
When working with a distributed version control system (DVCS), each user in the team has a local repository. A user can make many small commits to their local repository, and then "publish" them all to a peer repository in one go, once debugging and testing is complete. This avoids potential disruption to the work of others while still offering each user the full benefit of a VCS.
They can pull others' changes, update their working folder, perform a merge if necessary, commit again, and then push their changes.
This level starts with an overview of how versioning works in Git, a DVCS, and suggests a sensible database project versioning strategy. It then offers some simple, but illustrative, practical examples showing how to share database changes and deal gracefully with any conflicting changes.
Versioning in Git
As we stand, the commit history in our repository (Figure 5-1 shows this as displayed in SourceTree) give us the comment, date and author of each commit, as in the centralized version control system. One difference however is that, as Git does not always know the sequence of commits, a unique hexadecimal number is used to identify the version of the code. As we will see later, it is possible to use tags to identify specific versions, and then the number of commits since the code was tagged, if you need an incrementing scheme which ties to your release versions).
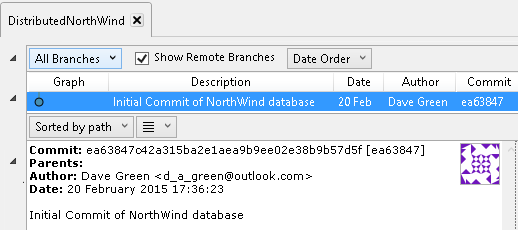
Figure 5-1
If you're using Git command line, or PoshGit, you can view the commit history using the git log command (see https://git-scm.com/book/ch2-3.html).
PS C:\Users\Username\source\repos\NorthWindDB> git log commit 5ea848494bcb105013871ad8cac5bb3b1a0dcb0a Author: Author <Name@emailaddress.com> Date: Mon Feb 01 14:30:06 2016 +0100 Initial Commit of NorthWind database
The alphanumeric string we see assigned to the commit, in this case the initial commit to version control of the NorthWind database, is what is known as a Git hash. A distributed VCS such as Git will assign a hash value to every commit (Git uses 40-character SHA1 hashes of the source tree, at the point of the commit).
Versioning in a distributed version control system, such as Git, works rather differently from what we saw for centralized VCS such as SVN. In the centralized model, the central repository maintains the full version history for every file. Versioning takes the form of global sequential revision numbers. SVN, for example, assigns a number to each changeset (committed revision), incrementing the number for each new revision. It is very easy to identify file versions at a specific point in time because the numbers increment sequentially.
The central server stores a series of "deltas" for each file describing the changes made to a file (or tree), which it can use to reassemble a particular file or tree at a particular version. It can do this because the centralized server knows that it is the authoritative source for every file; it controls all of the valid states of those files. This means the storage space required is quite small, but it does have some costs. Firstly, there is no one place to look for the current state of all objects, so as the repository gets larger, the number of "changes" to apply to the base state grows.
By contrast, in a distributed model, users commit changes to their local repositories and then push and pull changes with any other remote repository, and so a DVCS needs a mechanism to track changes across all files collectively, across multiple peer repositories, rather than on a file-by-file basis. Git needs to track all the states of the files, and so maintains full copies of those states. In this respect, it's easier to think of Git as storing a stream of snapshots, over time, of the files in a file system (although, of course, it's more complex and more highly optimized than that). Pushing changes from one repository to another essentially involves merging two 'snapshots'. Git performs a checksum, in the form of the Git hash, for every single change. It refers to each change by its hash value and can use these values to determine the exact differences between different 'snapshots' of a particular set of files.
This is why a DVCS will generally offer much stronger support for merging and can more often merge changes without any manual user intervention. However, it also makes simple, sequential versioning harder to achieve. For more detail on this, see Getting Started – Git Basics.
Sharing Changes during Development
Whilst we are working in our own repository, it is important that we adhere to the same best practices described in previous levels. In particular, we still commit code frequently, and we share (push) those changes up to the common remote repository (origin), to allow others to access them.
This frequent committing of small changes makes merging a simpler task, and identifies quickly any incompatible changes to the code so that they can be resolved whilst the code is still relatively fresh in the developers' minds.
In this manner, a team of developers can work concurrently on a database development project, committing new objects, and changes to existing objects to their local repo and then pushing them to the remote origin repository, from where others can pull the changes. Let's take a quick look at a simple example of this in action.
If you haven't worked through previous levels, we're going to simulate two developers working simultaneously on a project to upgrade the NorthWind database. You can either work form your preferred Git client (Level 4 shows how to set up PoshGit), or from Red Gate SQL Source Control (SoC). I'll use the latter (SoC v.4.1) for the examples, but the concepts remain the same, regardless.
To get started, you will need to:
- Create a new, empty remote repository called MyNorthWind (or similar) – This will be the 'origin'. Level 4 shows how to set up a remote repo using Visual Studio Online (VSO).
- On each of two separate clients, clone the remote MyNorthWind repo to a local directory – in this case, we clone to C:\Users\user.name\source\repos. You may need to establish new access tokens for VSO.
- On each client create a trunk folder as a subdirectory of the MyNorthWind repository folder, and then a database folder as a subdirectory of trunk.
On one of the clients, let's say developer1's machine, right-click the NorthWind database and proceed as follows:
- Choose: Link to my source Control system
- Select Git as the source control system
- Link to Git using C:\Users\user.name\source\repos\MyNorthWind\trunk\database
- On the Commit Changes tab, perform an initial Commit of the
NorthWinddatabase
If you navigate to the database subfolder in Windows Explorer, you'll see folders for the committed objects.
Figure 5-2
In this mode of operation, committing directly to the local repo, SQL Source Control will automatically commit locally all changes. If you are set up to save changes to a local working folder, then you'll need to stage and commit the changes to the local repo from your Git client, as described in Level 4.
However, if you check your remote repository, you'll see it is still empty, so we can perform a push to origin, from PoshGit, as shown in Figure 5-3.
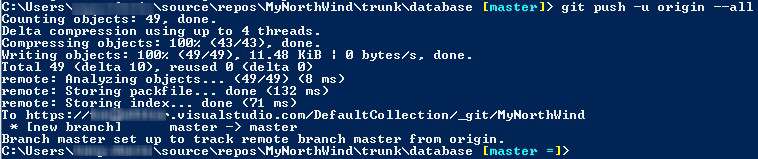
Figure 5-3
On developer2's machine, create an empty copy of the NorthWind database (using a CREATE script stored in the VCS, of course). In SOC, link to same directory as previous. Developer2 can now perform a Pull from the remote repository (i.e. from MyNorthWind), which will execute a git pull into his local repository, so it will refresh both database files and any other source controlled files (for example, if application code shares the repository that will also be pulled). The results will be as shown in Figure 5-4.
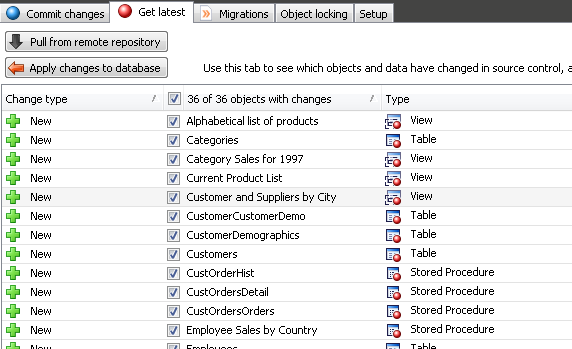
Figure 5-4
The Apply changes to database button will be enabled and he can then simply then apply the changes to his local database. This is analogous to the get latest operations in a centralized repository, and ensures that the developer is using the latest version of the code in the origin repository.
Let's say Developer2 adds a new email column to the Customers table, and then creates a new stored procedure for returning results from that table.
USE NorthWind
GO
ALTER TABLE dbo.Customers ADD email nvarchar(24) NULL;
GO
CREATE PROCEDURE dbo.SelectCustomers
AS
SET NOCOUNT ON;
SELECT CustomerID ,
CompanyName ,
ContactName ,
ContactTitle ,
Address ,
City ,
Region ,
PostalCode ,
Country ,
Phone ,
Fax ,
email
FROM dbo.Customers;
GOListing 5-1:
Within SSMS, he uses SQL Source control to commit those changes to his local working folder. If you check git status from the command line, at this stage, you will see something like as shown in Figure 5-5.

Figure 5-5
Two of the commits are the changes to the table and stored procedure. The third is a change to a configuration file used by SQL Source Control, updated to denote a change of default schema as my server is configured in a different collation (UK default) to that used by the NorthWind database (US default). This occurred because the database was created from the server's model database before the objects were cloned into it. You should be careful to ensure that such configuration issues don't plague your development with intermittent bugs by ensuring that all developers use standardized server settings – you can then test in alternative collations and configurations if required. There are implications for how you develop and what you need to test if you mix collations, but these are outside of the scope of this stairway; you won't find this change if you are using SQL Server Express LocalDB as your server.
Finally, Developer2 can push the changes to remote directly from SQL Source Control, or with git push -u origin –all from the command line.
After that, Developer1 can use Pull from remote repository | Apply changes to database (see Figure 5-5), or can use git pull origin to retrieve the changes to the local repo, from the command line, and then apply these changes to his sandbox database in SQL Source Control.
Dealing with Conflicting changes
Level 3 provided an example of developers working on the same branch simultaneously, making database changes, and how this leads to the need to merge those changes regularly, and deal with any conflicts that arise.
We saw that a centralized VCS such as SVN will "block" a user's attempt to commit a change from their working folder to the central repository if the change originated from what is now an invalid base version, in other words, if another user has changed that file in the meantime. Instead the VCS invites the blocked user to perform an update of their working folder, which incorporates a merge operation (auto or manual), before committing. Having established a "merged" version of the file, in the working folder, the user will typically have no history of the state of the file when attempting the initial commit, so if the merge goes wrong, the user risks losing work.
To avoid this possibility, users have to resort to manual versioning – often saving the files in the original commit with a "_old" suffix, or appending a date. This clutters up the working folder and may even be committed to the source control repository, resulting in confusion when change history needs to be worked out. In acute examples, it may result in extraneous and often wrong code being put into a production environment.
By contrast, intra-branch merging in a distributed VCS is safer, since each user has a local repository. In a DVCS, we can commit changes locally and then "pull" the latest changes from a remote repo and merge as necessary. The merge operation is safer in that it involves a local commit and a remote commit; we are in effect merging two committed versions of the repository to create a third commit that combines the two sets of changes.
This means that the changes are not lost, and it is easy to see the versions before they were merged – something you don't get with a centralized version control system. This is only possible because Git track all the states of the files, and so maintains full copies of those states and can find the best merge path. Git takes care of this automatically, and a side benefit is that because your changes are safely stored once you commit locally, they are not lost even if the merge goes wrong (barring loss of the entire local repository). We commit the merged version locally and finally push the merged version to the remote repository. If the merge fails, we can simply try it again.
Let's take a look at a simple example of developers working on the same Git branch simultaneously, making database changes that come into conflict. We'll imagine that our developers have realized that 24 characters is probably not enough for an email address, and so need to alter the column size.
Developer2 performs a "pull from remote repository", as described earlier, to ensure he has all the latest changes. He expands the email address field to hold 101 characters.
ALTER TABLE [dbo].[Customers] ALTER COLUMN email [nvarchar](101) NULL; GO
Listing 5-2
He commits the change to his local repository. Once this is complete, SoC will present him with an option to push that change to the remote repository.

Figure 5-6
However, he wants to perform some final testing first, and in the meantime, due to a communication breakdown, Developer1 has made a similar change, but she has changed the length of the field to 152 characters. He commits the change locally and then immediately pushes it to origin.
Meanwhile, Developer1 is now ready to push her change to the remote repo, Git will note that the last 'pull' was from an earlier revision than the current revision on the remote repository, and the message in figure 5.7 will be displayed.
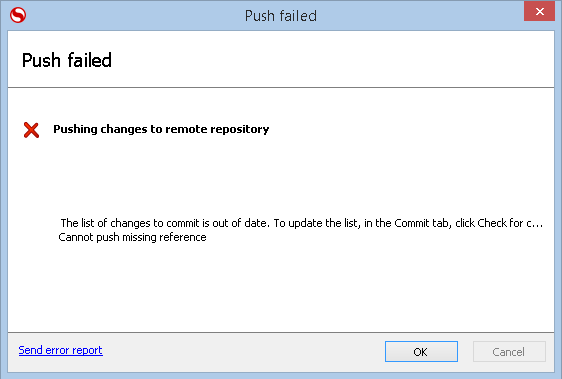
Figure 5.7
What Developer2 should have done, and what he must do now, is pull the latest changes from the remote repo and perform a merge locally. However, in SQL Source Control, he will be presented with the message that the conflicts need to be resolved outside of source control. This is because the changes are to the same file (representing the same database object) and cannot be automatically resolved by the software.
The easiest way to solve this is to pull the latest version of the repository in a git client such as Sourcetree. Figure 5.8 shows the conflicting code.
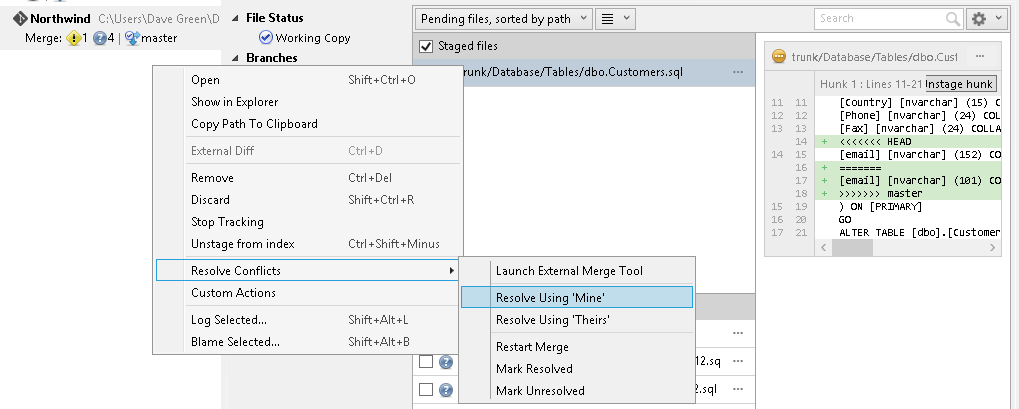
Figure 5-8
Developer2 then has the choice of right clicking on the file and selecting Resolve conflicts | Resolve Using 'Mine' (to use his own file) or 'Resolve Using 'Theirs' (to use the version in the origin repository and revert his changes to the file).
If the conflict is due to developers altering unrelated areas of the same database object (the more common case in my experience) then the developer can resolve using a third party merge tool. I use Tortoise SVN but the merge resolution process is similar in most merge tools. If using a command line client, such as PoshGit, you can use the command git mergetool to see a list of merge tools that are configured (you can explicitly configure PoshGit to use your preferred tool).
The merge tool will allow you to make specific edits so that the resulting file is syntactically correct, whilst using changes from both files involved in the merge.
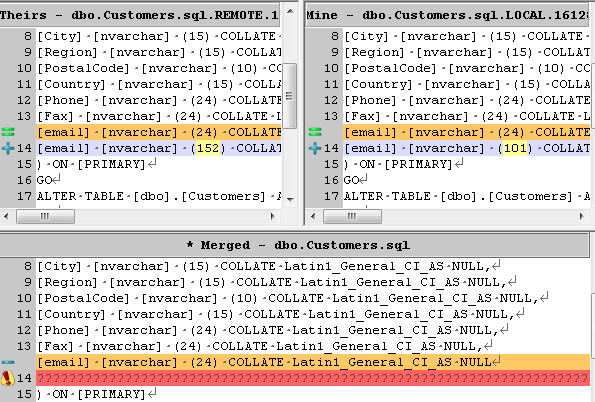
Figure 5-9
In this case, Developer2 has had a chat with Developer1, and they agree that actually the maximum length should be 150. So he can either resolve using one or other version then make a second commit, or he can Launch an External Merge tool, which will allow him to manually edit the merged file, using a text block from his commit. When he marks this as resolved in the merge tool, and quits, the Sourcetree screen then shows the file as staged.
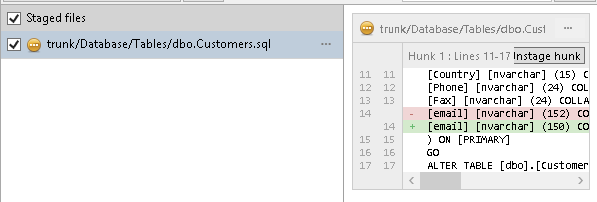
Figure 5-10
Developer2 can then click the Commit button (or the git commit command) to input a comment and commit the change, optionally pushing the change to the origin/master immediately.
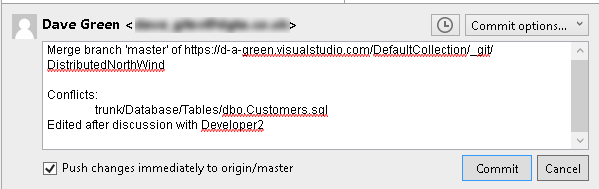
Figure 5-11
Developer1 can then pull from the remote repository to update her local repo with the agreed change.
In SourceTree, we can see the merges and splits in the code in the graphical diagram which then results (Figure 5-12), but more importantly we can actually see all of the commits, even those that were not actually kept after the merge.
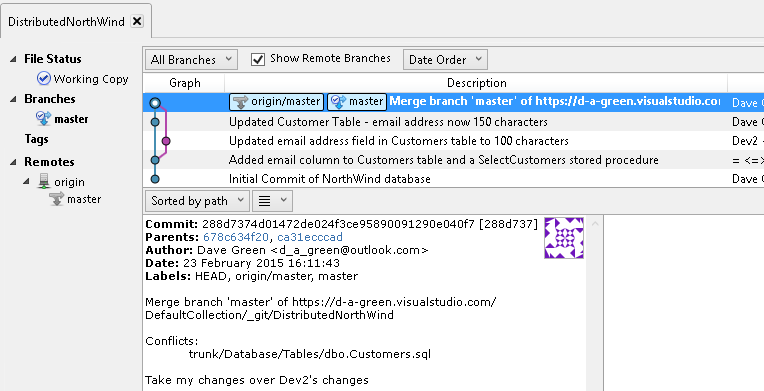
Figure 5-12
We can also see in figure 5-12 the abbreviated hashes of the parent commits (in this case, 678c634f20 and ca31ecccad, both of which manifest in SourceTree as a link to the commit in question. It's this link in a commit to a parent commit that allows Git to assemble the history of commits, as individual commits may have been done in another copy of the repository and pushed into this repository.
This means that we retain a fuller audit trail than with our centralized VCS (SVN) as that prevented us from saving to version control a change which would conflict, meaning that the change would be lost unless we resorted to "manual versioning". This is an important difference, and together with the disconnected nature of such systems, allowing a level of fault tolerance, is a large reason why distributed source control systems are becoming ever more popular.
In this example, the conflict arose because two developers made changes to the same file i.e. to to the same database object (indicating a dependency between those workflows). This makes for a more troublesome merge process, which could be avoided if independent changes to the same object can be planned so that they are not done at the same time, but can still be resolved when it does occur, as seen above.
Let's run through what would have happened, had the changes been made to different database objects.
Developer1 alters the table dbo.Customers to change the length of the email column in her copy of the database.
ALTER TABLE dbo.Customers ALTER COLUMN email NVARCHAR(200)
She then commits this to the repository (Figure 5-13) and is offered the opportunity to push her changes up to the origin repository, which she does.
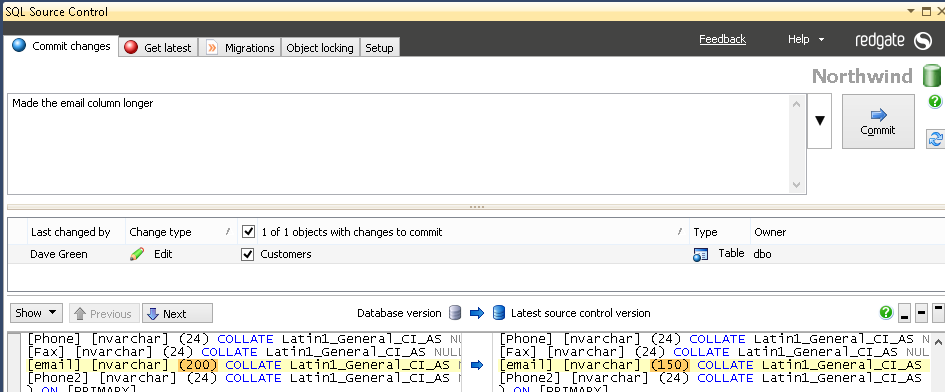
Figure 5-13
Whilst she is doing this, our Developer2 alters the stored procedure dbo.SelectCustomers to add the new field Phone2 to the resultset returned (Figure 5-14) and is also offered the chance to push changes to the repository.
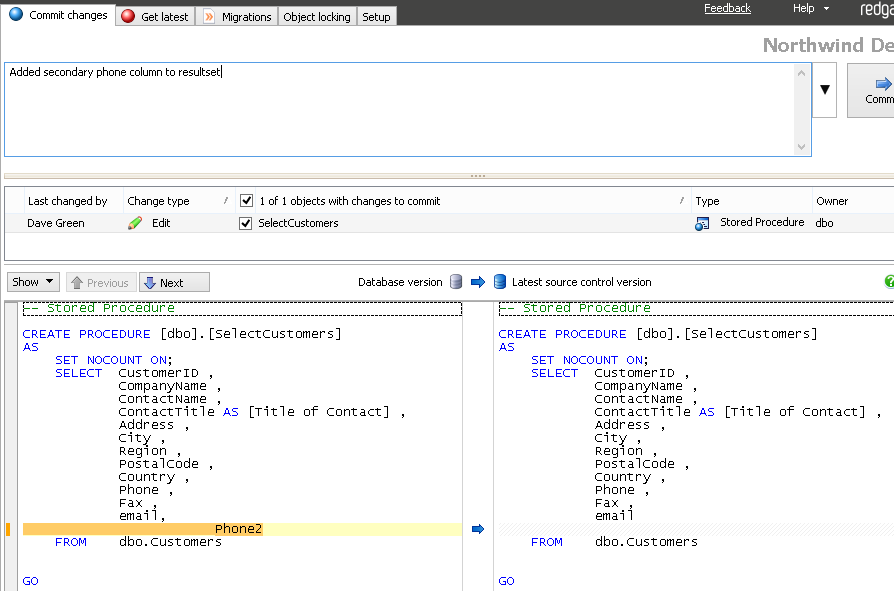
Figure 5-14
When he does so, he gets the error in Figure 5-7. So in this case, he needs to go to Get Latest and pull the new changes down, then apply these to his database before then running any unit tests and) pushing up the change he made. Note that he is actually asked to push up two changes (Figure 5-15), being the commit that he had made, and the addition of the commit to merge in the first Developer1's changes.

Figure 5-15
This simplified merge method is by far the more common scenario, and although slightly repetitive does allow the merged code to be tested, and the history retained. This can be very helpful when later trying to understand why a change was made, and in what context.

Figure 5-16
Marking releases
Sooner or later, the aim of writing code is to release it. When you release code, it's helpful to mark that code release in source control, so that later patching of any bugs can be done easily. You can do this by tagging a release. There are actually two types of tag in Git – a lightweight one which only stores a name, and the fuller tag process that stores who did it, when, and a message (and optionally, a signing key). It's the fuller version you want to use when tagging releases, as lightweight tags are designed for your use only, and some Git commands ignore them, which can cause problems if you are using tags to numerically mark releases.
To tag our release code as V1, we use the command in Listing 5-3
git tag -a -m "Tagging release version" V1
Listing 5-3
If we do this, then commit the tag, we will see that any future commits can be referenced as specific releases by running git describe (which will return as its first result the current position of the repository):
git describe V1-2-g32c895f
The version returned, V1-2-g32c895, tells us the last named tag was V1, this is the second commit since that tag, and it has a short hash value of 32c895 (the g meaning it is a git commit). You can mark point releases in this way too, such as V1.0.4. In this way we can later find the exact code for a released version if we need to refer back to it.
Working practices to minimize conflict and merges
Most development teams will have established working practices which suit how they work, but it might still be helpful to outline here some principals that, in my experience, can minimize the impact of version control on database development, and therefore increase the return on investment whilst lowering the barriers to adoption of new working practices.
Establish clear workflows for each team member
If several developers work on the same branch, establish workflows that minimize the potential for "interference". This up-front planning can, if done properly, mean that developers can work at their own pace, and if within an Agile process, minimize the impact of no longer continuing with a specific piece of functionality by allowing easy identification of changes relating to that function.
Update your local repository often
Regularly pull from origin to make sure you've got the very latest revision of the repository, dealing with any merges locally before pushing your own changes.
The typical day to day work-flow for a developer would be to pull changes down from the repository, do work on a requirement and then push back to share his changes. By pushing and pulling frequently you minimize conflicts and allow your colleagues to work most effectively (as they do not have to resolve as many conflicts).
Commit, test, push, and integrate in frequent small steps
Make the smallest logical change, run tests locally, and then push regularly to the remote repository to share your changes with others (thus your change can be with your team before someone else makes a change). Because you test quickly, the number of changes made since the last successful test is small, which makes identification of any areas of code which fail tests that much easier, and therefore makes the resolution of those failures easier.
It is helpful to have a continuous integration engine trigger a run of all your unit tests on your database on every commit, or at least on a periodic basis. This, in addition to running tests before you commit your code, acts as a way of ensuring your commit hasn't accidentally broken the code, and is doing what it should be. I have previously written about how to implement such a system for databases.
It is particularly important after merging conflicting changes to run appropriate testing on your code. Often this is the job of a continuous integration system, but it is good practice to build and run some automated tests on your code before you push up to others, as this minimizes the effect that a bad merge, which caused a compilation issue, would have. Given that you cannot control when a developer will pull down from the remote (origin) repository, it is sensible to ensure that that repository is kept working at all times.
Standardize development practices
Put in place standard working practices, such as configuring a standard SQL server setup, and putting in place development standards (such as naming conventions, rules for when code should be modularized and shared, and conventions on how to select data types and schemas) will allow code written by one developer to be more easily run, understood and extended by other developers. This can help you avoid trouble caused by common bad practices such as stored procedures that insert data into tables without properly referencing the column name.
Clear working practices will allow easier collaboration and so help to avoid situations where a sole developer becomes the de facto expert on a particular subsystem.
Create short-lived branches as required
Sometimes you want to work on a series of changes, which if shared could disrupt others' work. For this purpose we use branches, which allow a series of commits to be developed outside of the main trunk code, but still shared and worked on by others, perhaps in a specialist team, and synchronized to the remote repository.
We're not going to cover branching and merging of branches in this stairway, but it is worth noting the same principles apply as with merging up to the main repository, and these can clearly help where there is a need to work on a specific feature which may or may not be incorporated, or needs to be trialed first. It can also help when working on a modification which will break functionality whilst it is being made, as this allows changes to still be committed without breaking the rest of the build.
We saw that, when working in the main branch, if you are not synchronizing with the origin repository regularly, then your code gets further away from the origin repository, which makes the merging of your code back in all the more painful. The same applies when working on a branch – and so it is good practice to periodically bring in changes from the main line into your branch, to minimize the drift, and resulting merge pain. It also means that, once the need for the separate branch is over (or the code can be safely merged back in), it saves time in the longer term to merge code back to the main line to avoid the code becoming so out of line that the prospect of merging the code becomes the limiting factor.
Summary
This level marks the conclusion of this short stairway on the basics of version control for SQL Server databases. To recap briefly, we've covered:
- Level 1: Setting Up For Database Source Control –why we need to version control database, challenges, plus basic set up of the repository and source control clients
- Level 2: Getting a Database into Source Control – getting a database into SVN, either manually or using a schema comparison tool
- Level 3: Working with Others (Centralized Repository) – team-based database development using SVN, covering the basics commit and updates, plus conflict resolution
- Level 4: Getting a Database into Source Control (Distributed Repository) – how distributed repos work, how to get a database into Git
- Level 5: Working with Others (Distributed Repository) – this level covered team-based database development using SVN, describing the basics of commit, push, pull operations and conflict resolution
We have looked at the reasons to source control your databases, looked at the different types of source control system – centralized and distributed – and worked through some typical developer workflows to show how they are used in practice. We've explored some typical database modifications using both SVN and Git version control systems. We have seen how simple operations can be done without leaving SQL Server Management Studio, and that more complex merges can be done with external tools. We have also looked at working practice changes that minimize conflict, as well as the need to perform complex merges, and how to mark releases to allow us to find the exact source code for a specific release.
I hope this stairway serves to get you started with putting your databases into source control. You may want to look to continuous integration, or unit testing, as possible next steps to improve your database development workflow.
