

The objective here is to demonstrate how to effectively use SSIS Scripting to accomplish Fuzzy Matching and Fuzzy Grouping . I have worked in this area for many years and this is by no means a complete solution suitable for very high volumes, however this article will provide a workable SSIS solution for matching and grouping required for de duplication. In addition we will demonstrate how to acquire a source connection in a Script component.
Some examples of using SSIS Fuzzy Lookup are at SSIS: Adventures with Fuzzy Matching and Fuzzy Lookup and Fuzzy Grouping in SQL Server Integration Services 2005
The Problem
Let's assume you have a list of prospective customers and you want to identify which ones are the same. However the list of prospective customers has some duplicate due to misspelling and or typos. Notice below cust_id 11 and 111 are probably the same person.
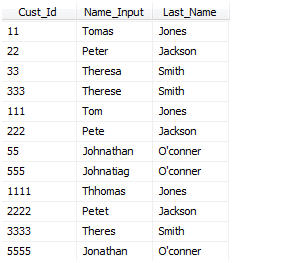
As you can see from the list above we have a list of Customer Ids and First and Last names. For our exercise the last names are assumed to be correct. Our objective is to group or match the unique Cust_Id records. We want to create an output list that links the similar customers and also normalizes or standardizes the first names.
I like to start with the end in mind and below is our final output.
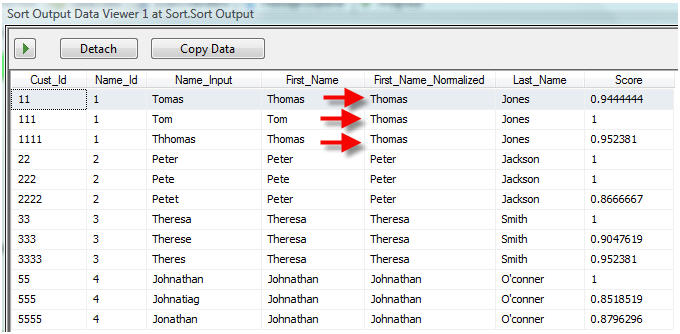
We have cleansed (First_Name_Normalized) and grouped (Name_Id) similar customers. In this example for the customer Jones with three different first names Tomas, Tom and Thhomas we have normalized the first name as Thomas. Our next step would be to do a Merge/Purge and create a single customer records, we will examine this in a future article.
The Approach
Create a process which will compare the customer Name_Input list to a Lookup table with existing Standard first_Names , identify the similar first names and group them by assigning a Name_Id. separate lists into a new list containing and identifying the matches. In addition we will standardize the name. For instance we will make Tom and Tomas into Thomas or Pete into Peter.
This article will describe how to create a SSIS Package that will provide Fuzzy Matching via a SSIS Data Flow Script Component.
SSIS Fuzzy Matching and Fuzzy Grouping stock components are provided for the SQL Server Enterprise Edition and are not available in SQL Server Standard Edition.
We will develop a SSIS Package that will support both Fuzzy Matching and Fuzzy Grouping and can run in any SQL Server Edition that supports SSIS. Our initial version will perform adequately for medium volumes.
Specifically we will demonstrate how to implement the Jaro-Winkler Matching Algorithm .
“The Jaro-Winkler distance (Winkler, 1999) is a measure of similarity between two strings. It is a variant ofthe Jaro distance metric (Jaro, 1989, 1995) and mainly used in the area of record linkage (duplicatedetection). The higher the Jaro-Winkler distance for two strings is, the more similar the strings are. The Jaro-Winkler distance metric is designed and best suited for short strings such as person names. The score isnormalized such that 0 equates to no similarity and 1 is an exact match.”
The references used for this effort were:
- Dev Shed Forums Jaro -Winkler Matching Algorithm
- Using the SSIS transformation script component in an ETL
This is not a tutorial on SSIS, we assume you know how to create a package and distinguish between a Control and a Data Flow. If you need a primer see The New ETL Paradigm by Jamie Thomson or review Speak like a SSIS Developer at JumpStartTV by Brian Knight.
The way it works
Basically we will read all the rows(NameInput) from an input dataet and compare each row (FirstName) in a lookup or reference table(NameLookup).
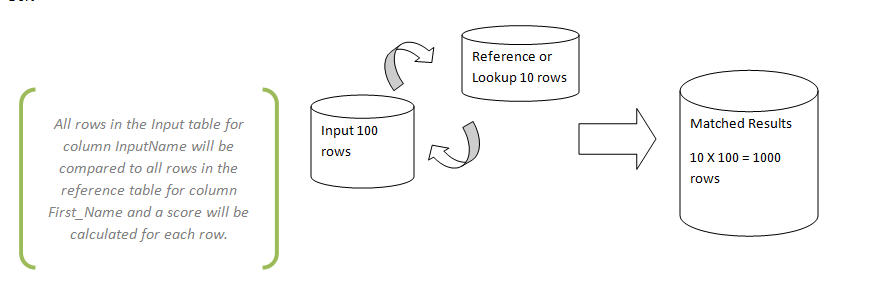
Obviously this process will create a large volumn of rows, we will split the rows into three categories.
Matches with Scores over 95%
Near Matches with Scores over 75% and under 85%
No Match with Scores under 75%
One advantage we have in implementing this in SSIS is the "Pipeline", The records will be created in the "Pipeline" and will not have to be staged or written to a file.
Pipeline architectureas defined by Microsoft
"At the core of SSIS is the data transformation pipeline. This pipeline has a buffer-oriented architecturethat is extremely fast at manipulating rowsets of data once they have been loaded into memory. The approach is to perform all data transformation steps of the ETL process in a single operation without staging data, although specific transformation or operational requirements, or indeed hardware may be a hindrance. Nevertheless, for maximum performance, the architecture avoids staging. Even copying the data in memory is avoided as far as possible. This is in contrast to traditional ETL tools, which often require staging at almost every step of the warehousing and integration process. The ability to manipulate data without staging extends beyond traditional relational and flat file data andbeyond traditional ETL transformation capabilities. With SSIS, all types of data (structured, unstructured, XML, etc.) are converted to a tabular (columns and rows) structure before being loaded into its buffers. Any data operation that can be applied to tabular data can be applied to the data at anystep in the data-flow pipeline. This means that a single data-flow pipeline can integrate diverse sources of data and perform arbitrarily complex operations on these data without having to stage the data.
It should also be noted though, that if staging is required for business or operational reasons, SSIS hasgood support for these implementations as well.
This architecture allows SSIS to be used in a variety of data integration scenarios, ranging fromtraditional DW-oriented ETL to nontraditional information integration technologies."
The SSIS Solution
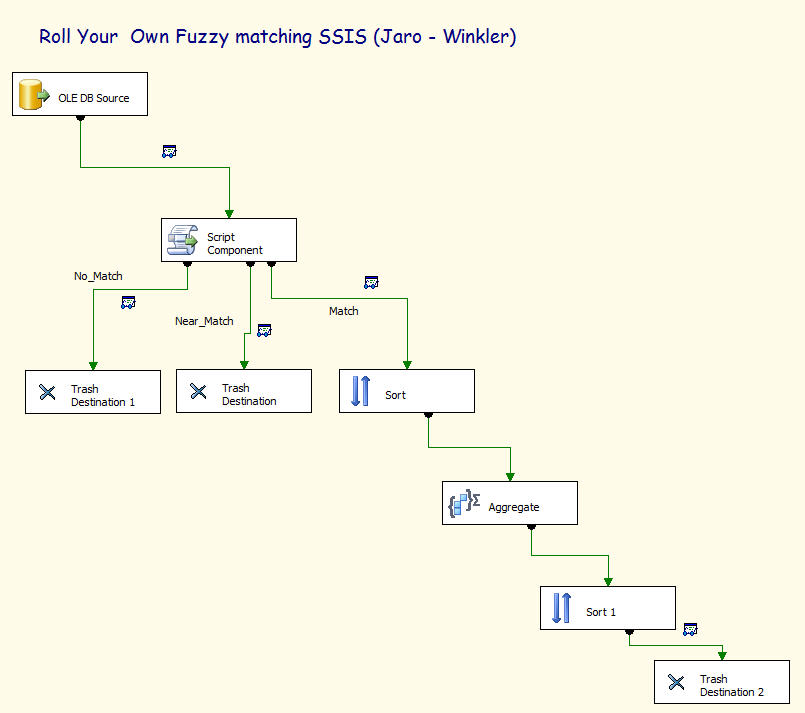
The Data Flow Toolbox items we will use once we have created a Data Flow in a Package are:
- Create OLE DB Source
- Script Component
- Trash Destination (Available from Konesans)
- Sort
- Aggregate
Create OLD DB Source
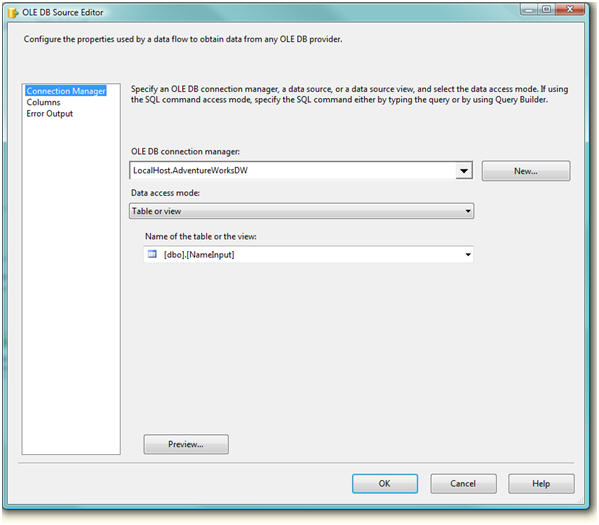
I have provided a script to load the NameInput and NameLookup sample tables for our package. Incidently I used a SQL Server Central script from Tatsu to generate the Insert Scripts.
Set up Script Component

Add a Script Component and select all columns as input.
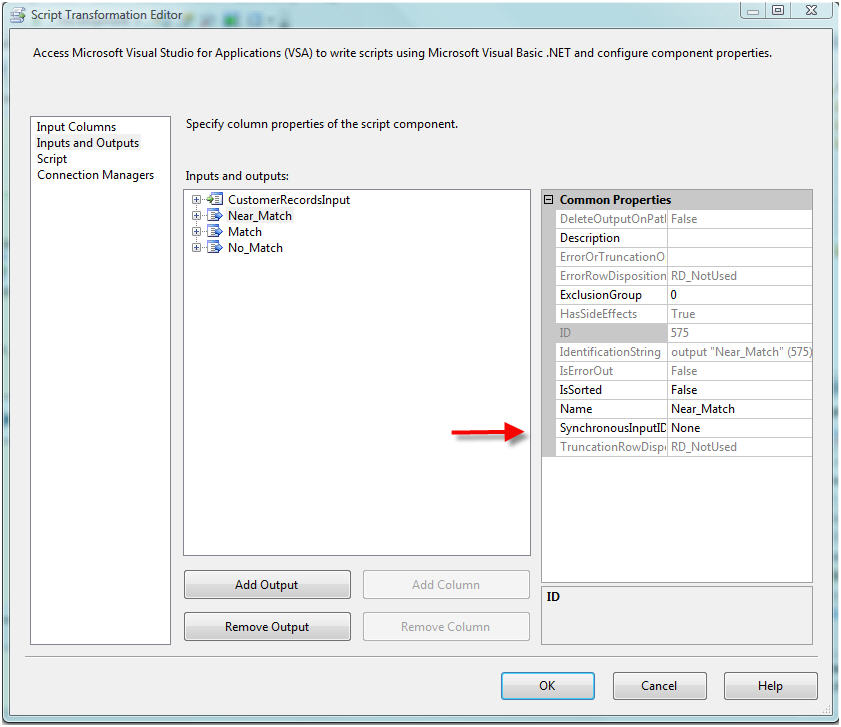
Create three outputs:
- Match
- Near Match
- No Match
Set the SyncronousInputID to "None" for each output. This will make the Script Component asynchronous.
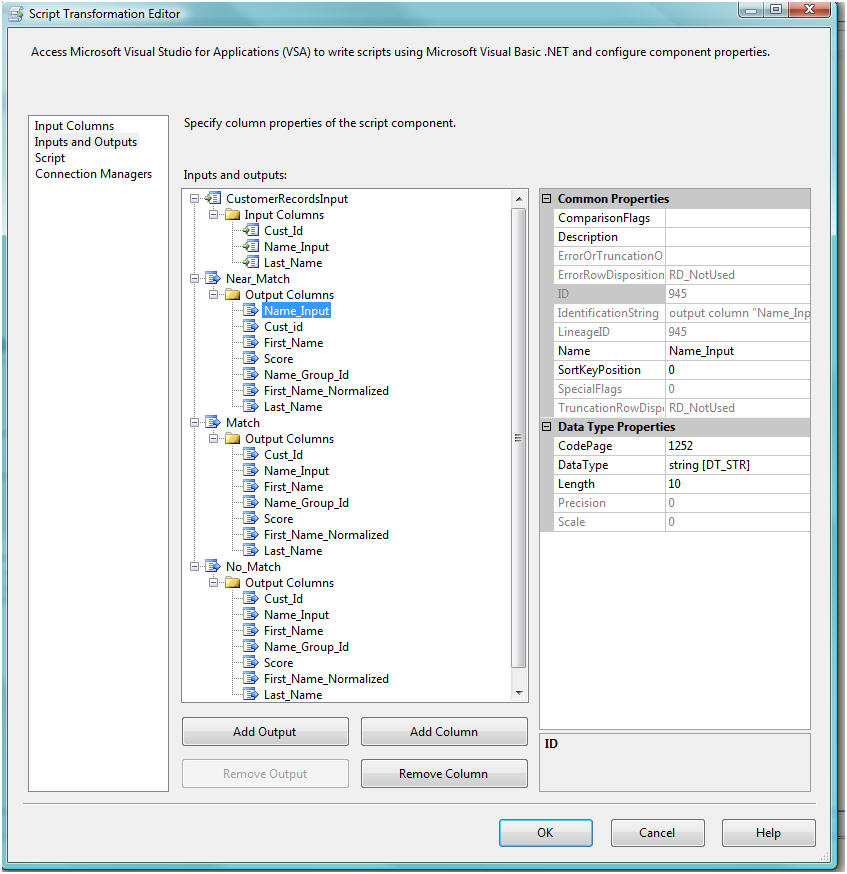
Next create the necessary Outputs and their associated columns , all of them as DT_STR length of 10.
- NameInput
- LastName
- FirstNameNormalized
- FirstName
- NameGroupId
- Score
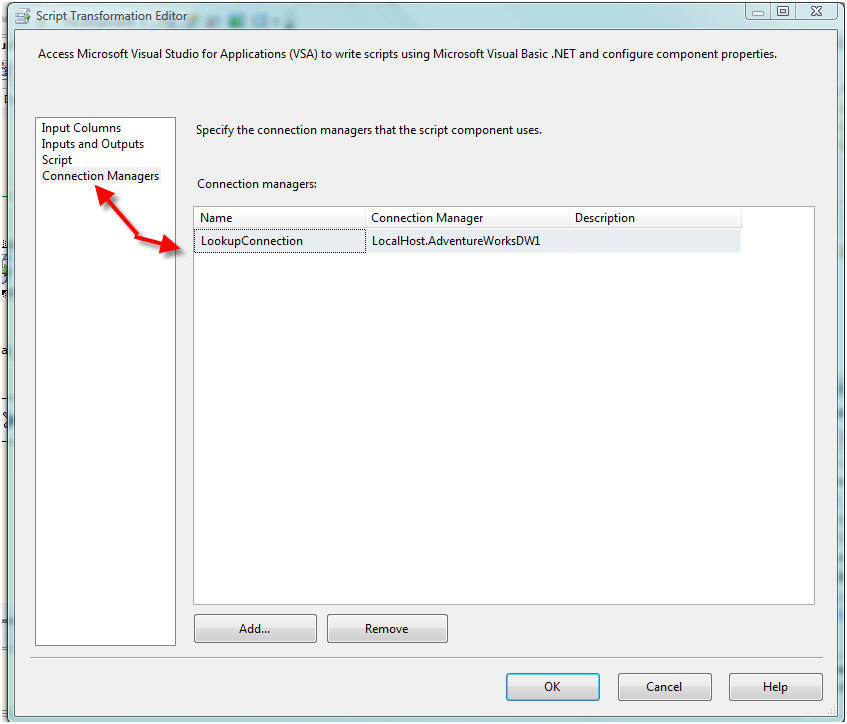
Now add a Connection Manager for the NameLookUp reference table.
Now let's create the script.
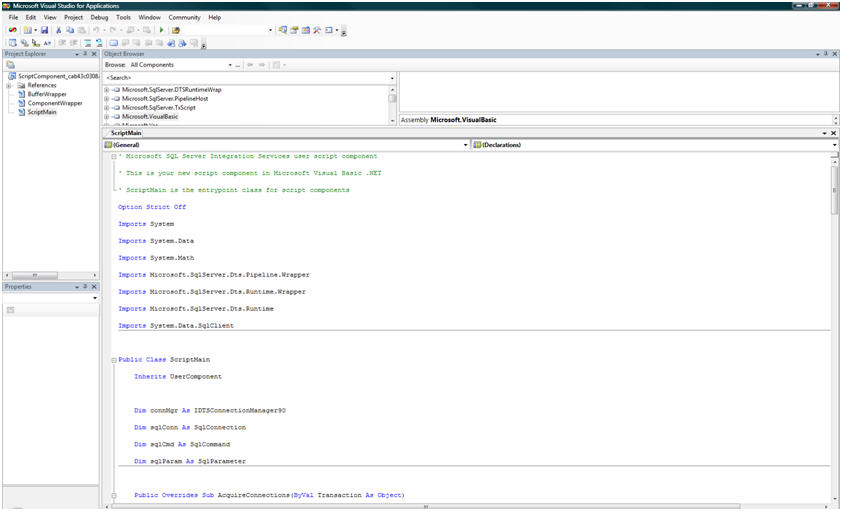
Here is the complete script
Option Strict Off
Imports System
Imports System.Data
Imports System.Math
Imports Microsoft.SqlServer.Dts.Pipeline.Wrapper
Imports Microsoft.SqlServer.Dts.Runtime.Wrapper
Imports Microsoft.SqlServer.Dts.Runtime
Imports System.Data.SqlClient
Public Class ScriptMain
Inherits UserComponent
Dim connMgr As IDTSConnectionManager90
Dim sqlConn As SqlConnection
Dim sqlCmd As SqlCommand
Dim sqlParam As SqlParameter
Public Overrides Sub AcquireConnections(ByVal Transaction As Object)
connMgr = Me.Connections.LookupConnection
sqlConn = CType(connMgr.AcquireConnection(Nothing), SqlConnection)
End Sub
Public Overrides Sub PreExecute()
sqlCmd = New SqlCommand("SELECT name_group_id ,first_name , first_name_normalized FROM NameLookup", sqlConn)
End Sub
Public Overrides Sub CustomerRecordsInput_ProcessInputRow(ByVal Row As CustomerRecordsInputBuffer)
Dim reader As SqlDataReader
Dim str1in As String
Dim str2in As String
reader = sqlCmd.ExecuteReader()
Do While reader.Read()
If jaro(Row.NameInput, (reader("First_Name"))) > 0.85 Then
'Explicitly add a row to the output buffer
MatchBuffer.AddRow()
'Add rows from the input buffer
MatchBuffer.NameInput = Row.NameInput
MatchBuffer.LastName = Row.LastName
MatchBuffer.FirstNameNormalized = (reader("first_name_normalized"))
MatchBuffer.CustId = Row.CustId
MatchBuffer.FirstName = (reader("first_name"))
MatchBuffer.NameGroupId = (reader("name_group_id"))
MatchBuffer.Score = jaro(Row.NameInput, (reader("First_Name")))
Else
If jaro(Row.NameInput, (reader("First_Name"))) > 0.75 Then
NearMatchBuffer.AddRow()
NearMatchBuffer.NameInput = Row.NameInput
NearMatchBuffer.LastName = Row.LastName
NearMatchBuffer.FirstNameNormalized = (reader("first_name_normalized"))
NearMatchBuffer.Custid = Row.CustId
NearMatchBuffer.FirstName = (reader("first_name"))
NearMatchBuffer.NameGroupId = (reader("name_group_id"))
NearMatchBuffer.Score = jaro(Row.NameInput, (reader("First_Name")))
Else
If jaro(Row.NameInput, (reader("First_Name"))) > 0 Then
NoMatchBuffer.AddRow()
NoMatchBuffer.NameInput = Row.NameInput
NoMatchBuffer.LastName = Row.LastName
NoMatchBuffer.FirstNameNormalized = (reader("first_name_normalized"))
NoMatchBuffer.CustId = Row.CustId
NoMatchBuffer.FirstName = (reader("first_name"))
NoMatchBuffer.NameGroupId = (reader("name_group_id"))
NoMatchBuffer.Score = jaro(Row.NameInput, (reader("First_Name")))
Else
NoMatchBuffer.AddRow()
NoMatchBuffer.NameInput = Row.NameInput
NoMatchBuffer.LastName = Row.LastName
NoMatchBuffer.FirstNameNormalized = (reader("first_name_normalized"))
NoMatchBuffer.CustId = Row.CustId
NoMatchBuffer.FirstName = (reader("first_name"))
NoMatchBuffer.NameGroupId = (reader("name_group_id"))
NoMatchBuffer.Score = jaro(Row.NameInput, (reader("First_Name")))
End If
End If
End If
Loop
reader.Close()
End Sub
Public Overrides Sub ReleaseConnections()
connMgr.ReleaseConnection(sqlConn)
End Sub
Function jaro(ByVal str1 As String, ByVal str2 As String) As Double
Dim l1, l2, lmin, lmax, aux, f, l, m, i, j As Integer
Dim common As Integer
Dim tr
Dim a1, auxstr, a2 As String
l1 = Len(str1)
l2 = Len(str2)
If l1 > l2 Then
aux = l2
l2 = l1
l1 = aux
auxstr = str1
str1 = str2
str2 = auxstr
End If
lmin = l1
lmax = l2
Dim f1(), f2() As Boolean
ReDim f1(l1), f2(l2)
For i = 1 To l1
f1(i) = False
Next i
For j = 1 To l2
f2(j) = False
Next j
m = CInt(Int((lmax / 2) - 1))
common = 0
tr = 0
For i = 1 To l1
a1 = Mid(str1, i, 1)
If m >= i Then
f = 1
l = i + m
Else
f = i - m
l = i + m
End If
If l > lmax Then
l = lmax
End If
For j = f To l
a2 = Mid(str2, j, 1)
If (a2 = a1) And (f2(j) = False) Then
common = common + 1
f1(i) = True
f2(j) = True
GoTo linea_exit
End If
Next j
linea_exit:
Next i
Dim wcd, wrd, wtr As Double
l = 1
For i = 1 To l1
If f1(i) Then
For j = l To l2
If f2(j) Then
l = j + 1
a1 = Mid(str1, i, 1)
a2 = Mid(str2, j, 1)
If a1 <> a2 Then
tr = tr + 0.5
End If
Exit For
End If
Next j
End If
Next i
wcd = 1 / 3
wrd = 1 / 3
wtr = 1 / 3
If common <> 0 Then
jaro = wcd * common / l1 + wrd * common / l2 + wtr * (common - tr) / common
End If
End Function
End ClassHighlights of the script
First for the Jaro-Winkler algorithm we have created a Function
Function jaro(ByVal str1 As String, ByVal str2 As String) As Double
Dim l1, l2, lmin, lmax, aux, f, l, m, i, j As Integer
Dim common As Integer
Dim tr
Dim a1, auxstr, a2 As String
l1 = Len(str1)
l2 = Len(str2)
If l1 > l2 Then
aux = l2
l2 = l1
l1 = aux
auxstr = str1
str1 = str2
str2 = auxstr
End If
lmin = l1
lmax = l2
Dim f1(), f2() As Boolean
ReDim f1(l1), f2(l2)
For i = 1 To l1
f1(i) = False
Next i
For j = 1 To l2
f2(j) = False
Next j
m = CInt(Int((lmax / 2) - 1))
common = 0
tr = 0
For i = 1 To l1
a1 = Mid(str1, i, 1)
If m >= i Then
f = 1
l = i + m
Else
f = i - m
l = i + m
End If
If l > lmax Then
l = lmax
End If
For j = f To l
a2 = Mid(str2, j, 1)
If (a2 = a1) And (f2(j) = False) Then
common = common + 1
f1(i) = True
f2(j) = True
GoTo linea_exit
End If
Next j
linea_exit:
Next i
Dim wcd, wrd, wtr As Double
l = 1
For i = 1 To l1
If f1(i) Then
For j = l To l2
If f2(j) Then
l = j + 1
a1 = Mid(str1, i, 1)
a2 = Mid(str2, j, 1)
If a1 <> a2 Then
tr = tr + 0.5
End If
Exit For
End If
Next j
End If
Next i
wcd = 1 / 3
wrd = 1 / 3
wtr = 1 / 3
If common <> 0 Then
jaro = wcd * common / l1 + wrd * common / l2 + wtr * (common - tr) / common
End If
End Function
Next we have created a connection to access our look up table
Dim sqlConn As SqlConnection
Dim sqlCmd As SqlCommand
Dim sqlParam As SqlParameter
Public Overrides Sub AcquireConnections(ByVal Transaction As Object)
connMgr = Me.Connections.LookupConnection
sqlConn = CType(connMgr.AcquireConnection(Nothing), SqlConnection)
End Sub
Public Overrides Sub PreExecute()
sqlCmd = New SqlCommand("SELECT name_group_id ,first_name , first_name_normalized FROM NameLookup", sqlConn)
End Sub
Finally we will process the pipeline
Public Overrides Sub CustomerRecordsInput_ProcessInputRow(ByVal Row As CustomerRecordsInputBuffer)
Dim reader As SqlDataReader
Dim str1in As String
Dim str2in As String
reader = sqlCmd.ExecuteReader()
Do While reader.Read()
If jaro(Row.NameInput, (reader("First_Name"))) > 0.85 Then
'Explicitly add a row to the output buffer
MatchBuffer.AddRow()
'Add rows from the input buffer
MatchBuffer.NameInput = Row.NameInput
MatchBuffer.LastName = Row.LastName
MatchBuffer.FirstNameNormalized = (reader("first_name_normalized"))
MatchBuffer.CustId = Row.CustId
MatchBuffer.FirstName = (reader("first_name"))
MatchBuffer.NameGroupId = (reader("name_group_id"))
MatchBuffer.Score = jaro(Row.NameInput, (reader("First_Name")))
Else
If jaro(Row.NameInput, (reader("First_Name"))) > 0.75 Then
NearMatchBuffer.AddRow()
NearMatchBuffer.NameInput = Row.NameInput
NearMatchBuffer.LastName = Row.LastName
NearMatchBuffer.FirstNameNormalized = (reader("first_name_normalized"))
NearMatchBuffer.Custid = Row.CustId
NearMatchBuffer.FirstName = (reader("first_name"))
NearMatchBuffer.NameGroupId = (reader("name_group_id"))
NearMatchBuffer.Score = jaro(Row.NameInput, (reader("First_Name")))
Else
If jaro(Row.NameInput, (reader("First_Name"))) > 0 Then
NoMatchBuffer.AddRow()
NoMatchBuffer.NameInput = Row.NameInput
NoMatchBuffer.LastName = Row.LastName
NoMatchBuffer.FirstNameNormalized = (reader("first_name_normalized"))
NoMatchBuffer.CustId = Row.CustId
NoMatchBuffer.FirstName = (reader("first_name"))
NoMatchBuffer.NameGroupId = (reader("name_group_id"))
NoMatchBuffer.Score = jaro(Row.NameInput, (reader("First_Name")))
Else
NoMatchBuffer.AddRow()
NoMatchBuffer.NameInput = Row.NameInput
NoMatchBuffer.LastName = Row.LastName
NoMatchBuffer.FirstNameNormalized = (reader("first_name_normalized"))
NoMatchBuffer.CustId = Row.CustId
NoMatchBuffer.FirstName = (reader("first_name"))
NoMatchBuffer.NameGroupId = (reader("name_group_id"))
NoMatchBuffer.Score = jaro(Row.NameInput, (reader("First_Name")))
End If
End If
End If
Loop
reader.Close()
End Sub
Running the Package
Now lets run the completed package using Data Viewers. For a quick tutorial on SSIS Data Viewers try JumpstartTV Using Data Viewers in SSIS by Brian Knight.
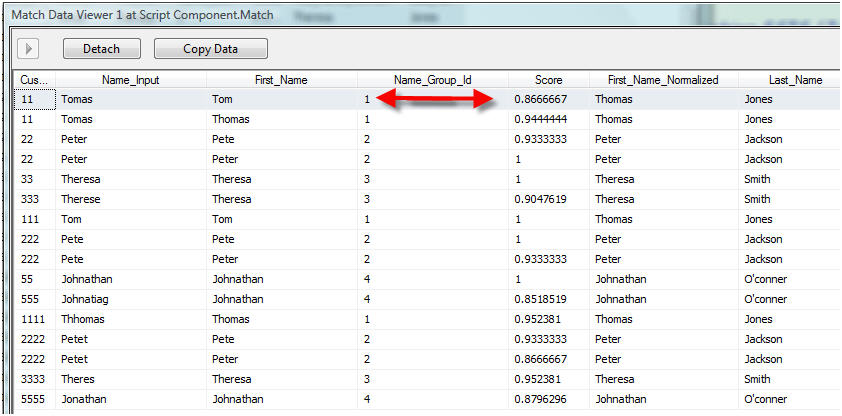
As you can see the record for Cust_Id 11 has two associated match records thta have a score over 95%.
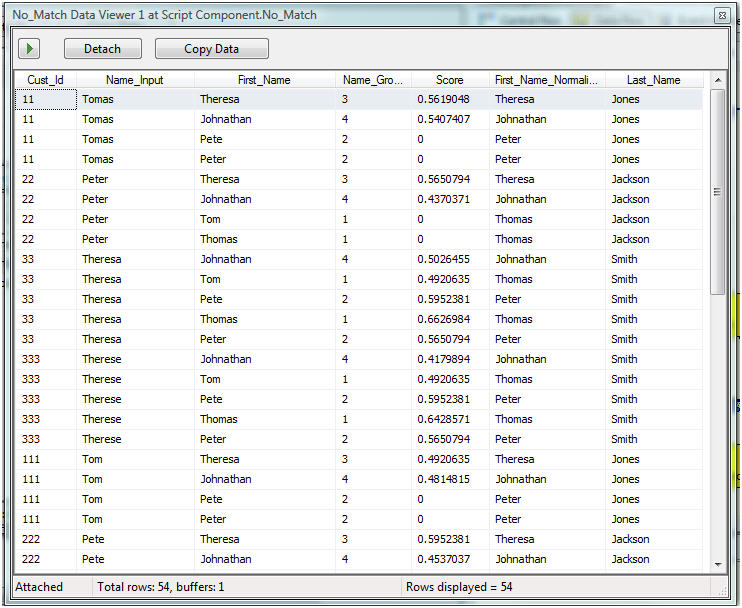
Here are the nomatch records thta had a score less than 75%.
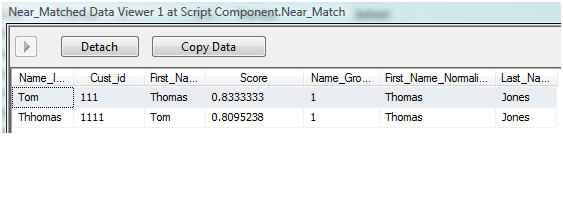
Near match records thta have a score over 85% and less than 95%.
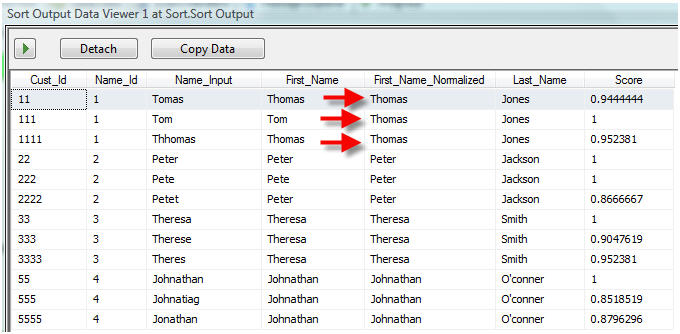
As you can see above the result of the Sort Component is to "Group" the records into a set containing the input records along with the Normalized names and NameId which effectively identifies similar records together.
We have demonstrated how to create a solution for matching or linking records using SSIS that will run and be deployable on any version of SQL Server 2005 or 2008 that supports SSIS.
The major enhancement we would make in order to create a more performant solution would be to add a separate index based on decomposing the algorithm components.
Ira Warren Whiteside
Actuality Business Intelligence
"karo yaa na karo, koshish jaisa kuch nahi hai"
"Do, or do not. There is no try."

