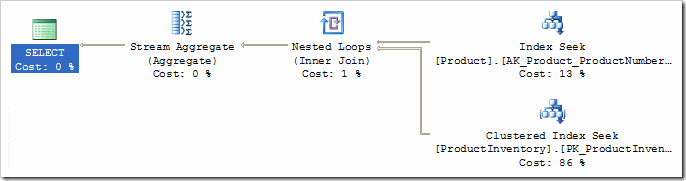
Here are the (partial) results from a typical run:
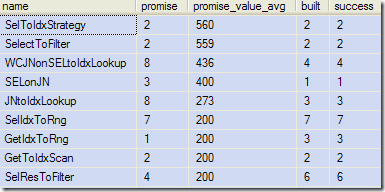
The output shows the rule name, the number of times a promise value was calculated, the average promise values produced, the number of times a transformed structure was built, and the number of times the new structure was successfully added to the optimizer's list of valid plan choices.
Notice that rules can be invoked multiple times, since they may match more than one place in the query, and the compilation process is a recursive one. You might also see rules with a promise value of zero, which simply means the promise-calculating code did not have enough information to produce a value.
Next Time
Now that we have found a way to identify the rules used to optimize a given query, we can move on to the really fun stuff. In the final part of the series, I will show two ways to affect the rules available to the optimizer, and present code to reproduce the 'interesting' partially-optimised query plans shown in Part One.
Paul White
Twitter: @PaulWhiteNZ
Email: SQLkiwi@gmail.com
Blog: SQLblog.com
